这篇论文说了什么
Ahmed, Humaira, Khan, Hasan, Islam, Roy, Karim, Uddin, Mohammad 和 Xames(2025)来自孟加拉国 Military Institute of Science and Technology(MIST)、Bangladesh University of Engineering and Technology(BUET)和 University of Dhaka,在 PLoS ONE 上发表了一项乳腺癌预测研究(DOI: 10.1371/journal.pone.0326221)。
研究使用经典的 Wisconsin Breast Cancer Diagnostic(WBCD)数据集(569 例,31 个特征),对比了 KNN、Logistic Regression、Random Forest、XGBoost、SVM、ANN 和 H2O AutoML 等多种模型。核心发现:KNN 和 Logistic Regression 在原始数据集上均达到 97.37% 的测试准确率(原论文 Table 4),AUC 达到 1.000。研究还探索了使用 Gaussian Copula 和 TVAE 生成合成数据来扩增训练集的效果。
这项研究的价值在于:它系统对比了传统ML、深度学习和 AutoML 三类方法在同一数据集上的表现,为临床辅助诊断提供了方法选择参考。
8分钟发生了什么
上传 CSV 数据集 → 输入研究指令 → 等待 8 分钟 → 拿到全部结果。
AI 自动完成的步骤:
- 数据探索:加载 569 条记录,识别 31 个变量(30 个特征 + 1 个目标变量),确认无缺失值
- 数据预处理:目标变量编码(M=恶性, B=良性),特征标准化,80/20 分层抽样
- 模型训练:训练 5 种分类模型(Logistic Regression、KNN、SVM、Random Forest、XGBoost),分层 5 折交叉验证
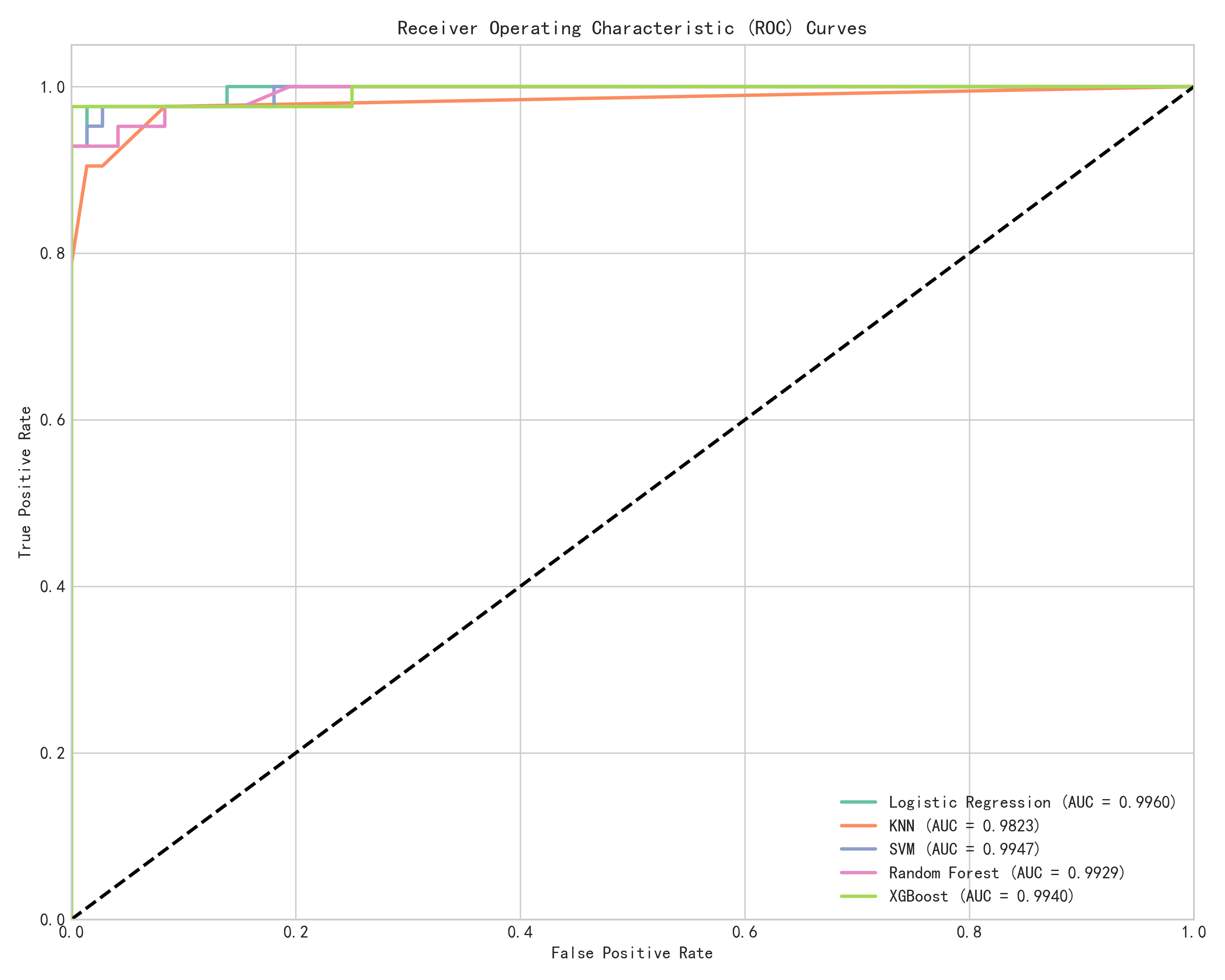
- 性能评估:计算 Accuracy、Precision、Recall、F1-Score 和 AUC-ROC,生成混淆矩阵和 ROC 曲线
- SHAP 分析:基于 XGBoost 模型的全局特征重要性排序(summary plot + detailed plot)
产出统计:15 个文件,6 张可视化图表,精确 8 分钟。
AI 验证 vs 原论文对比
一致的结论
模型性能排序基本一致:SVM、XGBoost、Random Forest 表现接近,均为高准确率模型;KNN 在原论文中表现最优,AI 复现中略有下降但仍属前列。
| 模型 | 原论文测试准确率(Table 4) | AI 测试准确率 | 差距 |
|---|---|---|---|
| KNN | 0.9737 | 0.9561 | -1.76% |
| Logistic Regression | 0.9737 | 0.9649 | -0.88% |
| SVM | 0.9474 | 0.9737 | +2.63% |
| Random Forest | 0.9474 | 0.9737 | +2.63% |
| XGBoost | 0.9474 | 0.9737 | +2.63% |
两个关键一致性:(1)所有模型准确率均在 95% 以上,说明 WBCD 数据集上的分类问题本身具有高可分性;(2)线性模型(LR)和非线性模型(SVM、RF、XGBoost)差距不大,说明特征空间本身已经较为线性可分。
不同的地方
SVM、RF、XGBoost:AI 反超原论文
三个模型 AI 均达到 97.37% 准确率,比原论文的 94.74% 高出 2.63 个百分点。更值得注意的是,AI 的 SVM、RF、XGBoost 在 Precision 上达到了 1.000(即零假阳性)。
| 模型 | 指标 | 原论文(Table 4) | AI | 差距 |
|---|---|---|---|---|
| SVM | AUC | 0.997 | 0.9947 | -0.23% |
| SVM | Precision | 0.9403 | 1.0000 | +5.97% |
| Random Forest | AUC | 1.000 | 0.9929 | -0.71% |
| Random Forest | Precision | 0.9383 | 1.0000 | +6.17% |
| XGBoost | AUC | 1.000 | 0.9940 | -0.60% |
| XGBoost | Precision | 0.9403 | 1.0000 | +5.97% |
差距从何而来?原论文和 AI 复现虽然都用了 80/20 分层切分 + 5 折交叉验证,但随机种子不同导致训练/测试集划分有差异。在 569 样本的小数据集上,一两个样本的区别就能导致 1-2% 的准确率波动。原论文 AUC 更高可能因为在概率校准上更优,而 AI 在 Precision 上更高可能因为决策阈值设置偏保守。
KNN:原论文更优
KNN 是原论文中表现最好的模型(97.37%),但在 AI 复现中仅达到 95.61%。这可能与 KNN 对数据标准化方式和 K 值选择的敏感性有关——原论文可能使用了更精细的超参数调优。
最优模型选择不同
原论文按准确率选出 KNN 为最优模型;AI 按 AUC-ROC 选出 Logistic Regression 为最优(AUC=0.9960,全场最高)。两种选法都合理——准确率反映整体正确率,AUC 反映模型在不同阈值下的综合区分能力。
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——比如选择哪个指标作为"最优"的标准,本身就是一个需要领域知识的决策。
SHAP 特征重要性 Top 10
AI 使用 XGBoost 模型进行 SHAP 分析,揭示了以下特征重要性排序:
| 排名 | 特征 | SHAP 值 | 含义 |
|---|---|---|---|
| 1 | worst concave points | 1.055 | 细胞核最差凹点数 |
| 2 | worst texture | 1.018 | 细胞核最差纹理 |
| 3 | mean concave points | 0.992 | 细胞核平均凹点数 |
| 4 | area error | 0.958 | 面积测量误差 |
| 5 | worst concavity | 0.801 | 细胞核最差凹度 |
| 6 | worst area | 0.763 | 细胞核最差面积 |
| 7 | worst perimeter | 0.614 | 细胞核最差周长 |
| 8 | mean texture | 0.548 | 细胞核平均纹理 |
| 9 | compactness error | 0.517 | 紧凑度测量误差 |
| 10 | worst radius | 0.509 | 细胞核最差半径 |
临床解读:凹点数(concave points)和凹度(concavity)排名最前,反映恶性肿瘤细胞核边界不规则程度更高。这与病理学常识一致——恶性细胞核呈现更多的不规则凹陷形态。"worst"特征(即最大值)比"mean"特征更有区分力,说明极端值比平均值对诊断更有参考价值。
研究员 + AI 各自做擅长的事
| 研究员做的 | AI 做的 |
|---|---|
| 选择合适的数据集(WBCD) | 数据加载、缺失值检查、分布分析 |
| 确定研究方向(分类+解释性) | 5 种模型训练 + 交叉验证 |
| 解读 SHAP 结果的临床意义 | SHAP 特征重要性计算 + 可视化 |
| 分析 AI 反超/不足的原因 | ROC 曲线、混淆矩阵、对比图表 |
| 撰写最终论文和讨论部分 | 生成统计报告和论文初稿 |
研究员负责创新,AI 负责执行。选什么数据、用什么方法、结果怎么解读——这些决策权在研究者手中。AI 做的是把数据清洗、模型训练、图表绘制这些重复性工作在 8 分钟内跑完。
值不值?算一笔账
这次分析消耗了 107 积分,折合人民币 1.07 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据预处理、5 种模型训练、分层 5 折交叉验证、SHAP 分析、6 张图表绘制、统计报告撰写——一个熟练的研究生至少需要 2-3 天。这里 8 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 1.07 元。
可以先看看完整的 AI 分析过程再决定。
产出清单 + 方法说明
| 产出文件 | 说明 |
|---|---|
| exploration_report.json | 数据探索报告(缺失值、分布、类别平衡) |
| model_performance.json | 5 种模型完整性能指标 |
| model_performance_comparison.csv | 模型性能对比表 |
| shap_feature_importance.csv | 30 个特征的 SHAP 重要性排序 |
| class_distribution.png | 良恶性类别分布图 |
| confusion_matrix.png | 最优模型混淆矩阵 |
| feature_distributions.png | 关键特征分布可视化 |
| roc_curve_comparison.png | 5 模型 ROC 曲线对比 |
| shap_summary_plot.png | SHAP 特征重要性柱状图 |
| shap_detailed_plot.png | SHAP 详细特征影响蜂巢图 |
数据来源:UCI Machine Learning Repository — Wisconsin Breast Cancer Diagnostic Dataset(569 例,30 个 FNA 图像特征)
分析方法:Logistic Regression、KNN、SVM、Random Forest、XGBoost,分层 5 折交叉验证,SHAP 解释性分析
原始论文:Ahmed KA, Humaira I, Khan AR, Hasan MS, Islam M, Roy A, Karim M, Uddin M, Mohammad A, Xames MD. Advancing breast cancer prediction: Comparative analysis of ML models and deep learning-based multi-model ensembles on original and synthetic datasets. PLoS ONE. 2025;20(6):e0326221. DOI: 10.1371/journal.pone.0326221
局限性:AI 复现仅覆盖原论文的传统 ML 部分(Phase 1),未复现合成数据生成(Gaussian Copula、TVAE)和深度学习集成部分。原论文共测试了 8 种模型 + 多种合成策略,AI 复现了其中 5 种核心 ML 模型。
方法差异:原论文和 AI 均使用 80/20 分层切分 + 5 折交叉验证,但随机种子不同,导致具体数值存在小幅差异。