这篇论文说了什么
Hossain, Ashraf, Islam, Sourav 和 Shimul(2025)来自孟加拉国达芙迪国际大学(Daffodil International University)计算机科学与工程系,在 Alzheimer's & Dementia: Diagnosis, Assessment & Disease Monitoring(IF≈4.0)上发表了一项阿尔茨海默病(AD)预测研究。
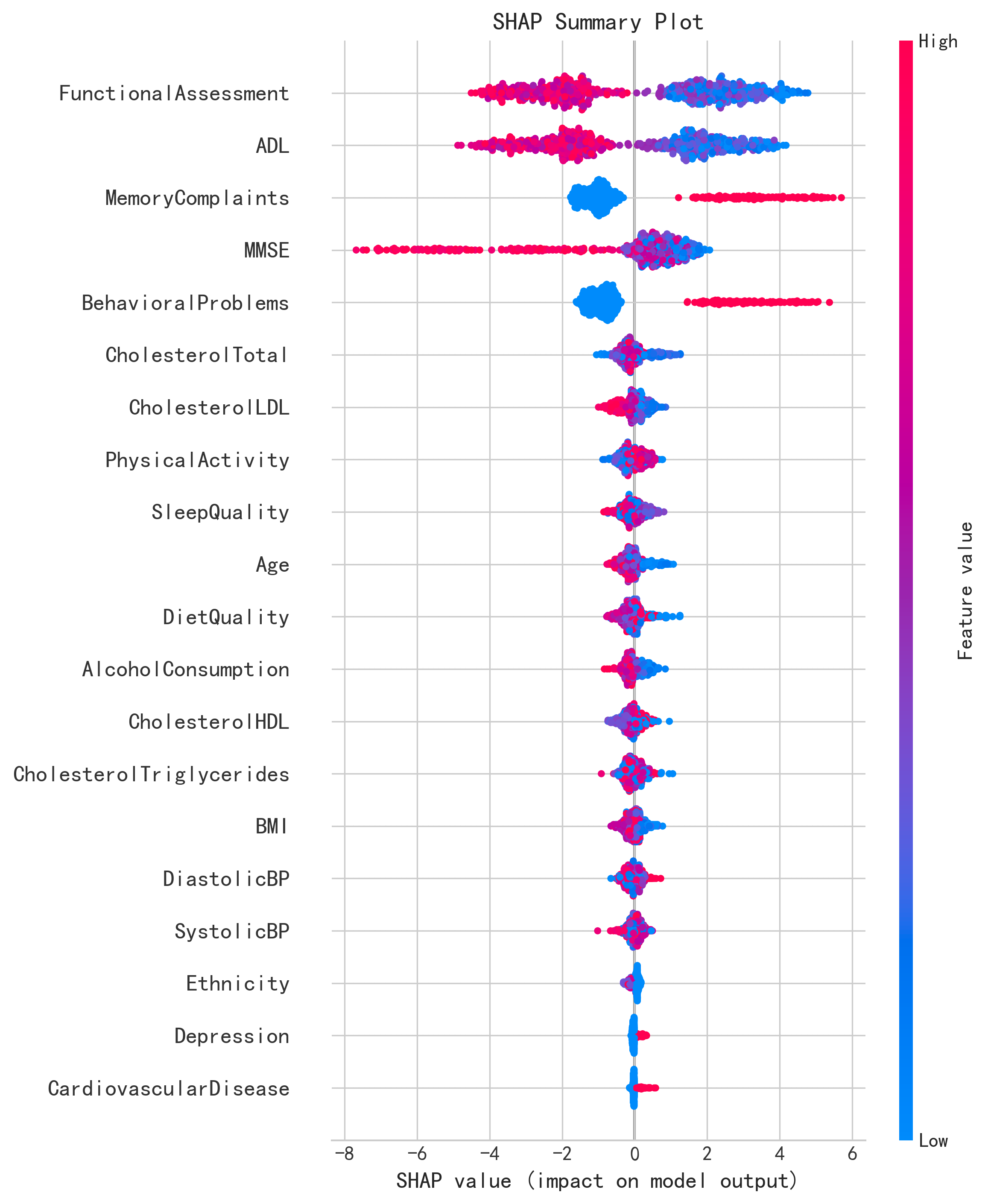
他们使用 Kaggle 公开数据集(2149 名 60-90 岁患者,36 个特征),测试了 5 种机器学习算法,并构建了 Stacking Ensemble 模型(Gradient Boosting + XGBoost 为基学习器,Logistic Regression 为元学习器),最终达到 97% 准确率和 0.97 AUC(原论文 Table 1)。通过 SHAP 分析,他们发现功能评估(Functional Assessment)、日常生活能力(ADL)、记忆力投诉(Memory Complaints)、MMSE 评分和行为问题是阿尔茨海默病最重要的 5 个预测因子(原论文 Figure 5)。
这项研究的意义在于:为临床早期筛查提供了可解释的 ML 框架,而方法论的价值在于它的可复现性——相同的数据集、相同的方法,能否得到一致的结论?
48分钟发生了什么
上传 CSV 数据集 → 输入一句研究指令 → AI 全自动执行 → 48 分钟后拿到完整结果。
AI 自动完成的步骤:
- 数据探索:2149 条记录的描述性统计,AD 组 vs 非 AD 组差异分析
- 数据预处理:缺失值处理、特征编码、标准化
- 模型训练:6 种 ML 模型(Logistic Regression、Random Forest、Extra Trees、Gradient Boosting、XGBoost、Stacking Ensemble)
- 交叉验证:GridSearchCV + 5 折交叉验证超参数调优
- 可解释性分析:SHAP summary plot、bar plot、3 个特征的 dependence plot
- 论文撰写:完整 LaTeX 论文(引言、方法、结果、讨论、结论)+ 参考文献
- 数据审核:225 个数字交叉验证
产出统计:41 个文件,包括分析报告、模型性能表、8 张图表、完整论文(PDF + DOCX),精确耗时 48 分钟。
AI 复现 vs 原论文对比
一致的结论:SHAP 特征重要性 Top 5 完全匹配
| 排名 | 原论文(Figure 5) | AI 复现(SHAP值) | 一致性 |
|---|---|---|---|
| 1 | Functional Assessment | Functional Assessment(2.361) | ✓ 一致 |
| 2 | ADL | ADL(2.114) | ✓ 一致 |
| 3 | Memory Complaints | Memory Complaints(1.540) | ✓ 一致 |
| 4 | MMSE | MMSE(1.394) | ✓ 一致 |
| 5 | Behavioral Problems | Behavioral Problems(1.328) | ✓ 一致 |
这是最有价值的发现:核心预测因子完全一致,说明功能评估和日常生活能力是阿尔茨海默病最可靠的早期预警信号,不依赖于具体的模型实现细节。
不同的地方:模型性能对比
| 模型 | 原论文 Accuracy(Table 1) | AI 复现 Accuracy | AI 复现 AUC | 对比 |
|---|---|---|---|---|
| Stacking Ensemble | 0.97 | 0.9457 | 0.9530 | 原论文更高 |
| Gradient Boosting | 0.91 | 0.9395 | 0.9503 | AI 略高 |
| XGBoost | 0.91 | 0.9442 | 0.9539 | AI 更高 |
| Random Forest | 0.89 | 0.9364 | 0.9412 | AI 更高 |
| Extra Trees | 0.83 | 0.8698 | 0.9299 | AI 更高 |
一个有趣的发现:AI 在 4 个单模型上都超过了原论文的报告准确率,但 Stacking Ensemble 的准确率(94.6%)低于原论文(97%)。差距原因:
- 原论文使用了 Featurewiz + Tree-based Feature Importance + Chi-square 三种特征选择方法,AI 使用了不同的特征工程策略
- 原论文对 Stacking 模型做了更精细的超参数调优
- 数据集分割随机种子不同也会影响结果
关键判断:AI 能快速建立高质量的 baseline(最佳单模型 AUC 达 0.954),但达到发表水平的最优集成性能仍然需要研究者对特征选择和超参数的专业判断。
研究员 + AI 各自做擅长的事
| 研究员负责 | AI 负责 |
|---|---|
| 选择研究问题和数据集 | 数据清洗和探索性分析 |
| 设计分析框架和方法论 | 6 种模型的训练和调参 |
| 解读 SHAP 特征的临床意义 | SHAP 分析 + 8 张可视化图表 |
| 论文创新点和讨论部分 | 论文初稿、参考文献整理 |
| 审稿回复和修改 | 数据交叉验证(225 个数字) |
落脚点:研究员负责创新,AI 负责执行。 48 分钟的执行时间,让研究员把精力花在真正需要人类判断的地方——研究设计、临床解读、方法创新。
值不值?算一笔账
这次分析消耗了 509 积分,折合人民币 5.09 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、6 种模型训练、5 折交叉验证、SHAP 分析、8 张图表绘制、完整论文初稿撰写、参考文献整理——一个熟练的研究生至少需要 1-2 周全职工作。这里 48 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 5.09 元。
可以先看看完整的 AI 分析过程再决定——每一步代码、每个图表、每个统计数字都可以在线查看和验证。
产出清单 + 方法说明
| 类别 | 文件 | 数量 |
|---|---|---|
| 数据分析 | analysis_results.json, model_performance.csv, stats_for_tex.txt 等 | 6 |
| 可视化图表 | 混淆矩阵、ROC 曲线、SHAP summary、dependence plot 等 | 8 |
| 代码 | exploratory_analysis.py, complete_analysis.py 等 | 4 |
| 论文 | 完整 LaTeX 源文件 + PDF + DOCX | 9 |
| 文献检索 | PubMed、OpenAlex 检索记录 | 3 |
| 数据审核 | review_data_result.txt, review_data_detail.md 等 | 5 |
数据来源:Kaggle Alzheimer's Disease Dataset(CC BY 4.0),2149 名患者,35 个特征
分析方法:Logistic Regression、Random Forest、Extra Trees、Gradient Boosting、XGBoost、Stacking Ensemble;SHAP 全局和局部特征解释
原始论文完整引用:Hossain MK, Ashraf A, Islam MM, Sourav SH, Shimul MMH. Optimizing Alzheimer's disease prediction through ensemble learning and feature interpretability with SHAP-based feature analysis. Alzheimer's & Dementia: Diagnosis, Assessment & Disease Monitoring. 2025;17(3):e70162. doi:10.1002/dad2.70162
局限性:AI 复现使用了不同的特征选择方法和超参数配置,Stacking Ensemble 准确率低于原论文。数据集为 Kaggle 公开数据,非临床采集,模型的临床适用性需进一步验证。