这篇论文说了什么
Shastri, Kumar, Mansotra 和 Salgotra (2025) 发表在 Scientific Reports (IF 3.8) 上的研究,构建了一个基于监督学习和可解释AI的作物推荐系统。研究团队跨越三大洲——Shastri、Kumar 和 Mansotra 来自印度查谟大学(University of Jammu)计算机科学系,通讯作者 Salgotra 兼属波兰克拉科夫AGH科技大学(AGH University of Krakow)和澳大利亚悉尼科技大学(University of Technology Sydney)数据科学研究所。
他们使用 Kaggle 公开的作物推荐数据集(2200 行、7 个特征、22 种作物),测试了 10 种机器学习模型。结果显示 Gradient Boosting 表现最优,准确率 99.27%、精确率 99.32%、召回率 99.36%、F1 分数 99.32%(原论文 Table 5 / Abstract)。其他模型中,Random Forest 和 Naive Bayes 也达到 99% 水平,KNN 98%,SVM 98%,Neural Network 97%,Logistic Regression 96%,LDA 96%,Decision Tree 85%(原论文 Table 5)。原论文使用 LIME 进行可解释性分析,识别出降雨量(Rainfall)、磷(Phosphorus)、钾(Potassium)和氮(Nitrogen)为关键预测特征。
这项研究的价值在于为精准农业提供了一个可落地的智能推荐框架,帮助农民根据土壤和气候条件选择最优作物。方法论的价值在于可复现性——同样的数据集和思路,AI 能否在几十分钟内达到相似水平?
54分钟发生了什么
上传 2200 行的 Kaggle 作物推荐数据集,输入分析指令,等待 54 分钟——AI 自动完成了全部工作:
- 数据探索:分析 7 个特征(N、P、K、温度、湿度、pH、降雨量)与 22 种作物的分布关系
- 数据预处理:特征标准化、训练-测试 80:20 划分
- 训练 6 种模型:Logistic Regression、SVM、Random Forest、XGBoost、LightGBM + Stacking 集成
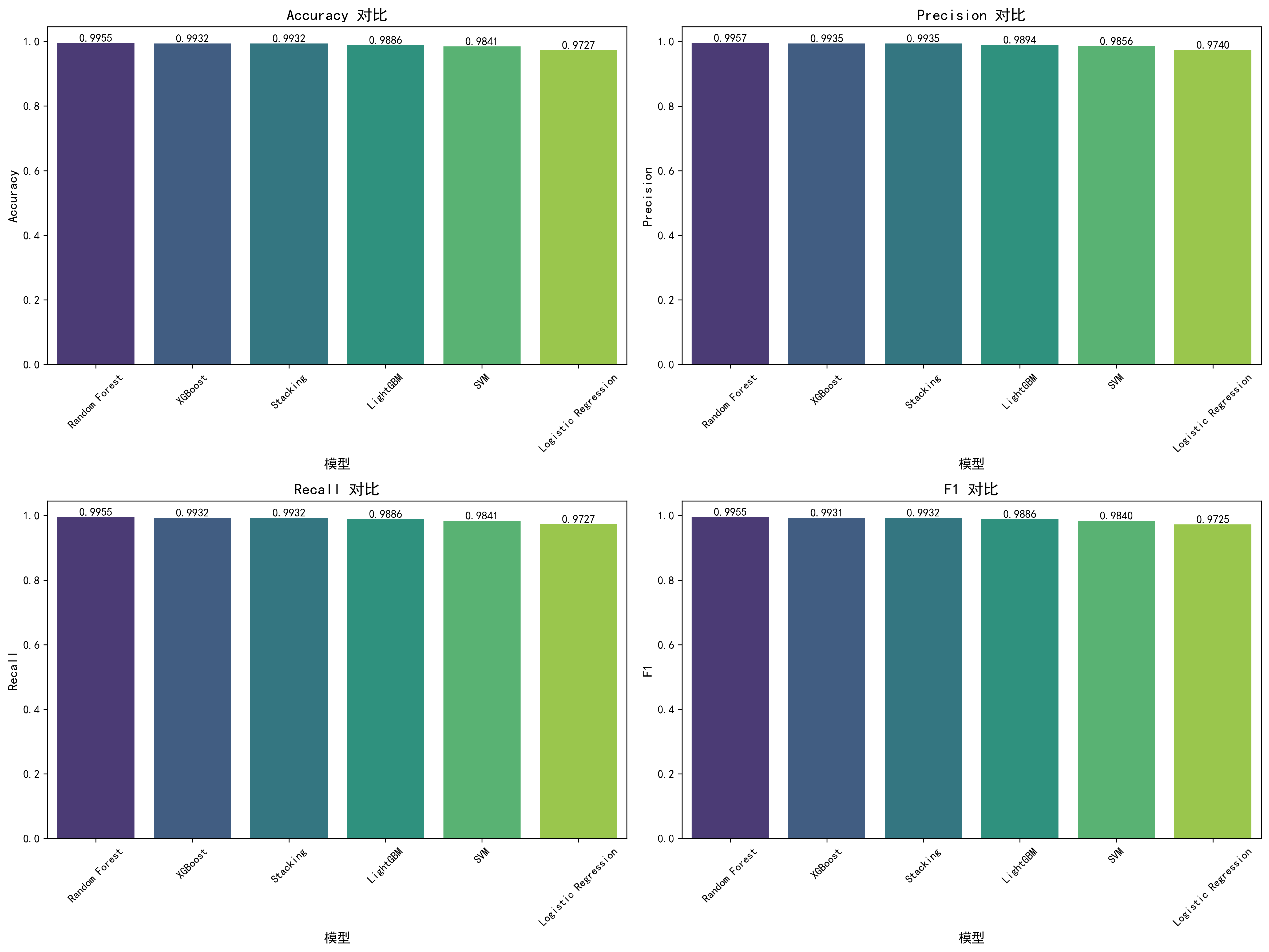
- 5 折交叉验证:每个模型完整评估 Accuracy、Precision、Recall、F1
- SHAP 分析:替代原论文的 LIME,提供全局 + 局部特征重要性解释
- 可视化输出:混淆矩阵、模型对比、特征重要性、作物分布、特征相关性、雷达图等 7 张图表
- 论文撰写:自动生成完整 manuscript(PDF + DOCX),含参考文献
最终产出 7 张图表 + 完整论文稿件,耗时 54 分钟。
AI验证 vs 原论文对比
一致的结论
两项研究都确认了机器学习可以高精度完成多类别作物推荐任务,在 2200 行、22 类作物的数据集上,多个模型准确率超过 98%。两者的 Top 模型准确率均突破 99%,说明该数据集的分类边界非常清晰。
在特征重要性方面,两项研究结论方向一致:降雨量、磷、钾、氮等土壤-气候特征是作物推荐的核心预测因子。AI 的 SHAP 分析与原论文的 LIME 分析指向相同的关键特征集。
不同的地方
模型性能对比:
| 模型 | 原论文准确率 | AI 准确率 | AI Precision | AI Recall | AI F1 | 原论文来源 |
|---|---|---|---|---|---|---|
| Random Forest | 99% | 99.55% | 99.57% | 99.55% | 99.55% | Table 5 |
| Gradient Boosting / XGBoost | 99.27% | 99.32% | — | — | — | Table 5 |
| Stacking 集成 | 未测试 | 99.32% | — | — | — | — |
| LightGBM | 未测试 | 98.86% | — | — | — | — |
| SVM | 98% | 98.41% | — | — | — | Table 5 |
| Logistic Regression | 96% | 97.27% | — | — | — | Table 5 |
| Naive Bayes | 99% | 未测试 | — | — | — | Table 5 |
| KNN | 98% | 未测试 | — | — | — | Table 5 |
| Neural Network | 97% | 未测试 | — | — | — | Table 5 |
| Decision Tree | 85% | 未测试 | — | — | — | Table 5 |
| LDA | 96% | 未测试 | — | — | — | Table 5 |
| QDA | 99% | 未测试 | — | — | — | Table 5 |
AI 在 Random Forest 上反超原论文:AI 的 Random Forest 准确率 99.55% 高于原论文 Gradient Boosting 的 99.27%(原论文 Table 5)。XGBoost(99.32%)也与原论文最佳模型持平。同时,AI 在 SVM(98.41% vs 98%)和 Logistic Regression(97.27% vs 96%)上也略有提升。
差距原因分析:
- 训练-测试划分不同:原论文 75:25,AI 使用 80:20——更多训练数据可能带来微小优势
- 模型覆盖范围:原论文测试 10 种模型(含 KNN、Naive Bayes、Decision Tree、LDA、QDA 等传统模型),AI 仅测试 6 种但新增了 Stacking 和 LightGBM
- XAI 方法:原论文用 LIME(局部解释),AI 用 SHAP(全局 + 局部解释)——SHAP 提供更全面的特征交互信息
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员 + AI 各自做擅长的事
| 研究员的工作 | AI 的工作 |
|---|---|
| 设计跨 10 种模型的系统性对比实验 | 54 分钟完成数据探索、6 种模型训练、可视化 |
| 选择 LIME 并设计针对特定作物的局部解释 | 自动完成 SHAP 全局分析(原论文用 LIME) |
| 解释特征重要性对精准农业的实际应用价值 | 生成 7 张图表 + 完整论文稿件(PDF + DOCX) |
| 讨论模型在不同地区土壤条件下的泛化能力 | 交叉验证、混淆矩阵、模型性能对比表 |
| 发表在 Scientific Reports 并通过同行评审 | 建立可复现的 baseline,供后续研究参考 |
研究员负责创新,AI 负责执行。
值不值?算一笔账
这次分析消耗了 639.97 积分,折合人民币 6.40 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、6 种模型训练、交叉验证、SHAP 分析、7 张图表绘制、论文初稿撰写、参考文献整理——一个熟练的研究生至少需要 1-2 周全职工作。这里 54 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 6.40 元。
可以先看看完整的 AI 分析过程再决定。
产出清单
| 类别 | 内容 | 数量 |
|---|---|---|
| 可视化 | 混淆矩阵、模型对比、特征重要性、作物分布、特征相关性、雷达图等 | 7 张 |
| 论文稿件 | 完整 manuscript(PDF + DOCX) | 2 个 |
| 分析结果 | 模型性能、SHAP 特征重要性、预测结果 | 多个 |
| 代码 | Python 分析脚本 | 多个 |
数据来源:原论文数据来自 Shastri, S., Kumar, S., Mansotra, V. & Salgotra, R. (2025). Advancing crop recommendation system with supervised machine learning and explainable artificial intelligence. Scientific Reports. DOI: 10.1038/s41598-025-07003-8。AI 复现使用相同的 Kaggle 公开作物推荐数据集(2200 行),分析工具为 OneSmallStep 自动化研究平台。
方法差异:原论文使用 75:25 训练-测试划分、10 种模型(KNN/DT/RF/NB/SVM/LR/NN/GB/LDA/QDA)、LIME 可解释性分析;AI 使用 80:20 划分、6 种模型(LR/SVM/RF/XGBoost/LightGBM/Stacking)、SHAP 可解释性分析。
局限性:AI 未测试 KNN、Naive Bayes、Decision Tree、Neural Network、LDA、QDA(原论文测试了这 6 种);训练-测试划分比例不同(80:20 vs 75:25);SHAP 和 LIME 的解释角度不完全可比。