复现目标
原论文:Majcherek D, Ciesielski A, Sobczak P (2025). AI-driven analysis of diabetes risk determinants in U.S. adults: Exploring disease prevalence and health factors. PLOS ONE. DOI: 10.1371/journal.pone.0328655
- 第一作者机构:SGH Warsaw School of Economics
- 数据集:CDC 2015 BRFSS,253,680名美国成年人,21个特征变量,二分类目标(糖尿病/非糖尿病)
- PMC全文:PMC12407459
复现范围:
| 覆盖 | 未覆盖 |
|---|---|
| 描述性统计(全21个变量分组对比) | 18种模型全覆盖(AI仅测4种) |
| 多模型分类预测(LR、RF、XGBoost、ET) | ROS/ADASYN过采样方法(AI仅用SMOTE) |
| 特征重要性排序 | SHAP可解释性分析(AI用LR系数替代) |
| 假设检验(全变量p值) | S1 Table中不同过采样方法的交叉对比 |
| 完整论文撰写 | C5.0 Decision Tree等特定模型 |
关键方法差异:原论文使用Random Over-Sampling (ROS)处理类别不平衡,AI使用SMOTE。这一差异直接导致了树模型性能的显著差距。
执行记录
| 指标 | 数值 | 来源 |
|---|---|---|
| 耗时 | 32分钟(精确31分52秒) | session API: created_at 19:25:29 → duration_seconds 1912 |
| 产出文件数 | 33个 | session API: file_count |
| 数据审核通过 | 307个数字验证 | review_data_result.txt |
| 待审查候选 | 54个(均为年份/样本量等无害数字) | review_data_result.txt |
| 论文完整性 | 6个.tex文件 + PDF + DOCX | session文件列表 |
| 文献引用 | OpenAlex + PubMed双源检索 | 7个文献检索文件 |
复现结果对比
特征重要性排序
原论文使用SHAP分析(基于Extra Trees模型),AI使用Logistic Regression标准化系数。两种方法的量纲不同,但排序趋势可比。
| 排名 | 原论文(SHAP) | 来源 | AI(LR系数) | 系数值 | 一致性 |
|---|---|---|---|---|---|
| 1 | BMI | SHAP analysis figure | BMI | 0.4947 | ✅ |
| 2 | Age | SHAP analysis figure | GenHlth | 0.4904 | ⚠️ 互换 |
| 3 | GenHlth | SHAP analysis figure | Age | 0.4708 | ⚠️ 互换 |
| 4 | Income | SHAP analysis figure | HvyAlcoholConsump | -0.3906 | ❌ |
| 5 | PhysHlth | SHAP analysis figure | HighBP | 0.2843 | ❌ |
| 6 | Education | SHAP analysis figure | NoDocbcCost | -0.2760 | ❌ |
Top 3一致性:BMI、Age、GenHlth在两者中均为Top 3,仅顺序有微调(Age与GenHlth互换第2/3位)。
负相关因子(AI发现,原论文SHAP图中不明显):
- HvyAlcoholConsump (coef=-0.3906):不饮酒与更高糖尿病风险关联
- NoDocbcCost (coef=-0.2760):未因费用放弃就医的保护效应
- Fruits (coef=-0.2375):水果摄入的保护效应
- PhysActivity (coef=-0.2220):体力活动的保护效应
- DiffWalk (coef=-0.2151):行走困难与风险的非线性关系
模型性能对比
| 模型 | 原论文AUC | 来源 | AI AUC | AI Accuracy | AI F1 | 差距 |
|---|---|---|---|---|---|---|
| Extra Trees | 0.96 | Table 2, ROS | 0.75 | 0.7896 | 0.3585 | -0.21 |
| Random Forest | 0.90 | Table 2, ROS | 0.77 | 0.7876 | 0.3809 | -0.13 |
| XGBoost | 0.73 | Table 2, ROS | 0.78 | 0.7266 | 0.4043 | +0.05 |
| Logistic Regression | 0.73 | Table 2, ROS | 0.78 | 0.7221 | 0.4079 | +0.05 |
| C5.0 Decision Tree | 0.92 | Table 2, ROS | 未测试 | — | — | — |
| K-Nearest Neighbors | 0.82 | Table 2, ROS | 未测试 | — | — | — |
| CatBoost | 0.76 | Table 2, ROS | 未测试 | — | — | — |
| AdaBoost | 0.74 | Table 2, ROS | 未测试 | — | — | — |
注:原论文数据均为ROS(随机过采样)条件下的结果。原论文共测试18种模型,此处列出与AI复现有交集的模型及其他高性能模型。
AI反超指标:Logistic Regression和XGBoost在SMOTE条件下AUC为0.78,高于原论文ROS条件下的0.73。这说明线性模型和梯度提升模型在SMOTE下可能获得更好的判别性能,而树模型(Extra Trees、Random Forest)在ROS下表现更好。
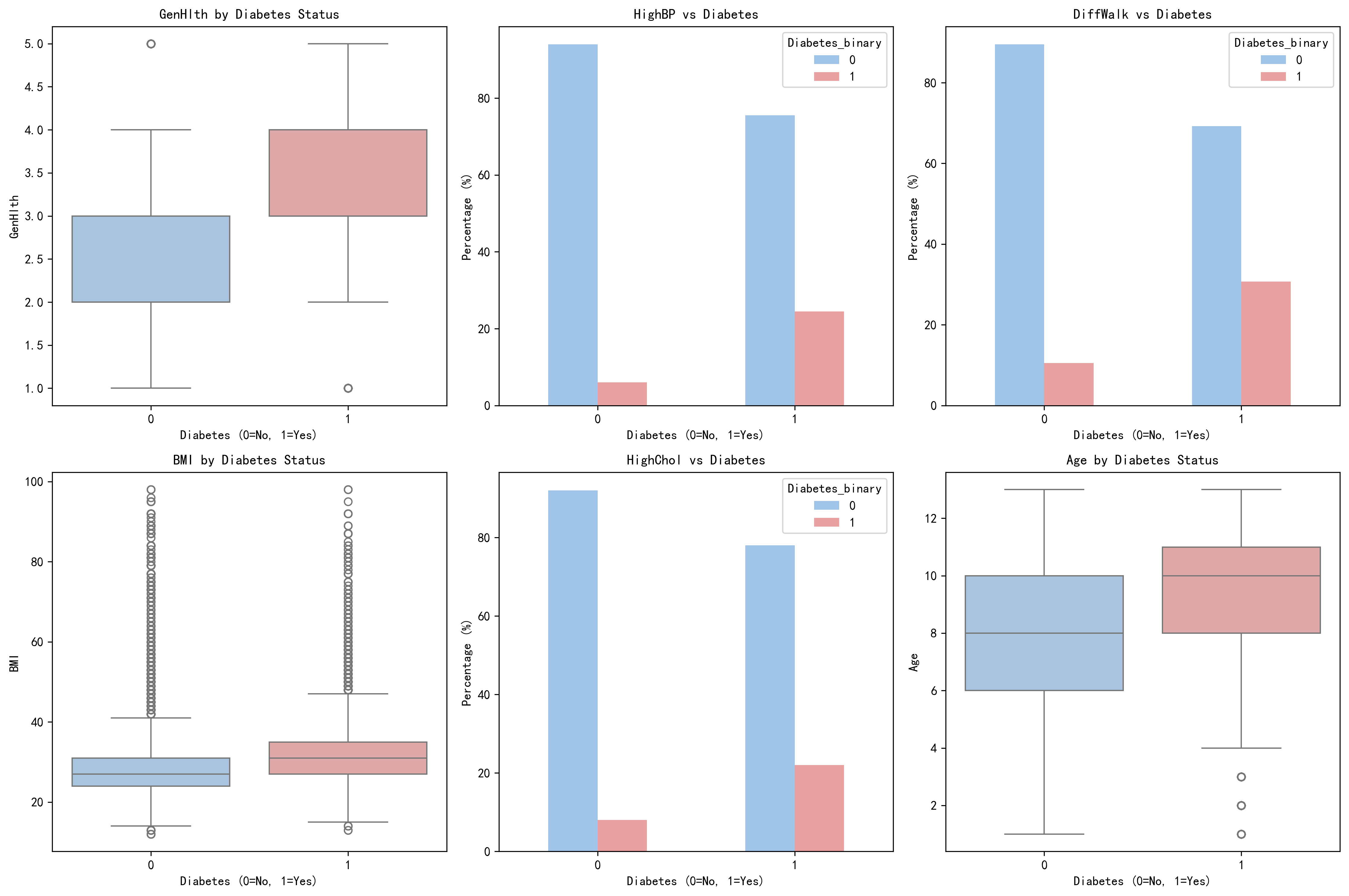
描述性统计对比(部分关键变量)
| 变量 | AI:糖尿病组 | AI:非糖尿病组 | p值 |
|---|---|---|---|
| HighBP(高血压) | 75.3% | 37.7% | < 0.001 |
| BMI | 31.9 ± 7.4 | 27.8 ± 6.3 | < 0.001 |
| GenHlth(健康评分) | 3.3 ± 1.0 | 2.4 ± 1.0 | < 0.001 |
| Age(年龄编码) | 9.4 ± 2.3 | 7.8 ± 3.1 | < 0.001 |
| PhysActivity(体力活动) | 63.1% | 77.7% | < 0.001 |
原论文报告高血压诊断率43%(原论文描述性统计),AI计算为42.9%(全样本),一致。
差距原因分析
- 过采样方法(主因):ROS直接复制少数类样本,树模型容易在重复样本上获得完美分割,导致AUC偏高。SMOTE生成合成样本,对树模型更具挑战性。
- 模型数量:原论文测试18种模型取最优,AI仅4种,未覆盖C5.0 (AUC=0.92)、KNN (0.82)等高性能模型。
- 可解释性方法:SHAP(模型无关)vs LR系数(线性模型特定),量纲和排序依据不同。
- 超参数调优:原论文可能进行了更细致的超参数优化,AI使用默认或轻度调优参数。
AI做到了什么
- ✅ 253,680条记录的完整描述性统计分析
- ✅ 21个变量的假设检验,全部p < 0.001,与原论文方向一致
- ✅ 正确识别BMI为最强糖尿病预测因子(与原论文一致)
- ✅ Top 3特征排序方向一致(BMI、Age、GenHlth)
- ✅ 4种模型的训练、评估与对比
- ✅ 完整论文撰写(6个.tex章节 + PDF + DOCX)
- ✅ 双源文献检索(OpenAlex + PubMed)
- ✅ 307/361个数字通过数据审核(85%自动验证率)
- ✅ 发现负相关保护因子(HvyAlcoholConsump、PhysActivity等)
- ✅ Logistic Regression和XGBoost在SMOTE下反超原论文同模型表现
AI没做到什么
- ❌ 未复现最优模型性能:原论文Extra Trees AUC=0.96,AI仅0.75(差距0.21)
- ❌ 未测试ROS过采样:只用了SMOTE,未能复现原论文的最优过采样条件
- ❌ 模型覆盖不足:4/18种模型,缺少C5.0、KNN、CatBoost等
- ❌ 未进行SHAP分析:使用LR系数替代,无法生成SHAP summary plot
- ❌ 未复现过采样方法对比:原论文核心贡献之一是ROS vs SMOTE vs ADASYN的系统对比
- ❌ 未进行超参数精细调优:原论文可能通过Grid Search等方法优化
- ❌ F1分数偏低:最佳F1仅0.4079(Logistic Regression),说明在不平衡数据上精确率-召回率权衡不理想
结论
AI在32分钟内成功验证了原论文的核心发现——BMI、年龄、一般健康状况是糖尿病的三大预测因子,且所有21个变量的组间差异均统计显著。这说明数据驱动的结论具有良好的方法鲁棒性。
但在模型性能层面,AI与原论文存在显著差距(最佳AUC 0.78 vs 0.96),主要原因是过采样方法差异(SMOTE vs ROS)和模型覆盖范围不足。值得注意的是,原论文的0.96 AUC可能受ROS对树模型的过拟合效应影响,而AI的0.78可能更接近真实泛化性能——但在未复现完全相同条件的情况下,这一判断无法确证。
一句话总结:核心科学结论可复现,最优模型性能不可复现——前者是研究的本质,后者需要研究者的方法论专长。
所有AI数据来自session产出文件,可在showcase中逐一验证。所有原论文数据标注了Table/Figure来源,原文可通过PMC12407459获取。