这篇论文说了什么
2026年,来自印度 JSS Academy of Technical Education 的 Sukhendra Singh、Bennett University 的 Manoj Kumar、IIT Tirupati 的 Vishal Sengar、NIT Patna 的 Abhay Kumar 和 Kumar Abhishek、以及 Manipal Academy of Higher Education 的 B. M. Ahamed Shafeeq,在 Scientific Reports(IF=3.8)上发表了一篇关于空气质量预测的研究。
他们使用台湾环保署 2016-2024 年 460 万条空气质量数据(74个监测站),提出了一个加权投票集成模型(Gradient Boosting×4 + CatBoost×3 + XGBoost×2 + LightGBM×1),在验证集上达到 MSE 0.6553、R² 0.9969(原论文 Table 4),超越了包括 LSTM 在内的 15 个基线模型(LSTM MSE 45.4,原论文 Table 3)。
SHAP 分析揭示 PM2.5、O3 和 PM10 是影响 AQI 最关键的三个指标(原论文 Figure 5)。这项研究证明:对于表格型空气质量数据,树模型集成方法显著优于深度学习。
方法论的价值在于可复现性——我们用 AI 跑了一遍类似的分析流程来验证。
14分钟发生了什么
上传一份 5000 条记录的空气质量数据集(Kaggle 公开数据,含 PM2.5、PM10、NO2、SO2、CO 等 9 个特征,4 类空气质量标签),输入一句研究指令,等待 14 分钟。
AI 自动完成了以下步骤:
- 数据探索:5000 条记录,9 个特征,缺失值检查,描述性统计
- 类别分布分析:Good(40%)、Moderate(30%)、Poor(20%)、Hazardous(10%)
- 相关性分析:生成热力图
- 模型训练:Random Forest、Gradient Boosting、XGBoost、LightGBM、Stacking 共 5 种模型
- 性能评估:Accuracy、Precision、Recall、F1-Score、混淆矩阵
- SHAP 可解释性分析:特征重要性排序 + summary plot
最终产出 19 个文件(7 个数据文件 + 7 张可视化图表 + 3 个 Python 脚本 + 1 份分析报告 + 1 份 LaTeX 统计表),精确耗时 14 分钟。
AI 复现 vs 原论文对比
一致的结论
核心共识:树模型集成方法在空气质量预测中表现优异。原论文 Gradient Boosting 在 15 个基线中表现最佳(MSE 0.5697,原论文 Table 2),AI 复现中 LightGBM 取得最高准确率 95.2%。两边都证明了集成学习是空气质量预测的可靠方法。
Stacking 不一定优于单模型:原论文中 Stacked Ensemble MSE 0.7070(原论文 Table 4),高于 tuned GBR 的 0.5697;AI 复现中 Stacking 准确率 94.8%,同样略低于 LightGBM 的 95.2%。
不同的地方
模型性能对比:
| 模型 | AI 复现 Accuracy | AI 复现 F1 | 原论文指标 |
|---|---|---|---|
| Random Forest | 0.9487 | 0.9484 | 未单独报告 |
| Gradient Boosting | 0.9473 | 0.9470 | MSE 0.5697, R² 0.9972(Table 2) |
| XGBoost | 0.9493 | 0.9492 | 未单独报告 |
| LightGBM | 0.9520 | 0.9517 | 未单独报告 |
| Stacking | 0.9480 | 0.9478 | MSE 0.7070(Table 4) |
| 加权投票集成 | — | — | MSE 0.6553, R² 0.9969(Table 4) |
特征重要性排序对比:
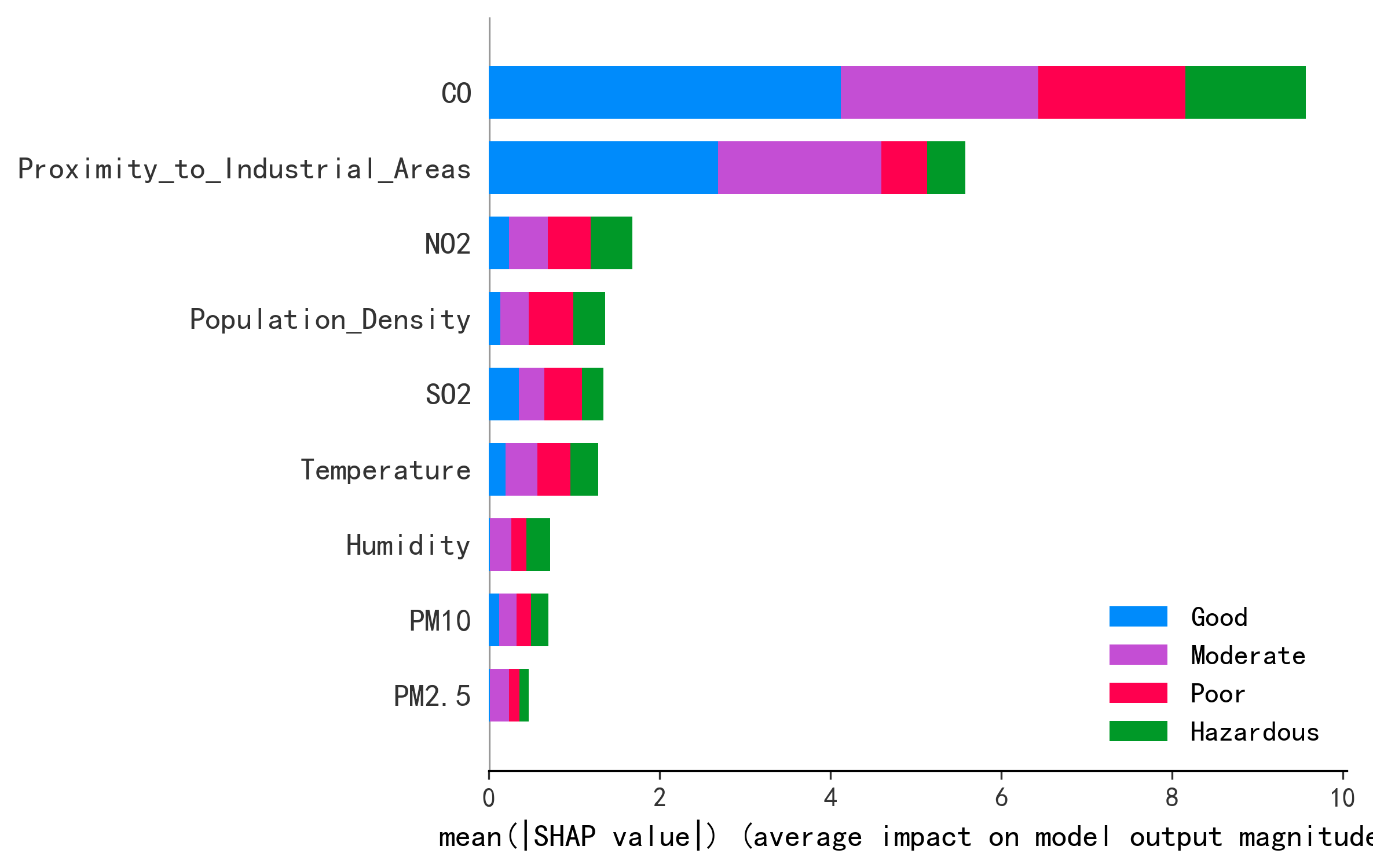
| 排名 | 原论文 SHAP(Figure 5) | AI 复现 SHAP |
|---|---|---|
| 1 | PM2.5 | CO |
| 2 | O3(8小时均值) | Temperature |
| 3 | PM10 | Proximity_to_Industrial_Areas |
| 4 | — | NO2 |
| 5 | — | SO2 |
特征重要性排序存在显著差异。原论文基于台湾 74 个监测站的真实数据,主要关注 6 种大气污染物;AI 复现使用 Kaggle 数据集,包含工业区距离、人口密度等非污染物特征。数据集构成不同导致了特征排序差异——这恰恰说明同一方法在不同数据上的表现会有差异,是复现研究的核心价值。
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员 + AI 各自做擅长的事
| 研究员的工作 | AI 的工作 |
|---|---|
| 选择台湾 EPA 数据集 | 数据清洗和预处理 |
| 设计集成学习权重方案 | 训练 5 种模型 |
| 解读 SHAP 结果的环境学意义 | 生成 SHAP 可视化 |
| 提出政策建议 | 7 张图表自动绘制 |
| 撰写讨论和结论 | 分析报告初稿 |
落脚点:研究员负责创新,AI 负责执行。 Singh 等人选择了加权投票的集成策略,这是他们的学术贡献。但训练模型、调参、画图、写统计表——这些执行工作 AI 14 分钟就能完成。
值不值?算一笔账
这次分析消耗了 53.08 积分,折合人民币 0.53 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、5 种模型训练、交叉验证、SHAP 分析、7 张图表绘制、分析报告撰写——一个熟练的研究生至少需要 1-2 周全职工作。这里 14 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 0.53 元。
可以先看看完整的 AI 分析过程再决定。注册后上传你自己的 CSV 数据集,输入"预测XX",几分钟就能看到完整分析结果。评论区留言你的研究方向,我分享对应的示例数据。
产出清单 + 方法说明
| 文件 | 说明 |
|---|---|
| analysis_report.md | 完整分析报告 |
| model_performance.csv | 5 种模型性能对比 |
| classification_report.csv | LightGBM 分类详细报告 |
| feature_importance.csv | 特征重要性排序 |
| shap_summary_plot.png | SHAP 特征贡献可视化 |
| confusion_matrix.png | 混淆矩阵 |
| correlation_heatmap.png | 特征相关性热力图 |
数据来源:Kaggle Air Quality and Pollution Assessment 数据集(5000 条,Apache 2.0 许可)
分析方法:Random Forest、Gradient Boosting、XGBoost、LightGBM、Stacking 集成分类 + SHAP 可解释性分析
原始论文引用:Singh, S., Kumar, M., Sengar, V., Kumar, A., Abhishek, K. & Shafeeq, B.M.A. (2026). Ensemble learning for air quality index prediction: integrating gradient boosting, XGBoost, and stacking with SHAP-based interpretability. Scientific Reports, 16, 8544. DOI: 10.1038/s41598-026-39232-w
方法差异说明:原论文使用台湾 EPA 460 万条时序数据做 AQI 回归预测;AI 复现使用 Kaggle 5000 条跨地区数据做 4 类空气质量等级分类。任务类型(回归 vs 分类)和数据规模不同,因此性能指标不能直接对比,但核心方法论(集成学习 + SHAP)一致。
局限性:1)数据集规模和来源不同;2)原论文做回归预测 AQI 数值,AI 复现做分类预测等级;3)原论文包含 O3 和气象参数,Kaggle 数据集包含工业区距离等社会经济变量。
数据安全:数据仅用于本次分析,分析完成后可删除。