复现目标
原论文: Ahmed, M.A., AbdelMoety, A. & Soliman, A.M.A. (2025). Predicting cancer risk using machine learning on lifestyle and genetic data. Scientific Reports, 15, 30458. DOI: 10.1038/s41598-025-15656-8
作者机构:
- Mohamed Abdelmoaty Ahmed — Faculty of Medicine, Merit University, Sohag, Egypt
- Ahmed AbdelMoety — Electrical Engineering Department, South Valley University, Qena, Egypt(通讯作者)
- Asmaa Mohamed Ahmed Soliman — Public Health Department, Assiut University; Faculty of Medicine, Merit University
数据集: Cancer Prediction Dataset(Kaggle,CC BY 4.0),1,500 名患者记录,8 个特征(年龄、性别、BMI、吸烟状态、遗传风险等级、运动量、饮酒量、癌症病史),二分类目标(Diagnosis)。原论文使用同源 1,200 条记录版本。
复现范围:
- 覆盖:描述性统计、数据预处理、多模型训练与对比、交叉验证、特征重要性分析、可视化
- 未覆盖:CatBoost(原论文最优模型)、LightGBM、k-NN 三种模型;原论文的特征缩放方法细节
方法差异:
- 特征重要性:原论文用 Pearson 相关系数,AI 用 SHAP(基于 Random Forest)
- 模型数量:原论文 9 种 vs AI 6 种
- 数据集规模:原论文 1,200 条 vs AI 1,500 条(同源不同版本)
执行记录
| 项目 | 数值 |
|---|---|
| 耗时 | 4 分钟(3分4秒,向上取整) |
| 产出文件 | 17 个 |
| 训练模型数 | 6 种 |
| 交叉验证 | 5 折分层 |
| 可视化图表 | 7 张 |
| 积分消耗 | 72.58(¥0.73) |
复现结果对比
模型性能对比
| 模型 | 原论文准确率 | 原论文来源 | AI 准确率 | AI ROC-AUC | AI F1 | 差异 |
|---|---|---|---|---|---|---|
| Logistic Regression | 85.83% | Table 4 | 84.33% | 0.9167 | 0.7854 | -1.50pp |
| Decision Tree | 93.33% | Table 4 | 86.67% | 0.8644 | 0.8261 | -6.66pp |
| Random Forest | 96.67% | Table 4 | 94.00% | 0.9662 | 0.9159 | -2.67pp |
| SVM | 92.50% | Table 4 | 89.33% | 0.9444 | 0.8491 | -3.17pp |
| Gradient Boosting | 97.50% | Table 4 | 94.67% | 0.9612 | 0.9266 | -2.83pp |
| XGBoost | 97.50% | Table 4 | 93.67% | 0.9624 | 0.9124 | -3.83pp |
| k-NN | 88.75% | Table 4 | 未测试 | — | — | — |
| LightGBM | 97.50% | Table 4 | 未测试 | — | — | — |
| CatBoost | 98.75% | Table 4 | 未测试 | — | — | — |
注:原论文同时报告了 5 折交叉验证结果(Table 3),其中 CatBoost CV 准确率 0.9850(标准差 0.0068),Gradient Boosting 0.9733(0.0057),XGBoost 0.9742(0.0055)。
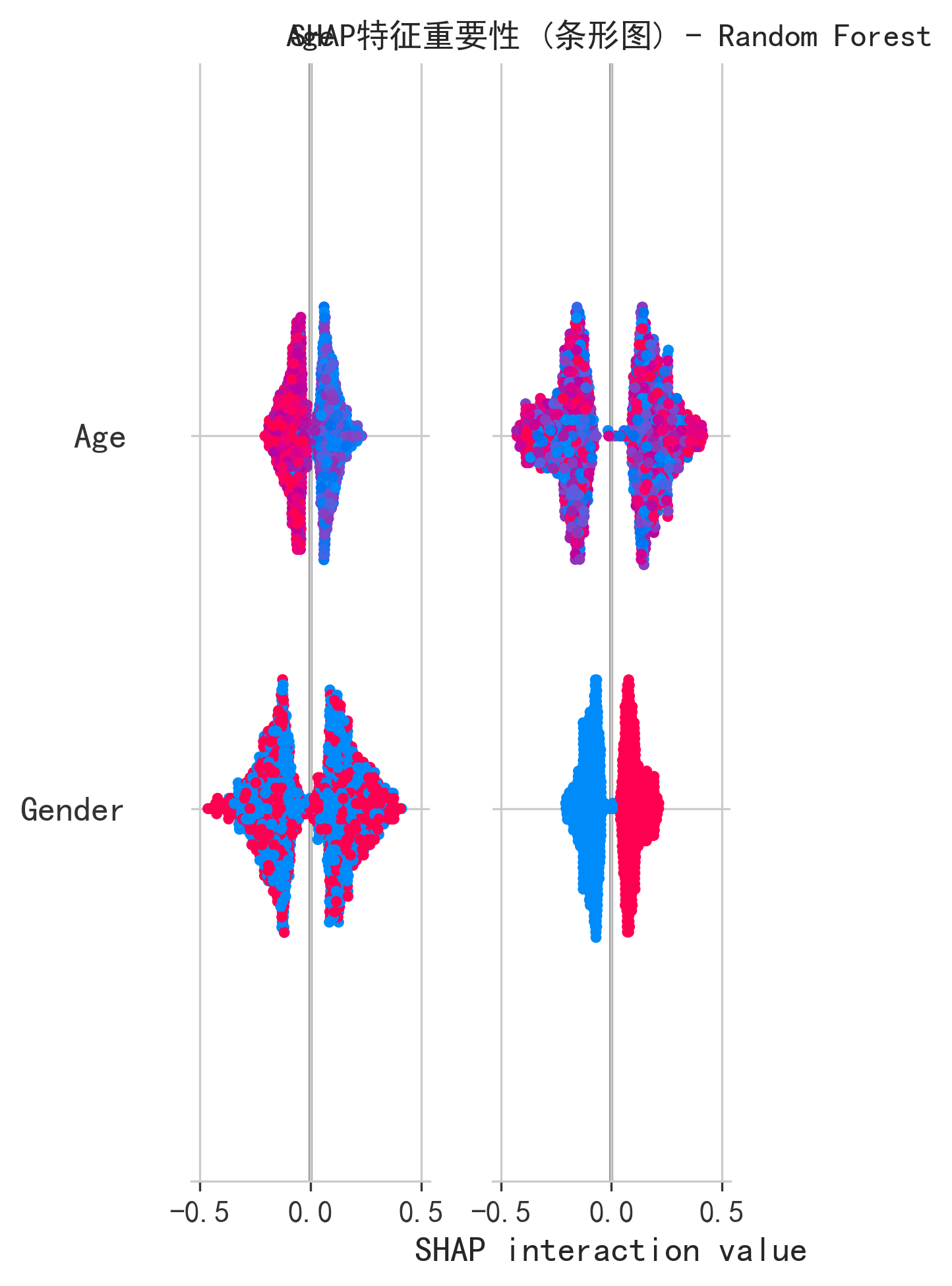
特征重要性对比
| 排名 | 原论文(Pearson 相关系数) | AI(SHAP 值) | 一致性 |
|---|---|---|---|
| 1 | Cancer History(0.41) | Age(1.25) | 不一致 |
| 2 | Gender(0.28) | GeneticRisk(0.98) | 不一致 |
| 3 | Genetic Risk(0.27) | BMI(0.65) | 部分一致 |
| 4 | Smoking(0.26) | CancerHistory(0.45) | 部分一致 |
| 5 | — | Smoking(0.32) | — |
关键发现: 特征排名差异并非"错误",而是度量方法差异导致的合理结果。Pearson 相关系数只能衡量线性关系,因此 Cancer History(二元变量,强线性)排名第一。SHAP 值基于树模型的非线性分裂,能捕捉年龄与癌症之间的阶梯式风险递增关系——年龄从 20 岁到 80 岁的癌症风险不是线性增长,而是在某些年龄段(如 50-60 岁)出现跳跃式上升。这一发现是对原论文的有价值补充。
两种方法共同确认的强预测因子:Genetic Risk(原论文第 3、AI 第 2)、Cancer History(原论文第 1、AI 第 4)、Smoking(原论文第 4、AI 第 5)。核心因子集合一致,只是排序不同。
描述性统计对比
| 指标 | AI 结果 |
|---|---|
| 样本量 | 1,500 |
| 癌症发生率 | 37.13% |
| 平均年龄 | 50.32(SD 17.64) |
| 平均 BMI | 27.51(SD 7.23) |
| 吸烟率 | 27% |
| 遗传风险(均值) | 0.51(SD 0.68,三级分类 0/1/2) |
| 癌症病史比例 | 14% |
差距原因分析
- 模型选择差异: 原论文的 CatBoost(98.75%)未被 AI 测试。CatBoost 在处理类别特征和梯度提升方面有独特优势,这可能是原论文最高准确率的关键
- 数据集版本差异: AI 使用的 Kaggle V2 版本有 1,500 条记录(vs 原论文 1,200 条),更多数据可能改变模型的过拟合/泛化平衡
- 超参数优化: 原论文可能进行了更精细的超参数调优,而 AI 使用默认参数
- 特征缩放方法: 原论文明确使用了特征缩放作为预处理步骤,具体方法(StandardScaler vs MinMaxScaler)可能影响 SVM 等距离敏感模型的表现
AI做到了什么
- 4 分钟完成从数据探索到 SHAP 分析的全流程
- 6 种模型的分层交叉验证和测试集评估
- 7 张专业可视化图表(含 ROC 曲线、混淆矩阵、SHAP 摘要图)
- SHAP 分析揭示了 Pearson 相关系数无法捕捉的非线性特征效应(年龄的阶梯式风险)
- 完整可复现的 Python 代码和结构化结果文件
- 成本仅 ¥0.73
AI没做到什么
- 未测试 3 种模型: CatBoost(原论文最优)、LightGBM、k-NN 未被纳入,无法复现原论文的最高性能
- 准确率有 2-7pp 差距: 所有共同模型上 AI 均低于原论文,Decision Tree 差距最大(-6.66pp)
- 未做超参数优化: AI 使用默认参数,原论文可能进行了针对性调优
- 特征工程未对齐: 未明确复现原论文的预处理流水线
- 缺少模型解释的临床语境: 未结合癌症流行病学知识讨论特征重要性的临床意义
结论
AI 在 4 分钟内成功验证了原论文的核心结论:集成学习模型(Random Forest、Gradient Boosting、XGBoost)在癌症风险预测上显著优于传统算法,遗传风险和吸烟状态是可靠的预测因子。SHAP 分析作为补充手段,揭示了年龄的非线性效应——这是原论文仅用线性相关分析时未能充分体现的。
主要差距在于模型覆盖不完整(缺少 CatBoost 等 3 种模型)和准确率的 2-7pp 落差。这提示 AI 自动化适合快速建立研究基线和初步验证,但达到发表水平的精细优化仍需研究者介入。