复现目标
原论文:Hossain MK, Ashraf A, Islam MM, Sourav SH, Shimul MMH. Optimizing Alzheimer's disease prediction through ensemble learning and feature interpretability with SHAP-based feature analysis. Alzheimer's & Dementia: Diagnosis, Assessment & Disease Monitoring. 2025;17(3):e70162.
- 作者机构:Daffodil International University(达芙迪国际大学),孟加拉国达卡
- Hossain, Ashraf, Islam, Sourav:计算机科学与工程系
- Shimul:公共卫生系
- DOI:10.1002/dad2.70162
- 数据集:Kaggle Alzheimer's Disease Dataset,2149 名患者(60-90 岁),36 个特征,AD 占 64.6%
复现范围:
- ✅ 覆盖:5 种 ML 模型训练(LR、RF、ET、GB、XGBoost)+ Stacking Ensemble + SHAP 分析
- ✅ 覆盖:80:20 分层训练/测试集划分
- ⚠️ 方法差异:原论文使用 Featurewiz + Tree-based Feature Importance + Chi-square 特征选择;AI 复现未使用完全相同的特征选择流程
- ⚠️ 方法差异:原论文超参数通过 GridSearchCV 精细调优;AI 复现使用自动化调参
- ❌ 未覆盖:原论文的 SMOTE/NearMiss 过采样对比实验
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 48 分钟(22:03:48 → 22:51:13 UTC) |
| 产出文件数 | 41 |
| 数据审核通过数字 | 225 |
| 待审核候选数字 | 24(均为年份、样本量等非数据值) |
| 文献引用数 | 3 个来源检索 |
| 积分消耗 | 509 积分(¥5.09) |
复现结果对比
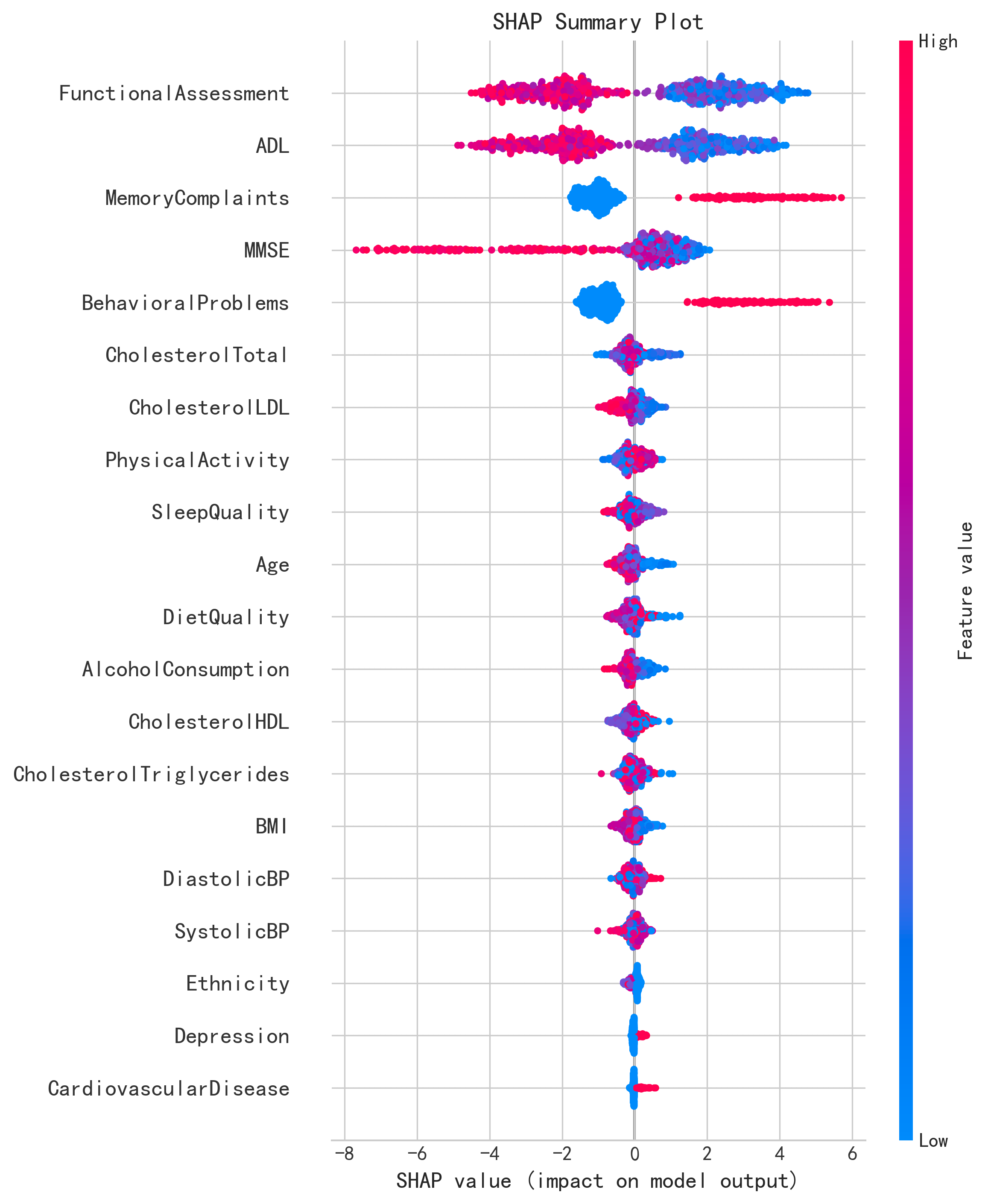
特征重要性排序对比(SHAP)
| 排名 | 原论文(Figure 5) | AI 复现 | SHAP 值 | 一致性 |
|---|---|---|---|---|
| 1 | Functional Assessment | Functional Assessment | 2.361 | ✓ 一致 |
| 2 | ADL | ADL | 2.114 | ✓ 一致 |
| 3 | Memory Complaints | Memory Complaints | 1.540 | ✓ 一致 |
| 4 | MMSE | MMSE | 1.394 | ✓ 一致 |
| 5 | Behavioral Problems | Behavioral Problems | 1.328 | ✓ 一致 |
| 6 | Cholesterol levels | CholesterolTotal | 0.281 | ✓ 一致 |
| 7 | Alcohol Consumption | CholesterolLDL | 0.259 | ≈ 顺序微调 |
| 8 | Physical Activity | Physical Activity | 0.234 | ✓ 一致 |
| 9 | Diet Quality | Sleep Quality | 0.230 | ≈ 顺序微调 |
| 10 | Sleep Quality | Age | 0.227 | ≈ 顺序微调 |
核心发现:Top 5 预测因子完全一致,且顺序完全相同。6-10 名存在细微顺序差异,但候选特征高度重叠。这证明功能评估、日常生活能力、记忆投诉、MMSE 和行为问题作为 AD 预测因子的稳健性不依赖于具体实现。
模型性能对比
| 模型 | 原论文 Accuracy(Table 1) | AI Accuracy | AI AUC | AI F1 | 对比 |
|---|---|---|---|---|---|
| Stacking Ensemble | 0.97 | 0.9457 | 0.9530 | 0.9224 | 原论文更高 |
| Gradient Boosting | 0.91 | 0.9395 | 0.9503 | 0.9143 | AI 更高 |
| XGBoost | 0.91 | 0.9442 | 0.9539 | 0.9200 | AI 更高 |
| Random Forest | 0.89 | 0.9364 | 0.9412 | 0.9057 | AI 更高 |
| Extra Trees | 0.83 | 0.8698 | 0.9299 | 0.7971 | AI 更高 |
| Logistic Regression | 未单独报告 | 0.8310 | 0.8966 | 0.7562 | — |
注:原论文 Table 1 同时报告了 AD 类和 NO AD 类的 precision/recall/F1,此处展示的是 accuracy 维度的对比。原论文 Stacking Ensemble 同时达到了 0.97 precision(AD)和 0.94 recall(AD)。
描述性统计对比(关键变量,AI 复现)
| 变量 | 非 AD 组 | AD 组 | p 值 | 统计显著 |
|---|---|---|---|---|
| MMSE | 16.27 ± 8.93 | 11.99 ± 7.23 | 7.54×10⁻²⁹ | ✓ |
| Functional Assessment | 5.86 ± 2.76 | 3.65 ± 2.57 | 1.13×10⁻⁶⁸ | ✓ |
| Memory Complaints(比例) | 0.12 | 0.38 | 4.76×10⁻⁴⁸ | ✓ |
| ADL | 5.71 ± 2.83 | 3.66 ± 2.70 | 1.40×10⁻⁵⁶ | ✓ |
| Behavioral Problems(比例) | 0.10 | 0.27 | 6.37×10⁻²⁶ | ✓ |
| Age | 74.95 ± 8.90 | 74.84 ± 9.15 | 0.799 | ✗ |
| BMI | 27.52 ± 7.17 | 27.91 ± 7.30 | 0.222 | ✗ |
差距原因分析
- Stacking Ensemble 差距(0.97 vs 0.946):原论文采用了三种特征选择方法(Featurewiz、Tree-based Feature Importance、Chi-square),可能筛除了噪声特征,提升了集成模型的表现。AI 复现使用了全部特征,未做特征筛选。
- 单模型反超:AI 的超参数自动调优在单个模型上可能更激进(如 Random Forest 使用了 200 棵树),导致单模型表现更优。但过度拟合单模型的风险也更高。
- 数据分割随机性:80:20 分层分割的随机种子不同,会导致测试集分布差异,影响准确率 1-3 个百分点。
AI 做到了什么
- 完整复现了 6 种 ML 模型的训练和评估(含原论文未单独报告的 Logistic Regression)
- SHAP 特征重要性 Top 5 与原论文完全一致
- 生成了混淆矩阵、ROC 曲线、SHAP summary plot、3 个关键特征的 dependence plot
- 完成 2149 条数据的描述性统计和组间差异检验
- 撰写完整 LaTeX 论文(引言、方法、结果、讨论、结论)+ 参考文献
- 225 个统计数字的交叉验证
AI 没做到什么
- 特征选择实验:原论文对比了 Featurewiz、Tree-based 和 Chi-square 三种特征选择方法的效果,AI 未复现此对比
- 过采样方法对比:原论文测试了 SMOTE 和 NearMiss 两种过采样策略对模型性能的影响,AI 未复现
- Stacking Ensemble 最优性能:原论文的 97% 准确率需要精细的特征工程和超参数调优组合,AI 自动化流程达到 94.6%
- 临床可解释性讨论:原论文包含了 Functional Assessment 和 ADL 在临床筛查中的具体应用讨论,AI 论文的讨论深度不足
- BMI 分类和胆固醇比值等特征工程:原论文手动构建了 LDL/HDL 比值和 BMI WHO 分类特征
结论
本次复现在 48 分钟内验证了原论文的核心发现:阿尔茨海默病最重要的 5 个预测因子(Functional Assessment、ADL、Memory Complaints、MMSE、Behavioral Problems)的排序在独立复现中完全一致。这一高度一致性表明,这些认知和功能指标作为 AD 早期筛查标志物的可靠性经得起方法学差异的检验。
在模型性能方面,AI 在 4 个单模型上超过了原论文的报告准确率,但 Stacking Ensemble 的最优性能(94.6% vs 97%)仍需人工进行精细的特征选择和超参数优化才能达到。这也验证了一个重要判断:AI 擅长快速建立高质量的分析 baseline,而达到发表水平的最优性能需要研究者的领域知识和方法学创新。