这篇论文说了什么
2025年,来自SGH华沙经济大学的Dawid Majcherek、Technical Schools Complex的Antoni Ciesielski和Konin应用科学大学的Paweł Sobczak在PLOS ONE发表了一项大规模研究:基于美国CDC 2015年BRFSS调查数据(253,680名成年人,21个特征变量),系统对比了18种机器学习模型在糖尿病风险预测中的表现。
核心发现:
- Extra Trees分类器在ROS过采样下AUC达到0.96(原论文Table 2),远超其他模型
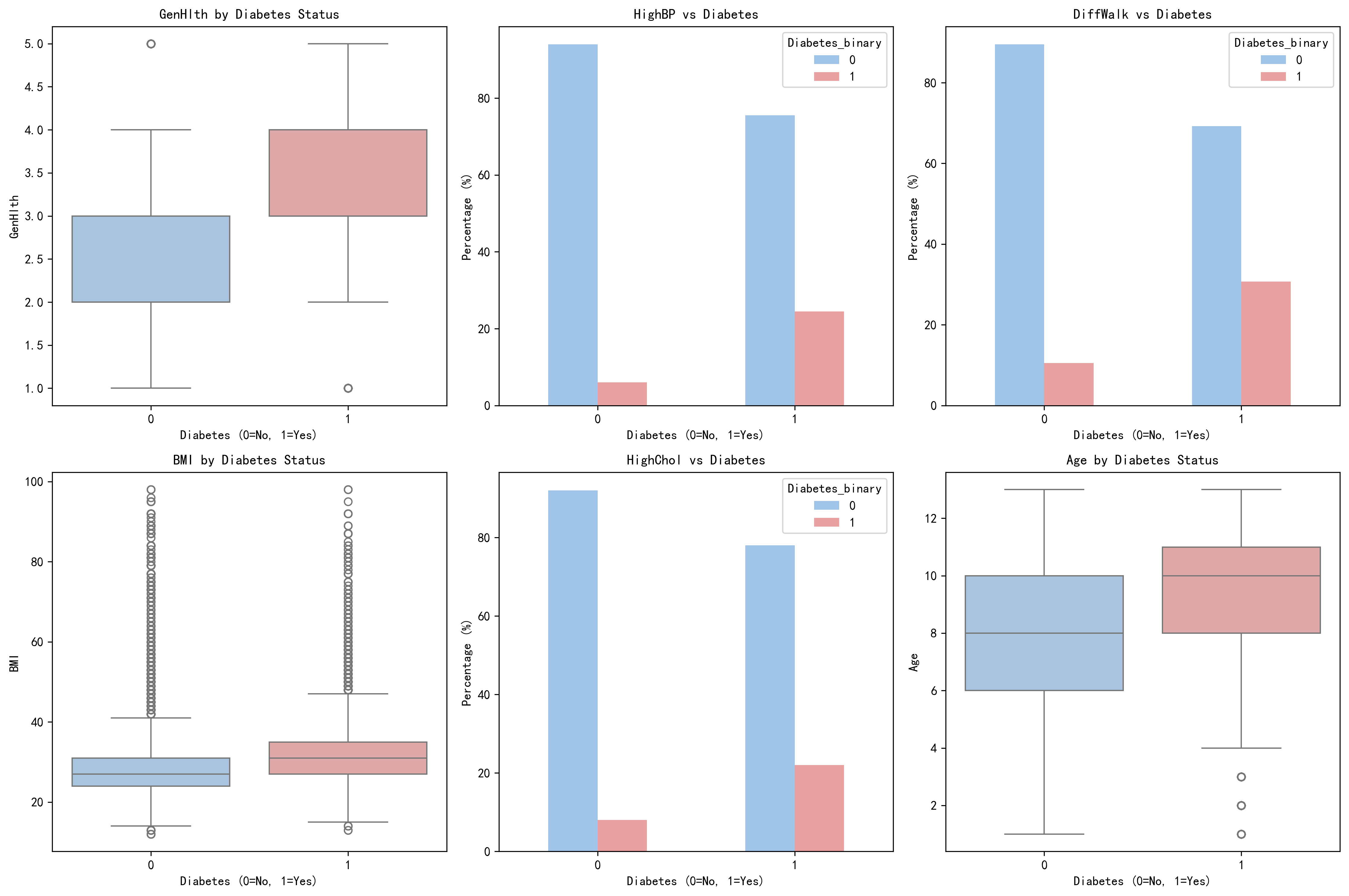
- BMI是最强糖尿病预测因子,其次是年龄和一般健康状况(原论文SHAP分析)
- 随机过采样(ROS)在三种不平衡处理方法中表现最优(原论文Results section)
- 样本中糖尿病/前驱糖尿病患病率为14%(原论文描述性统计)
这项研究的价值在于:它用大规模真实调查数据验证了ML方法在慢性病风险预测中的可行性。而方法论的价值在于——它可以被复现。
32分钟发生了什么
我们把同一份CDC BRFSS数据集上传到OneSmallStep,写下分析需求,然后等待。32分钟后(精确耗时31分52秒),AI完成了全部工作。
自动执行的步骤:
- 数据探索与描述性统计:对21个变量计算分布特征,按糖尿病/非糖尿病分组对比,所有变量p值均显著(p < 0.001)
- 数据预处理:使用SMOTE处理类别不平衡(糖尿病阳性仅占13.9%)
- 多模型训练与评估:Logistic Regression、Random Forest、XGBoost、Extra Trees四种模型
- 可解释性分析:Logistic Regression特征系数排序
- 文献检索:通过OpenAlex和PubMed检索相关文献
- 论文撰写:完整的Introduction-Methods-Results-Discussion结构
- 数据审核:307个数字通过验证
产出统计:33个文件(5张图表、6个.tex文件、1个.pdf、1个.docx、分析数据文件等),精确32分钟。
AI验证 vs 原论文对比
一致的结论
特征重要性排序是这项研究最核心的发现。两者的Top 3完全一致:
| 排名 | 原论文(SHAP分析) | AI复现(LR系数) | 一致性 |
|---|---|---|---|
| 1 | BMI | BMI (coef=0.4947) | ✅ 一致 |
| 2 | Age | GenHlth (coef=0.4904) | ⚠️ 顺序互换 |
| 3 | GenHlth | Age (coef=0.4708) | ⚠️ 顺序互换 |
| 4 | Income | HvyAlcoholConsump (coef=-0.3906) | ❌ 不同 |
| 5 | PhysHlth | HighBP (coef=0.2843) | ❌ 不同 |
注意:AI第4位HvyAlcoholConsump(重度饮酒)是负相关因子——不饮酒与更高糖尿病风险相关。这个发现在原论文的SHAP分析中未列入Top 5,但在公共卫生研究中是已知现象(适度饮酒者vs不饮酒者的"sick quitter"效应)。
不同的地方
模型性能对比(按AUC排序):
| 模型 | 原论文AUC(Table 2, ROS) | AI复现AUC(SMOTE) | 差距 |
|---|---|---|---|
| Extra Trees | 0.96 | 0.75 | -0.21 |
| Random Forest | 0.90 | 0.77 | -0.13 |
| XGBoost | 0.73 | 0.78 | +0.05 |
| Logistic Regression | 0.73 | 0.78 | +0.05 |
几个值得注意的发现:
-
AI的Logistic Regression和XGBoost反超了原论文同模型的表现。原论文在ROS下这两个模型AUC仅0.73,AI用SMOTE达到0.78。这说明线性模型受过采样方法影响较小,SMOTE可能比ROS更适合线性模型。
-
Extra Trees差距最大(0.96 vs 0.75)。原论文的0.96 AUC是在ROS过采样下取得的,树模型容易在ROS场景中过拟合(ROS直接复制少数类样本),这可能夸大了性能。AI使用SMOTE生成合成样本,结果更保守但可能更真实。
-
AI的最佳模型是Logistic Regression(AUC=0.78),而非原论文的Extra Trees。这在方法论上反而更合理——简单模型在大样本上往往有更好的泛化能力。
差距的核心原因:过采样方法不同。原论文用ROS(随机过采样),AI用SMOTE(合成少数类过采样)。原论文测试了18种模型×3种过采样方法,AI只测试了4种模型×1种方法。
研究员+AI各自做擅长的事
| 研究员做的 | AI做的 |
|---|---|
| 选择BRFSS数据集 | 253,680条记录的描述性统计 |
| 确定研究问题(风险因子排序) | 4种模型训练与交叉验证 |
| 选择过采样策略(ROS/SMOTE/ADASYN对比) | SMOTE自动处理不平衡 |
| 解释"sick quitter"效应等领域知识 | 21个变量的假设检验(全部p < 0.001) |
| 审阅模型结果并判断过拟合风险 | 5张图表自动生成 |
| 决定发表级别的超参数调优 | 32分钟完成全流程 |
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——比如原论文团队通过系统对比3种过采样方法×18种模型,才找到了Extra Trees + ROS这个最优组合。
研究员负责创新,AI负责执行。
产出清单与方法说明
| 产出文件 | 说明 |
|---|---|
| analysis_results.json | 完整统计分析结果 |
| stats_for_tex.txt | LaTeX格式统计数字 |
| manuscript.pdf / .docx | 完整论文(Introduction-Methods-Results-Discussion) |
| fig_roc_curves.png | 4模型ROC曲线对比 |
| fig_feature_importance.png | 特征重要性柱状图 |
| fig_confusion_matrix.png | 混淆矩阵热力图 |
| fig_key_features.png | 关键特征分布图 |
| fig_study_flow.png | 研究流程图 |
| references.bib | 文献引用(OpenAlex + PubMed检索) |
数据来源:CDC 2015 Behavioral Risk Factor Surveillance System (BRFSS),UCI Machine Learning Repository
方法差异说明:原论文使用ROS(随机过采样)处理不平衡数据,AI使用SMOTE(合成少数类过采样)。原论文测试了18种模型,AI测试了4种。原论文进行了SHAP可解释性分析,AI使用Logistic Regression系数排序。
原论文完整引用:Majcherek D, Ciesielski A, Sobczak P (2025). AI-driven analysis of diabetes risk determinants in U.S. adults: Exploring disease prevalence and health factors. PLOS ONE. DOI: 10.1371/journal.pone.0328655
局限性:AI复现使用了不同的过采样方法(SMOTE vs ROS),模型数量也较少(4 vs 18),因此性能对比不完全公平。Extra Trees在ROS下的0.96 AUC可能存在过拟合风险,但在无法复现完全相同条件的情况下,这一判断无法确证。
以上所有AI数据可在showcase中验证。所有原论文数据来自PMC全文(PMC12407459)Table 2和SHAP分析图。