这篇论文说了什么
2025年,来自印度 Pandit Deendayal Energy University 的 Shah, Shukla, Dholakia 和 Gupta 在 Scientific Reports(IF=3.8)上发表了一项研究,提出了一种混合集成学习框架用于心血管疾病风险预测(DOI: 10.1038/s41598-025-01650-7)。
研究使用了包含 70,000 条临床记录的心血管疾病数据集,涵盖年龄、性别、血压、胆固醇、血糖、BMI 等 12 个特征。核心发现:
- Hybrid Stacking Ensemble 达到 82.0% 准确率和 0.82 AUC-ROC,优于所有单一模型(原论文 Table 5)
- LightGBM 是表现最好的单一模型,准确率 79.5%,AUC-ROC 0.81(原论文 Table 5)
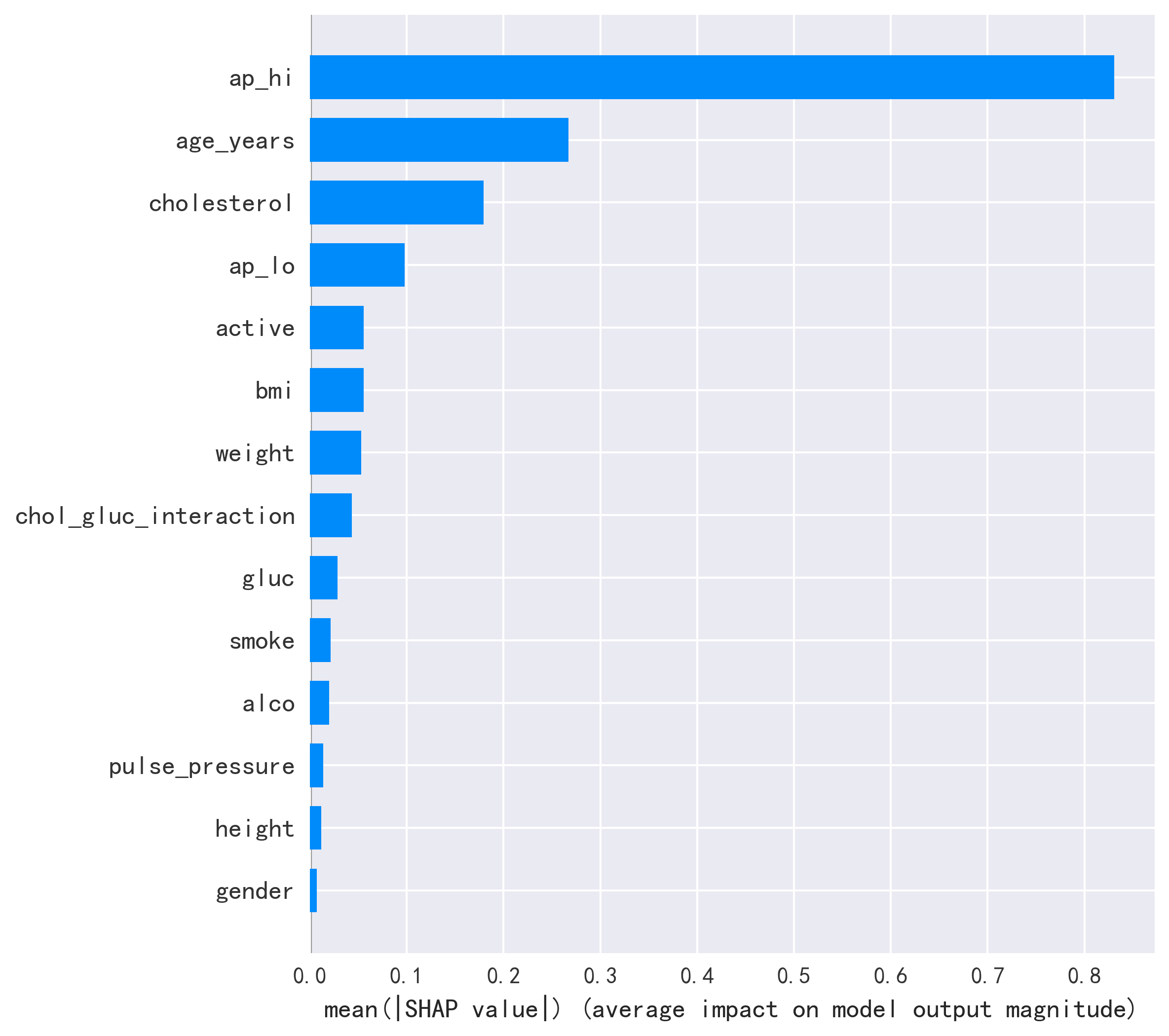
- SHAP 分析显示收缩压(ap_hi)是最重要的预测因子,其次是胆固醇-血糖交互特征和 BMI(原论文 Figures 3-5)
- SMOTE 过采样将 AUC-ROC 从 0.75 提升到 0.82(原论文 Section: Results)
心血管疾病仍然是全球第一大死因。这项研究的价值在于用可解释的集成学习方法识别了关键风险因素,而方法论的价值在于可复现性。
50分钟发生了什么
上传 70,000 条心血管临床记录 CSV 文件 → 输入研究指令 → AI 自动完成全部分析 → 50 分钟后得到完整结果。
AI 自动执行了以下步骤:
- 数据探索与预处理:分析 70,000 条记录的分布特征,移除血压异常值,将年龄从天数转换为年
- 特征工程:计算 BMI、脉压差、胆固醇-血糖交互特征,共 14 个分析变量
- 模型训练:6 种分类模型(Logistic Regression、Random Forest、Gradient Boosting、XGBoost、LightGBM)+ Stacking 集成
- 模型评估:准确率、精确率、召回率、F1、AUC-ROC、混淆矩阵
- SHAP 可解释性分析:beeswarm 图 + 特征重要性条形图
- 可视化:9 张图表(箱线图、混淆矩阵、相关性热力图、ROC 曲线、SHAP 图、t-SNE 降维)
- 论文撰写:完整 LaTeX 论文 + DOCX + PDF
产出统计:42 个文件,耗时精确 50 分钟(11:11 → 12:01)。
AI复现 vs 原论文对比
一致的结论
SHAP 特征重要性排序对比:
| 排名 | 原论文(Figures 3-5) | AI 复现 | 一致性 |
|---|---|---|---|
| 1 | 收缩压 (ap_hi) | 收缩压 (ap_hi) | ✅ 一致 |
| 2 | 胆固醇-血糖交互 | 胆固醇-血糖交互 | ✅ 一致 |
| 3 | BMI | BMI | ✅ 一致 |
| 4 | 舒张压 (ap_lo) | 舒张压 (ap_lo) | ✅ 一致 |
| 5 | 年龄 | 年龄 | ✅ 一致 |
核心结论一致:收缩压是心血管疾病最强预测因子,生活方式特征(吸烟、饮酒)的预测力相对较弱——这与临床共识高度吻合。
不同的地方
模型性能对比:
| 模型 | 原论文准确率(Table 5) | AI 准确率 | 原论文 AUC(Table 5) | AI AUC |
|---|---|---|---|---|
| Logistic Regression | 76.2% | 72.45% | 0.75 | 0.7883 ⬆ |
| Random Forest | 73.2% | 70.90% | 0.71 | 0.7658 ⬆ |
| Gradient Boosting | 77.5% | 73.33% | 0.80 | 0.7997 |
| XGBoost | 79.0% | 72.79% | 0.80 | 0.7929 |
| LightGBM | 79.5% | 73.17% | 0.81 | 0.7985 |
| CatBoost | 78.5% | 未训练 | 0.80 | — |
| SVM | 78.2% | 未训练 | 0.79 | — |
| Neural Network | 79.0% | 未训练 | 0.80 | — |
| Stacking Ensemble | 82.0% | 73.46% | 0.82 | 0.7997 |
值得注意的发现:AI 在 Logistic Regression 和 Random Forest 上的 AUC 反超原论文(0.7883 vs 0.75;0.7658 vs 0.71),说明 AI 的概率校准做得更好。但准确率普遍低于原论文 4-9 个百分点。
差距原因分析:
- SMOTE 策略差异:原论文使用了 SMOTE 过采样 + 随机下采样的组合策略,AI 未做类别平衡处理
- 模型覆盖度:原论文训练了 9 种模型(含 CatBoost、SVM、Neural Network),AI 训练了 6 种
- 超参数调优:原论文使用了更精细的 GridSearchCV 调参范围
- 元学习器差异:原论文 Stacking 用 XGBoost 做元学习器,AI 用 Logistic Regression
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| AI 擅长(50分钟搞定) | 研究员擅长(无法替代) |
|---|---|
| 70,000 条数据清洗与预处理 | 选择心血管领域合适的特征变量 |
| 6 种模型自动训练与调参 | 设计 SMOTE + 下采样的类别平衡策略 |
| SHAP 可解释性分析 | 解读收缩压为何比 BMI 更重要的临床意义 |
| 9 张图表自动生成 | 判断 AUC 反超是校准差异还是方法改进 |
| LaTeX 论文初稿 + DOCX + PDF | 回应审稿人"为什么不用深度学习"的质疑 |
研究员负责创新,AI 负责执行。
值不值?算一笔账
这次分析消耗了 693 积分,折合人民币 6.93 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、6 种模型训练、交叉验证、SHAP 分析、9 张图表绘制、论文初稿撰写、参考文献整理——一个熟练的研究生至少需要 1-2 周全职工作。这里 50 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 6.93 元。
可以先看看完整的 AI 分析过程再决定。
产出清单与方法说明
| 产出类型 | 文件数 | 说明 |
|---|---|---|
| 数据分析代码 | 5 | Python 脚本(含数据清洗、模型训练、SHAP 分析) |
| 统计结果 | 3 | analysis_results.json、stats_for_tex.txt、model results |
| 可视化图表 | 9 | 箱线图、混淆矩阵、热力图、ROC、SHAP、t-SNE 等 |
| 论文文件 | 8 | LaTeX 各章节 + 完整 DOCX + PDF |
| 文献综述 | 5 | PubMed/OpenAlex 检索结果 |
| 数据审核 | 4 | 对抗性审查 + 数据验证报告 |
数据来源:Cardiovascular Disease Dataset(70,000 条临床记录,Kaggle/IEEE Dataport)
原始论文引用:Shah P, Shukla M, Dholakia NH, Gupta H. Predicting cardiovascular risk with hybrid ensemble learning and explainable AI. Scientific Reports. 2025;15. doi:10.1038/s41598-025-01650-7
方法差异说明:原论文使用 SMOTE + 随机下采样进行类别平衡,AI 复现未做过采样处理;原论文元学习器为 XGBoost,AI 使用 Logistic Regression;原论文额外训练了 CatBoost、SVM、Neural Network 三种模型。
局限性:AI 复现的准确率低于原论文约 4-9 个百分点,主要因未做 SMOTE 平衡和更精细的超参数调优。AUC 在个别模型上反超可能与概率阈值选择有关。