研究背景
心血管疾病是全球第一大死因。美国CDC的行为风险因素监测系统(BRFSS)每年对超过40万人进行健康行为调查,积累了大量流行病学数据。
本案例使用 BRFSS 2015 年的 253,680 条真实调查记录,由 AI 全自动完成了一项完整的回顾性研究。
输入
一个 CSV 文件(22.7 MB),包含 22 个健康指标变量:BMI、血压、胆固醇、吸烟、饮酒、体力活动、糖尿病史等。
AI 做了什么
整个过程耗时 38 分钟,102 轮人机交互,自动产出 48 个文件:
1. 数据探索与清洗
- 自动识别变量类型、缺失值分布
- 检测并处理异常值
- 生成数据质量审计报告
2. 统计建模
- 三种模型对比:逻辑回归、随机森林、XGBoost
- 两种重采样策略:SMOTE vs ADASYN(处理类别不平衡)
- 可解释性分析:SHAP 特征重要性排序
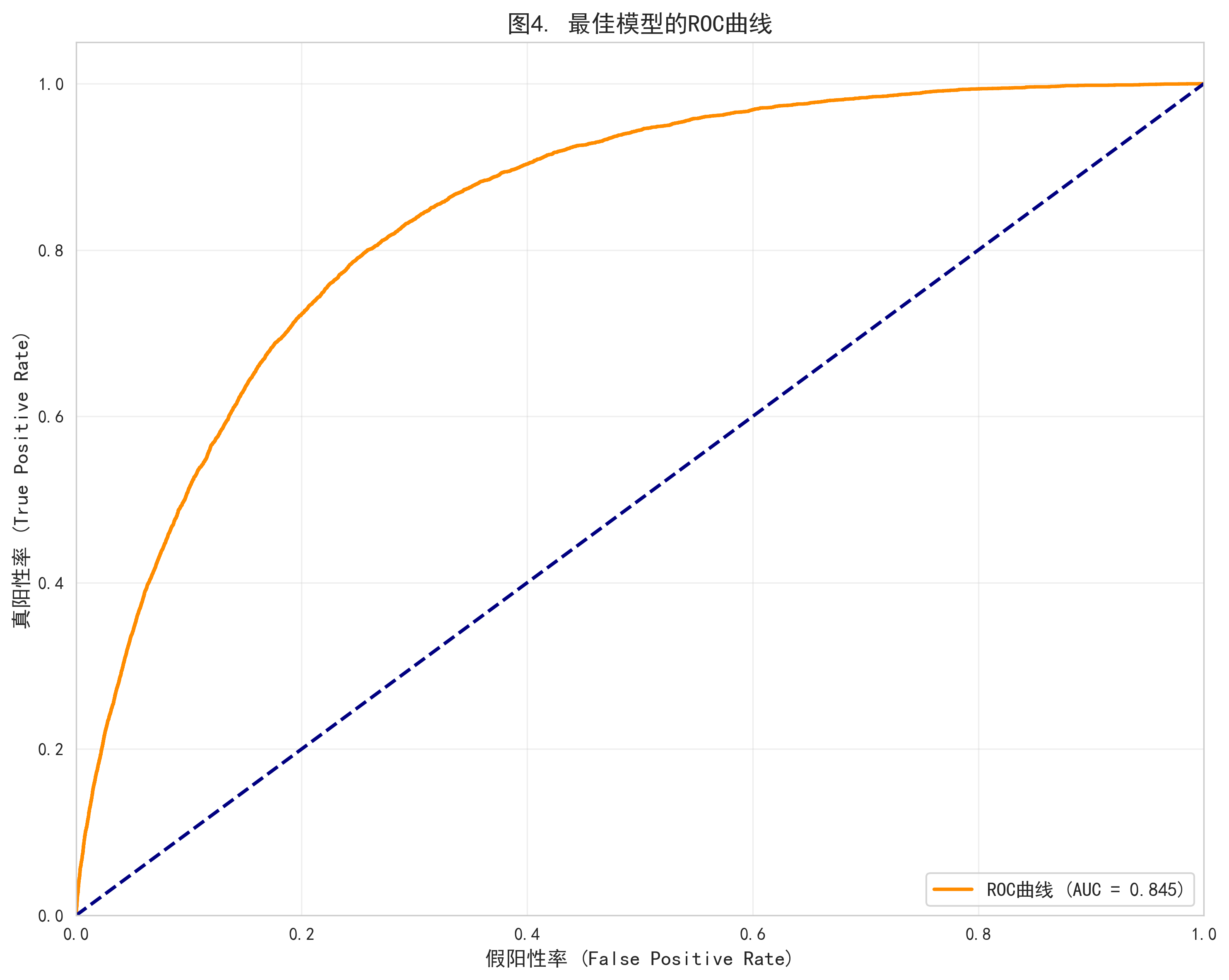
3. 图表生成
AI 自动生成了 5 张出版级统计图表:
4. 论文撰写
- 完整的 IMRaD 结构论文(引言、方法、结果、讨论、结论)
- LaTeX 源码 + PDF + Word 三种格式
- 自动检索 PubMed 和 OpenAlex 文献,生成参考文献库(67KB .bib 文件)
5. 质量控制
- 对抗性审稿报告(模拟 reviewer 挑问题)
- 数据-文本一致性校验:每个统计数字可追溯到分析代码
产出清单
| 类别 | 文件 | 说明 |
|---|---|---|
| 论文 | manuscript.pdf / .docx | 完整论文 |
| 源码 | 6 个 .tex + references.bib | LaTeX 源码 |
| 图表 | 5 张 .png | 出版级统计图 |
| 分析 | analysis_results.json | 结构化统计结果 |
| 代码 | 5 个 .py | 可复现的分析脚本 |
| 审查 | ADVERSARIAL_REVIEW.md | 对抗性审稿报告 |
关键发现
研究发现,在心血管疾病风险预测中:
- XGBoost 在 ADASYN 重采样后取得最佳 AUC
- 高血压、高胆固醇和 BMI 是最重要的三个预测因子(SHAP 分析)
- SMOTE 和 ADASYN 对不同模型的提升效果存在差异
这意味着什么
这不是一个"帮你写论文"的工具。它是一个 AI 辅助的研究流程自动化平台:
- 每个统计数字都有对应的 Python 代码可复现
- 每个引用都来自真实的学术数据库检索
- 论文是初稿,需要研究者审核修改后才能投稿
创新交给医生和研究者,实现交给 One Small Step。
AI 解决的是重复性劳动——数据清洗、模型调参、LaTeX 排版、文献格式化。研究者的时间应该花在研究设计和学术判断上。