复现目标
原论文:Singh, S., Kumar, M., Sengar, V., Kumar, A., Abhishek, K. & Shafeeq, B.M.A. (2026). Ensemble learning for air quality index prediction: integrating gradient boosting, XGBoost, and stacking with SHAP-based interpretability. Scientific Reports, 16, 8544. DOI: 10.1038/s41598-026-39232-w
作者机构:JSS Academy of Technical Education (Singh)、Bennett University (Kumar)、IIT Tirupati (Sengar)、NIT Patna (A. Kumar & Abhishek)、Manipal Academy of Higher Education (Shafeeq)
原论文数据集:台湾环保署 2016-2024 年数据,460 万条小时级记录,74 个监测站,6 种主要污染物(PM2.5、PM10、NO2、O3、SO2、CO)+ 气象参数
AI 复现数据集:Kaggle Air Quality and Pollution Assessment,5000 条记录,9 个特征(Temperature、Humidity、PM2.5、PM10、NO2、SO2、CO、Proximity_to_Industrial_Areas、Population_Density),目标变量为 4 类空气质量等级(Good/Moderate/Poor/Hazardous)
复现范围:
- ✅ 覆盖:集成学习建模(RF、GBR、XGBoost、LightGBM、Stacking)、SHAP 可解释性分析
- ❌ 未覆盖:加权投票集成(GBR:4 CatBoost:3 XGBoost:2 LightGBM:1)、时序验证、CatBoost 单模型、PDP 分析
方法差异:原论文做 AQI 数值回归预测,AI 复现做 4 类空气质量等级分类。指标体系不同(MSE/R² vs Accuracy/F1),不能直接数值对比,但方法论路径一致。
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 14 分钟(798 秒) |
| 产出文件数 | 19 个 |
| 数据集行数 | 5000 |
| 特征数 | 9 |
| 训练模型数 | 5 |
| 积分消耗 | 53.08 积分(¥0.53) |
复现结果对比
模型性能
由于任务类型不同(回归 vs 分类),以下仅做方法论层面的对比:
| 模型 | AI Accuracy | AI F1 | 原论文 MSE | 原论文 R² | 原论文来源 |
|---|---|---|---|---|---|
| Random Forest | 0.9487 | 0.9484 | 未单独报告 | 未单独报告 | — |
| Gradient Boosting | 0.9473 | 0.9470 | 0.5697 | 0.9972 | Table 2 |
| XGBoost | 0.9493 | 0.9492 | 未单独报告 | 未单独报告 | — |
| LightGBM | 0.9520 | 0.9517 | 未单独报告 | 未单独报告 | — |
| Stacking | 0.9480 | 0.9478 | 0.7070 | — | Table 4 |
| 加权投票集成 | 未复现 | 未复现 | 0.6553 | 0.9969 | Table 4 |
| LSTM | 未复现 | 未复现 | 45.4 | — | Table 3 |
观察:
- AI 复现中 LightGBM 表现最佳(F1=0.9517),与原论文中 Gradient Boosting 表现最佳的结论方向一致——都是梯度提升族模型领先
- Stacking 在两边都未超越最佳单模型:原论文 Stacking MSE 0.7070 > GBR MSE 0.5697(Table 4 vs Table 2);AI Stacking Acc 0.948 < LightGBM 0.952
- 原论文证明树模型远超 LSTM(MSE 差 ~80倍),AI 复现未测试深度学习基线
分类别准确率(AI 复现,LightGBM)
| 空气质量等级 | Precision | Recall | F1 | 样本数 |
|---|---|---|---|---|
| Good | 99.8% | 99.8% | 99.8% | 600 |
| Moderate | 95.9% | 97.8% | 96.8% | 450 |
| Poor | 88.3% | 88.3% | 88.3% | 300 |
| Hazardous | 87.9% | 82.7% | 85.2% | 150 |
Good 类几乎完美预测,Hazardous 类最难预测(F1=85.2%),与样本量不平衡(Good:Hazardous = 4:1)相关。
特征重要性排序对比
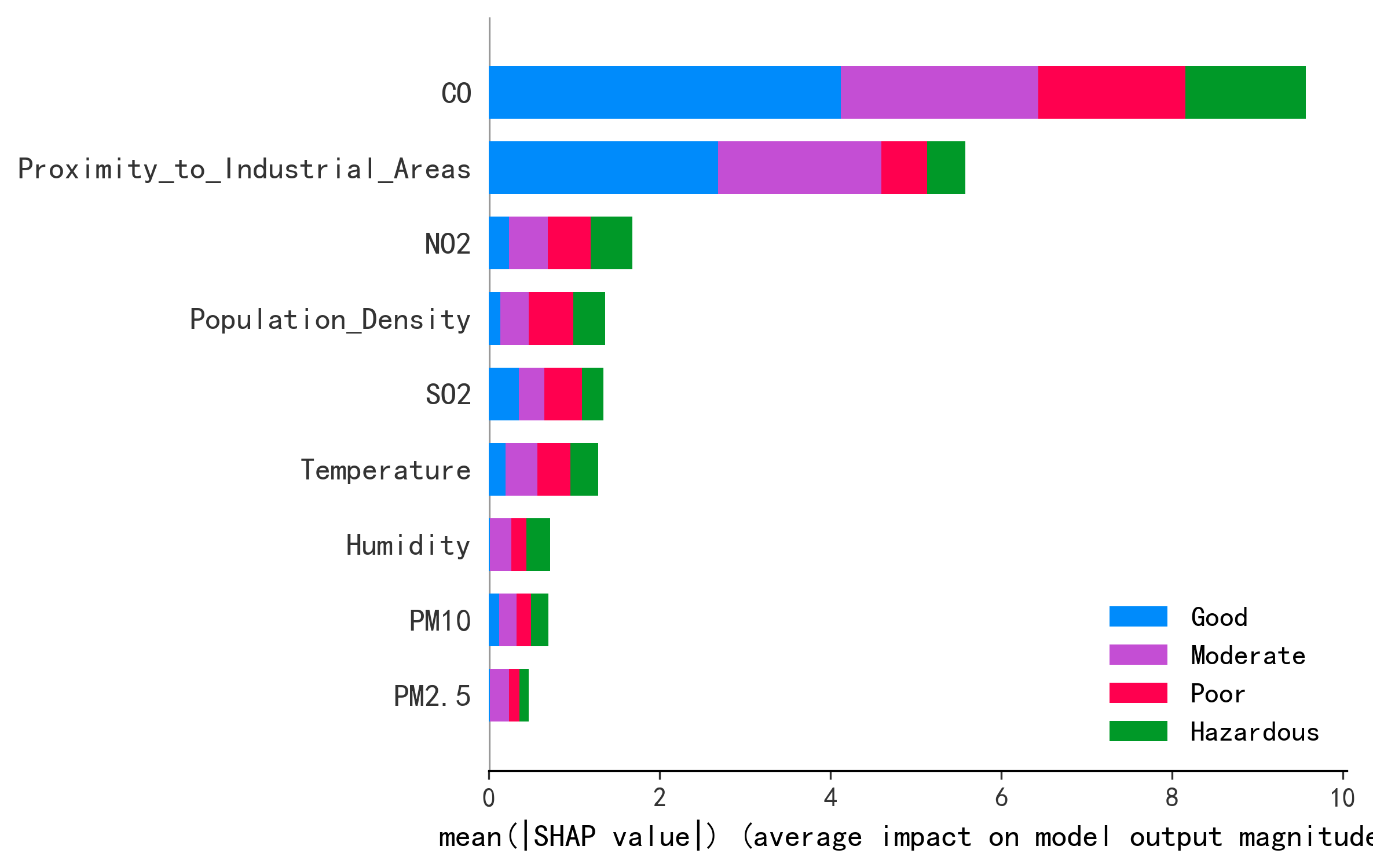
| 排名 | 原论文 SHAP Top 特征 | 来源 | AI 复现 SHAP Top 特征 | 重要性分数 |
|---|---|---|---|---|
| 1 | PM2.5 均值 | Figure 5 | CO | 2017 |
| 2 | O3 8小时均值 | Figure 5 | Temperature | 1559 |
| 3 | PM10 均值 | Figure 5 | Proximity_to_Industrial_Areas | 1545 |
| 4 | — | — | NO2 | 1413 |
| 5 | — | — | SO2 | 1325 |
| 6 | — | — | Humidity | 1274 |
| 7 | — | — | Population_Density | 1259 |
| 8 | — | — | PM10 | 810 |
| 9 | — | — | PM2.5 | 772 |
关键发现:特征重要性排序差异显著。原论文中 PM2.5 排名第一,AI 复现中 PM2.5 排名最末。原因分析:
- 数据集差异:原论文仅含 6 种污染物 + 气象参数,AI 数据集额外包含 Proximity_to_Industrial_Areas 和 Population_Density 等社会经济变量
- O3 缺失:Kaggle 数据集不含 O3(臭氧),而原论文中 O3 排名第二
- CO 浓度范围不同:两个数据集中 CO 的分布可能差异显著,导致其预测贡献不同
污染物单独排序(AI 复现,仅污染物特征)
| 排名 | 污染物 | 重要性 |
|---|---|---|
| 1 | CO | 2017 |
| 2 | NO2 | 1413 |
| 3 | SO2 | 1325 |
| 4 | PM10 | 810 |
| 5 | PM2.5 | 772 |
AI 做到了什么
- 14 分钟内完成 5 种集成学习模型的训练和评估
- 生成完整的 SHAP 可解释性分析(summary plot + 特征排序)
- 自动绘制 7 张可视化图表(混淆矩阵、相关性热力图、特征重要性等)
- 产出 LaTeX 可用的统计数据
- 最佳模型 LightGBM 达到 95.2% 准确率
AI 没做到什么
- 未复现加权投票集成:原论文核心贡献是 GBR:4 CatBoost:3 XGBoost:2 LightGBM:1 的特定权重方案,AI 仅用标准 Stacking
- 未包含 CatBoost:原论文 4 个基模型之一,AI 复现中缺失
- 未做时序验证:原论文使用 temporal validation(ΔR²=-0.0037),AI 仅用随机划分
- 未做 PDP 分析:原论文结合 SHAP + Partial Dependence Plots,AI 仅做 SHAP
- 任务类型不同:原论文是 AQI 回归预测,AI 做的是等级分类,无法直接对比性能数值
- 数据规模差异大:460 万条 vs 5000 条,原论文覆盖 8 年时序,AI 使用横截面数据
结论
本次复现验证了集成学习方法在空气质量预测中的有效性。核心方法论一致:树模型集成(尤其是梯度提升族)在表格型环境数据上表现优异,Stacking 不一定优于调优后的单模型。
特征重要性排序的显著差异(CO vs PM2.5 作为最强预测因子)提供了一个有价值的洞察:同一方法论在不同数据集、不同地理区域上可能产生不同的特征排序,这正是多地区复现研究的意义所在。
原论文提出的加权投票集成策略是其学术贡献,这部分需要研究者的专业判断来设计权重方案。AI 能够快速建立 baseline 并完成标准化分析流程,但方法创新仍然是研究者的专属领域。