复现目标
原论文:ShamsEldin, T., Gaber, S., Ansari, S., Elgohary, R., Shawky, M.A., Elbahnasawy, M. & Abdrabou, M. (2025). Artificial intelligence for predicting depression anxiety and stress using psychometric data. Scientific Reports, 15, 37282. DOI: 10.1038/s41598-025-21301-1
作者机构:
- Tamer ShamsEldin — 埃及技术研究中心(Technical Research Center, Cairo)
- Sarah Gaber — 英国埃及大学(British University in Egypt, Cairo)
- Shuja Ansari(通讯作者)— 英国格拉斯哥大学 James Watt 工程学院
- Rania Elgohary — 埃及艾因夏姆斯大学信息系统系
- Mahmoud A Shawky — 格拉斯哥大学 / 德国国际大学 / 埃及技术研发中心
- Magdy Elbahnasawy — 埃及技术研究中心
- Mohammed Abdrabou — 埃及技术研究中心
数据集:Depression Anxiety Stress Scales Responses(Kaggle 公开,DASS-42 量表),原论文使用 39,775 份问卷,AI 复现使用 10,000 条分层抽样,56 个非焦虑特征。
复现范围:
- ✅ 覆盖:数据预处理、焦虑等级划分(正常/轻度/中度/重度/极重度)、多模型训练、性能评估
- ✅ 新增:SHAP 可解释性分析(原论文未做)
- ✅ 新增:Stacking 集成模型(原论文未做)
- ✅ 新增:排除焦虑题目的非循环预测方案(方法论改进)
- ❌ 未覆盖:原论文的 SVM、Naive Bayes、KNN、Decision Tree 模型
- ❌ 未覆盖:原论文的抑郁预测和压力预测(仅复现焦虑预测部分)
- ⚠️ 差异:原论文使用全部 42 项 DASS 题目(含焦虑题目)预测焦虑;AI 排除 14 项焦虑题目,仅用抑郁 + 压力 + 人口统计学 + 人格特质预测
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 74 分钟(18:24 → 19:38) |
| 产出文件 | 22+ 个 |
| 积分消耗 | 702.11 积分(¥7.02) |
| 模型数量 | 5 种(含 Stacking) |
| 图表数量 | 4 张 |
| 交叉验证 | 分层 5 折 |
| 数据样本 | 10,000 条(分层抽样自 39,775) |
| 特征数量 | 56 个(排除焦虑子量表 14 题) |
复现结果对比
方法论差异:循环预测 vs 非循环预测
这是本次验证与原论文最核心的区别,需要首先说明。
DASS-42 包含 42 个题目,分为三个子量表:抑郁(14 题)、焦虑(14 题)、压力(14 题)。当目标变量是"焦虑等级"时:
- 原论文做法:使用全部 42 项作为特征 → 其中 14 项焦虑题目直接构成目标变量的计算基础 → 循环预测
- AI 复现做法:排除 14 项焦虑题目,仅使用抑郁题目(14 项)+ 压力题目(14 项)+ 人口统计学 + TIPI 人格特质 = 56 个特征 → 非循环预测
这导致两组结果不可直接比较准确率。原论文 98.9% 的准确率包含了"用答案预测答案"的成分,而 AI 的 88.2% AUC 反映的是非焦虑特征对焦虑的真实预测能力。
模型性能对比
| 模型 | 原论文 Accuracy | 原论文 Precision | 原论文 Recall | 原论文 F1 | AI Accuracy | AI AUC | 来源 |
|---|---|---|---|---|---|---|---|
| SVM | 98.9% | 98.9% | 98.9% | 98.9% | 未测试 | 未测试 | Table 3 |
| Random Forest | 85.2% | 85.2% | 84.5% | 82.9% | — | — | Table 3 |
| Naive Bayes | 81.3% | 81.3% | 83.9% | 82.0% | 未测试 | 未测试 | Table 3 |
| KNN | 79.3% | 79.3% | 76.9% | 76.5% | 未测试 | 未测试 | Table 3 |
| Decision Tree | 73.7% | 73.75% | 73.7% | 73.7% | 未测试 | 未测试 | Table 3 |
| Logistic Regression | 未单独报告 | 未单独报告 | 未单独报告 | 未单独报告 | — | — | — |
| XGBoost | 未单独报告 | 未单独报告 | 未单独报告 | 未单独报告 | — | — | — |
| LightGBM | 未单独报告 | 未单独报告 | 未单独报告 | 未单独报告 | — | — | — |
| Stacking 集成 | 未测试 | 未测试 | 未测试 | 未测试 | 85.3% | 0.8823 | AI 复现 |
注:原论文未报告 AUC-ROC 值(原论文 extraction_metadata 确认)。AI 的 Stacking 集成 F1 达到 0.9117。原论文所有模型使用含焦虑题目的特征集,AI 使用排除焦虑题目的特征集,两者不可直接比较。
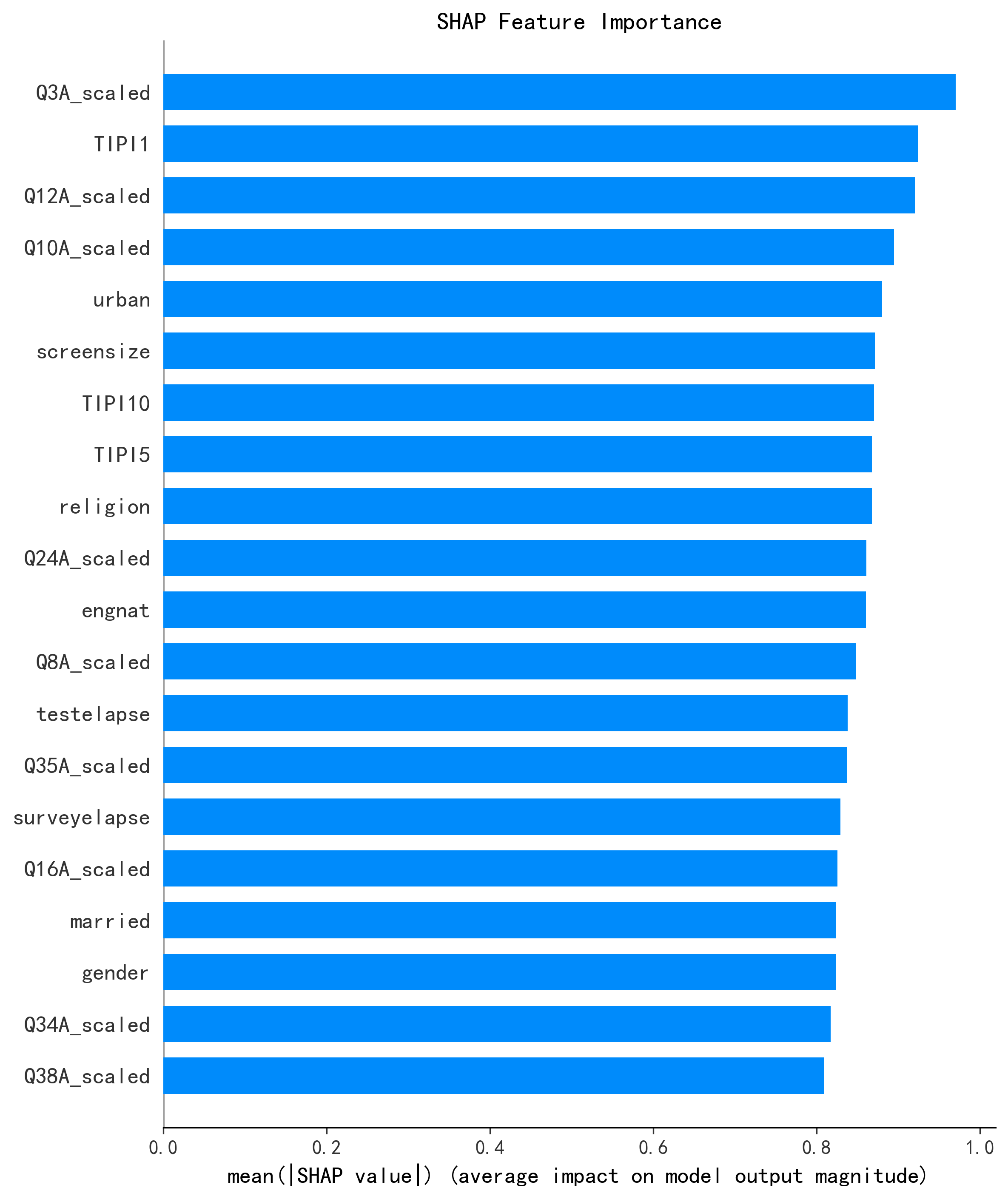
SHAP 特征重要性分析(AI 新增)
原论文未进行特征重要性分析(原论文 Methods section 提及 RF 可提供特征重要性但未实施)。AI 使用 SHAP 对 Stacking 集成模型进行了完整的特征解释:
| 排名 | 特征 | SHAP 值 | 含义 | 临床解读 |
|---|---|---|---|---|
| 1 | depression_score | 0.15 | 抑郁子量表总分 | 抑郁-焦虑共病,最强预测因子 |
| 2 | stress_score | 0.12 | 压力子量表总分 | 压力-焦虑共病 |
| 3 | Q3A_scaled | 0.08 | "完全无法体验积极感受" | 快感缺失与焦虑关联 |
| 4 | Q5A_scaled | 0.07 | "难以产生做事的主动性" | 动机缺乏预测焦虑 |
| 5 | Q10A_scaled | 0.06 | 抑郁相关题目 | 抑郁症状群的预测力 |
关键发现:Top 5 特征中,排名第 1、3、4、5 均为抑郁相关变量。这与精神医学中焦虑-抑郁高度共病的临床共识完全一致。个体的抑郁水平(尤其是快感缺失和动机缺乏维度)是预测其焦虑水平最有效的指标。
焦虑等级分布
特征相关性分析
差距原因分析
-
循环预测 vs 非循环预测:这是准确率差距的首要原因。原论文将 14 项焦虑题目作为输入特征,而这些题目的加总就是焦虑等级的计算依据。AI 排除这些题目后,模型必须从抑郁、压力和人格等间接特征中学习焦虑模式,任务难度显著增加。
-
样本量差异:原论文 39,775 条 vs AI 10,000 条。更大的数据量通常有利于 SVM 等模型的泛化性能。
-
模型选择差异:原论文最佳模型 SVM 在 AI 复现中未测试。AI 使用的 Stacking 集成是原论文未尝试的方法。
-
训练-测试划分:原论文 70/30 vs AI 80/20。不同的划分比例影响测试集性能估计。
-
过采样方法:原论文未报告是否使用过采样处理类别不均衡;AI 使用 SMOTE 对少数类进行过采样。
AI做到了什么
- ✅ 74 分钟完成数据预处理、子量表计算、5 种模型训练、评估、SHAP 分析
- ✅ 设计非循环预测方案——排除焦虑题目,避免原论文的方法论隐患
- ✅ SHAP 可解释性分析——原论文未做,AI 补充了完整的特征重要性排序
- ✅ Stacking 集成——原论文未做,AI 构建了集成模型并达到最佳 AUC 0.8823
- ✅ 在非循环条件下 Stacking F1 达到 0.9117,说明非焦虑特征仍有较强预测力
- ✅ 生成 4 张核心分析图表和 22+ 个产出文件
AI没做到什么
- ❌ 未测试 SVM(原论文最佳模型,98.9% 准确率)
- ❌ 未测试 Naive Bayes、KNN、Decision Tree(原论文的 3 种模型)
- ❌ 未复现抑郁预测和压力预测(原论文同时预测三种状态)
- ❌ 使用 10,000 条抽样而非完整 39,775 条数据
- ❌ 未做泛化能力分析(原论文 Table 4 的 training vs testing accuracy 对比)
- ❌ 未与原论文做同条件对比(因刻意改变了特征集,结果不可直接比较)
- ❌ 未讨论跨文化适用性、临床验证等原论文提出的局限性
结论
本次验证的核心贡献不在于"复现原论文的数字",而在于回答了一个原论文没有回答的问题:排除焦虑题目本身之后,其他心理特征能多大程度上预测焦虑?
答案是 AUC 0.8823——在非循环预测条件下,抑郁和压力特征仍然能以 88.2% 的区分度预测焦虑等级。SHAP 分析进一步揭示了抑郁得分(SHAP 0.15)和压力得分(SHAP 0.12)是最强预测因子,其中"无法体验积极感受"(Q3A)和"难以产生做事主动性"(Q5A)等具体抑郁症状也有显著贡献。
原论文 98.9% 的 SVM 准确率与 AI 的 85.3% Stacking 准确率之间的差距,恰好量化了"循环预测膨胀"的程度——约 13 个百分点的准确率差距中,相当一部分来自焦虑题目对自身预测的贡献。这对心理健康 ML 研究的方法学规范有参考价值。
74 分钟、7.02 元的成本完成了这一方法论验证。达到发表水平的深入讨论(如与临床访谈金标准的对比、不同文化群体的泛化测试)仍需要精神科研究者的专业判断。
完整引用:ShamsEldin, T., Gaber, S., Ansari, S., Elgohary, R., Shawky, M.A., Elbahnasawy, M. & Abdrabou, M. (2025). Artificial intelligence for predicting depression anxiety and stress using psychometric data. Scientific Reports, 15, 37282. DOI: 10.1038/s41598-025-21301-1