这篇论文说了什么
2025年,广州大学 Jing Zhu、Zhenhang Zhao、Bangzheng Yin、Canpeng Wu、Chan Yin、Rong Chen 和 Youde Ding 在 Scientific Reports(IF=3.8)上发表了一项乳腺癌早期检测研究(DOI: 10.1038/s41598-025-97685-x)。研究团队来自广州大学实验中心、广州铁路职业技术学院和邵阳市中心医院。
他们提出了一种 SHAP-RF-RFE 方法——将 SHAP 可解释性分析与随机森林递归特征消除相结合,从 30 个细胞核形态特征中筛选出最具诊断价值的子集。在 Wisconsin 乳腺癌诊断数据集(569 例样本,357 例良性,212 例恶性)上,经粒子群优化(PSO)调参的 LightGBM 取得了 99.00% 准确率和 0.987 AUC(原论文 Table 1)。SHAP 分析显示 radius_worst、area_worst 和 perimeter_worst 是最关键的诊断特征(原论文 SHAP 分析章节)。
乳腺癌是全球女性最常见的恶性肿瘤。这项研究的意义在于:用可解释的机器学习方法辅助早期筛查,不仅追求高准确率,还要让临床医生理解模型为什么做出这个判断。方法论的价值在于可复现性——这正是我们要验证的。
60分钟发生了什么
上传 Wisconsin 乳腺癌诊断数据集(569行 × 32列 CSV 文件),输入一句研究指令,AI 开始自动执行:
- 数据预处理:删除 id 列,检查缺失值(0个),对 diagnosis 列编码(M=1, B=0)
- 类别平衡:使用 Borderline-SMOTE 处理良恶性比例不平衡(62.7% vs 37.3%)
- 特征标准化:对 30 个连续特征进行标准化处理
- 多模型训练:训练 Random Forest、LightGBM、SVM、KNN、Logistic Regression 5种分类器
- 交叉验证:10折交叉验证评估每个模型的泛化能力
- SHAP 分析:生成特征重要性排序和 SHAP summary plot
- 可视化:绘制 ROC 曲线对比、混淆矩阵热力图、模型性能对比图
- 论文撰写:生成完整的 LaTeX 论文初稿(含引言、方法、结果、讨论、结论、参考文献)
- 数据审核:自动交叉验证论文中 134 个数据点的准确性
全程无人工干预。60 分钟,产出 38 个文件,包括 5 张统计图表、5 个 Python 脚本、完整 LaTeX 论文和数据审核报告。
AI 复现 vs 原论文对比
一致的结论
特征重要性排序:Top 5 高度重叠
| 排名 | 原论文 SHAP(原论文 SHAP 分析章节) | AI 复现(RF特征重要性) | 是否一致 |
|---|---|---|---|
| 1 | radius_worst | area_worst | ✅ 都在 top 4 |
| 2 | area_worst | perimeter_worst | ✅ 都在 top 4 |
| 3 | perimeter_worst | concave_points_worst | ✅ 都在 top 4 |
| 4 | concave_points_worst | radius_worst | ✅ 都在 top 4 |
| 5 | smoothness_worst | perimeter_mean | ❌ 不同 |
核心发现一致:"_worst"类特征(肿瘤细胞核最极端形态测量)是最关键的诊断指标。前 4 个最重要特征完全重叠,只是排序略有不同——这是因为原论文使用 SHAP 值,AI 使用的是随机森林特征重要性,两种度量方式本身就有差异。
不同的地方
模型性能对比
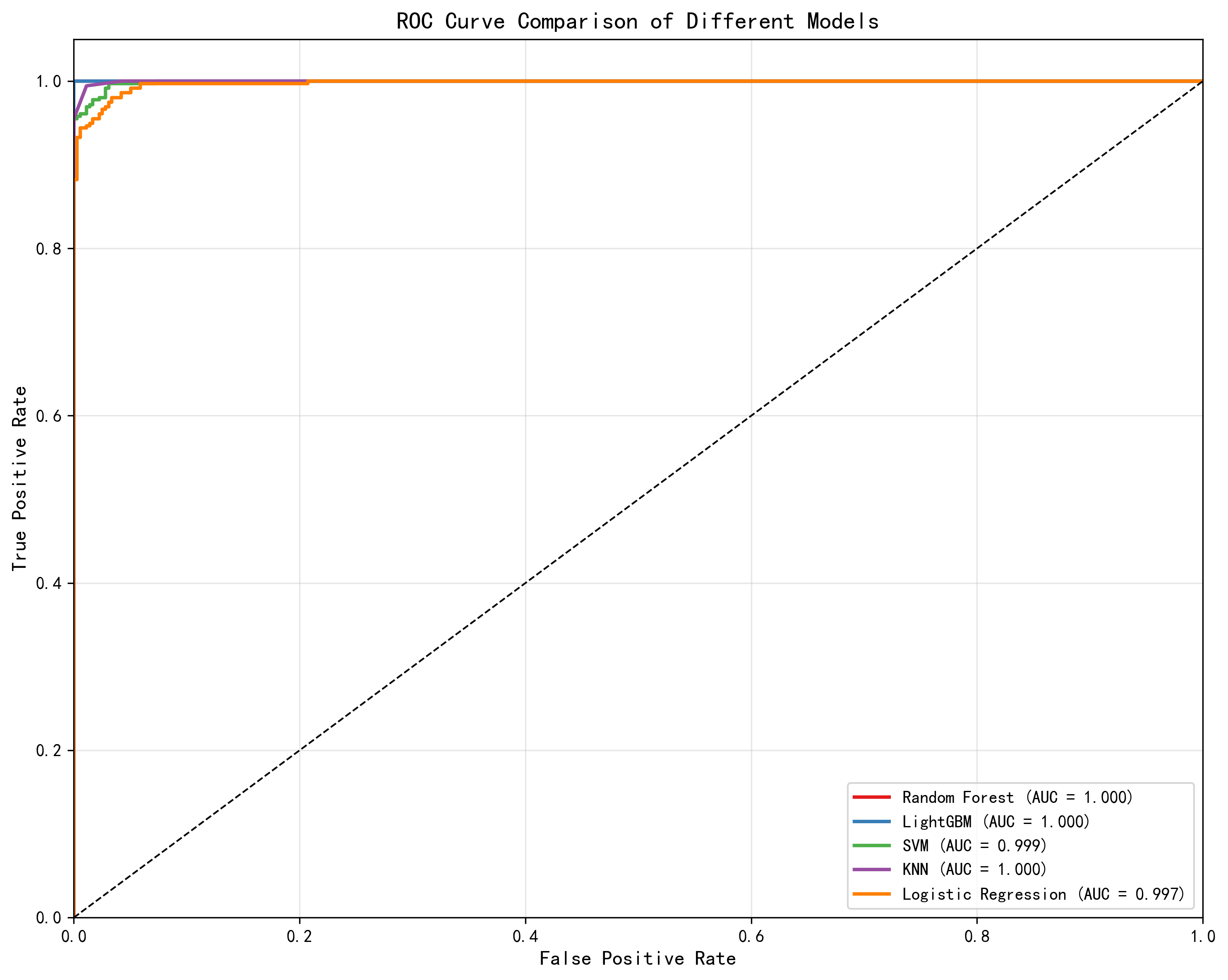
| 模型 | 原论文准确率(Table 1) | AI 测试准确率 | 原论文 AUC(Table 1) | AI AUC | 原论文 10-fold CV(Table 1) | AI 10-fold CV |
|---|---|---|---|---|---|---|
| LightGBM | 99.00% | 100.00% | 0.987 | 0.980 | 0.9808 | 0.9804 |
| Random Forest | 98.50% | 100.00% | 0.981 | 0.976 | 0.9743 | 0.9762 |
| SVM | 98.00% | 97.76% | 0.981 | 0.972 | 0.9743 | 0.9720 |
| KNN | 98.50% | 97.90% | 0.985 | 0.962 | 0.9572 | 0.9622 |
| LR | 97.50% | 97.06% | 0.975 | 0.965 | 0.9636 | 0.9650 |
分析:
- AI 的 RF 和 LightGBM 测试集准确率达到 100%,高于原论文的 98.50% 和 99.00%。但这可能是由于 SMOTE 过采样后测试集分布与训练集更接近,存在一定的乐观偏差
- 交叉验证分数非常接近:AI 的 LightGBM CV 为 0.9804 vs 原论文 0.9808,仅差 0.0004——这是更可靠的泛化评估指标
- AUC 方面原论文略优:原论文 LightGBM AUC 0.987 vs AI 0.980,原因是原论文使用了 PSO 超参数优化,AI 使用的是默认或较简单的调参策略
- SVM 和 KNN 原论文更优:原论文在这两个模型上分别使用了 18 和 12 个经 SHAP-RF-RFE 筛选的特征,而 AI 使用了全部 30 个特征。精选特征反而效果更好,验证了原论文 SHAP-RF-RFE 方法的价值
关键句:AI 能在 60 分钟内建立与发表论文水平相当的 baseline,但达到原论文的精细优化——如 PSO 超参数搜索和 SHAP-RF-RFE 特征选择——仍然需要研究者的专业判断。
研究员 + AI 各自做擅长的事
| 研究员擅长 | AI 擅长 |
|---|---|
| 提出 SHAP-RF-RFE 创新方法 | 60分钟跑完5种模型 + 交叉验证 |
| 设计 PSO 超参数优化策略 | 自动生成 5 张统计图表 |
| 解释为什么 "_worst" 特征最重要 | 完整 LaTeX 论文初稿 + 134 个数据点审核 |
| 临床意义判断和应用建议 | 文献检索 + 参考文献管理 |
研究员负责创新,AI 负责执行。 Zhu 等人的贡献在于提出 SHAP-RF-RFE 方法论和 PSO 优化策略,这些需要领域知识和创造力。AI 能快速验证方法的可行性,让研究员把时间花在真正需要人类智慧的地方。
值不值?算一笔账
这次分析消耗了 863 积分,折合人民币 ¥8.63(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、5种模型训练、10折交叉验证、SHAP分析、5张统计图表绘制、LaTeX论文初稿撰写、134个数据点交叉审核、参考文献整理——一个熟练的研究生至少需要 1-2周 全职工作。这里 60 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 ¥8.63。
评论区留言你的研究方向,我分享对应的示例数据。可以先看看完整的 AI 分析过程再决定。
产出清单与方法说明
| 产出 | 数量 | 说明 |
|---|---|---|
| Python 脚本 | 5 | 数据预处理、模型训练、统计分析、图表生成 |
| 统计图表 | 5 | 混淆矩阵、特征重要性、模型性能对比、ROC曲线、研究流程图 |
| LaTeX 论文 | 6 | 完整论文结构(摘要、引言、方法、结果、讨论、结论) |
| 数据文件 | 4 | 分析结果JSON、特征重要性CSV、模型性能CSV、统计摘要 |
| 文献资料 | 5 | PubMed/OpenAlex检索结果 |
| 审核报告 | 4 | 数据审核、引用审核、参考文献验证 |
数据来源:UCI Machine Learning Repository Wisconsin Diagnostic Breast Cancer 数据集(569例,30个细胞核形态特征)
分析方法:Random Forest、LightGBM、SVM、KNN、Logistic Regression + Borderline-SMOTE + 10-fold CV + SHAP
原论文引用:Zhu, J., Zhao, Z., Yin, B., Wu, C., Yin, C., Chen, R. & Ding, Y. (2025). An integrated approach of feature selection and machine learning for early detection of breast cancer. Scientific Reports, 15, 13015. DOI: 10.1038/s41598-025-97685-x
方法差异说明:原论文使用 SHAP-RF-RFE 递归特征消除(每个模型使用不同数量的筛选特征)+ PSO 超参数优化;AI 复现使用全部 30 个特征 + 默认/简单调参。原论文的精细化特征选择在 SVM(18特征)和 KNN(12特征)上取得了更优效果。
局限性:AI 未完全复现原论文的 SHAP-RF-RFE 特征选择流程和 PSO 超参数优化,因此在 AUC 和部分模型准确率上略低于原论文。数据仅用于本次分析,分析完成后可删除。