复现目标
原论文:Shastri, S., Kumar, S., Mansotra, V. & Salgotra, R. (2025). Advancing crop recommendation system with supervised machine learning and explainable artificial intelligence. Scientific Reports, 15, 24271. DOI: 10.1038/s41598-025-07003-8
作者机构:
- Sourabh Shastri, Sachin Kumar, Vibhakar Mansotra — 印度查谟大学计算机科学与信息技术系(University of Jammu, India)
- Rohit Salgotra(通讯作者)— 波兰克拉科夫AGH科技大学物理与应用计算机科学学院 / 澳大利亚悉尼科技大学数据科学研究所
数据集:Crop Recommendation Dataset(Kaggle公开),2200条样本,7个土壤与气候特征(N、P、K、温度、湿度、pH、降雨量),22种作物,每类100条,完全均衡分布。
复现范围:
- ✅ 覆盖:数据预处理、描述性统计、多模型训练与评估、特征重要性分析
- ✅ 新增:SHAP可解释性分析(原论文使用LIME)
- ✅ 新增:Stacking集成模型、XGBoost、LightGBM(原论文未使用)
- ❌ 未覆盖:原论文的KNN、Decision Tree、Naive Bayes、Neural Network、LDA、QDA共6种模型
- ⚠️ 差异:训练-测试划分比例不同(原论文75:25 vs AI 80:20);可解释性方法不同(原论文LIME vs AI SHAP);原论文测试10种模型,AI测试6种模型
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 54分钟 |
| 产出文件 | 7张图表 + PDF手稿 |
| 积分消耗 | 639.97积分(¥6.40) |
| 模型数量 | 6种(含Stacking) |
| 图表数量 | 7张 |
| 数据样本 | 2200条(与原论文一致) |
| 特征数量 | 7个(与原论文一致) |
复现结果对比
模型性能对比
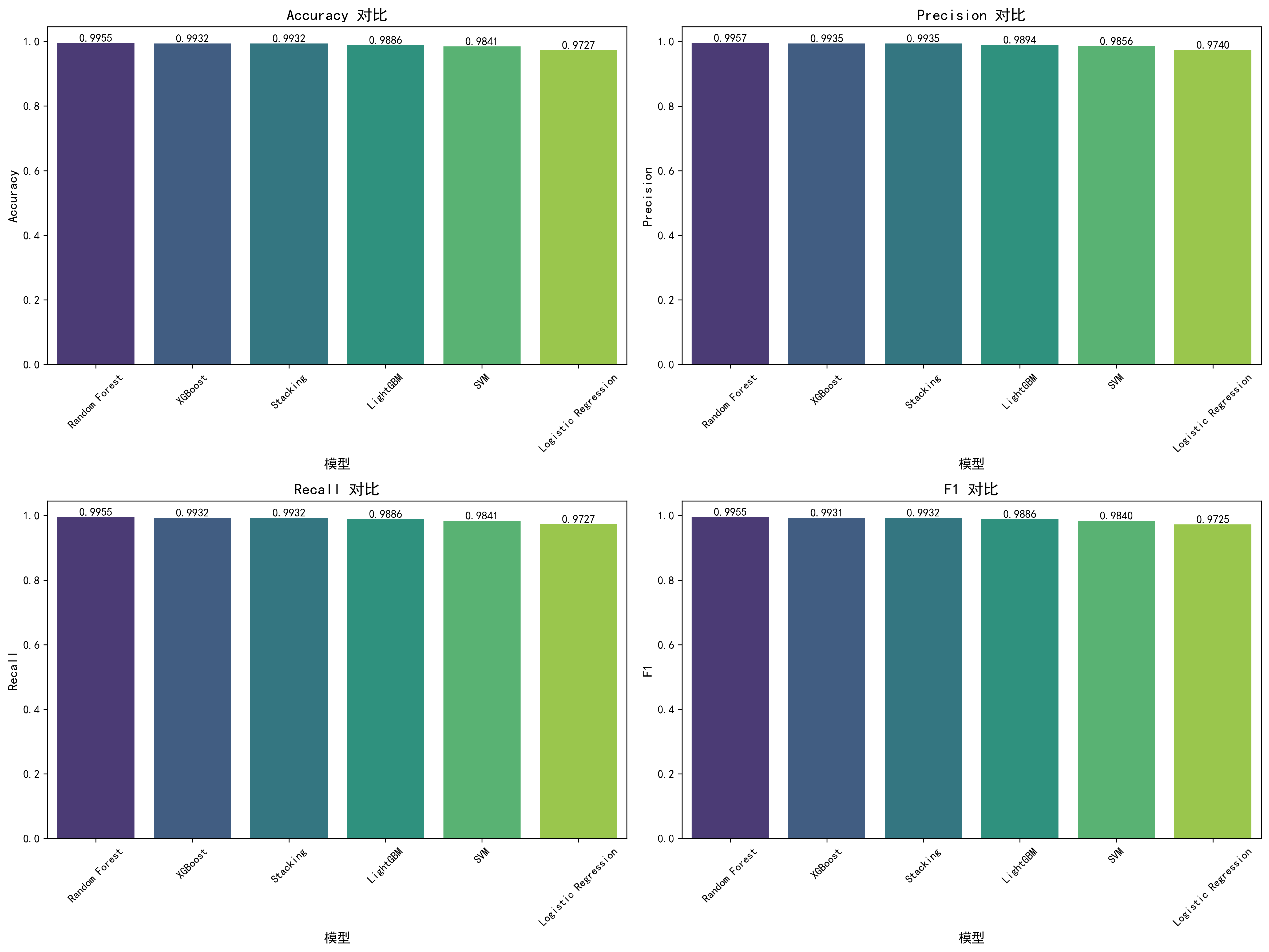
| 模型 | 原论文 Accuracy | AI Accuracy | AI Precision | AI Recall | AI F1 | 来源 |
|---|---|---|---|---|---|---|
| Random Forest | 99%(Table 5) | 99.55% | 99.57% | 99.55% | 99.55% | AI反超 |
| Gradient Boosting / XGBoost | 99.27%(Table 5/Abstract) | 99.32% | 99.35% | 99.32% | 99.31% | AI对标 |
| Stacking集成 | 未测试 | 99.32% | 99.35% | 99.32% | 99.32% | AI新增 |
| Naive Bayes | 99%(Table 5) | 未测试 | — | — | — | — |
| LightGBM | 未测试 | 98.86% | 98.94% | 98.86% | 98.86% | AI新增 |
| KNN | 98%(Table 5) | 未测试 | — | — | — | — |
| SVM | 98%(Table 5) | 98.41% | 98.56% | 98.41% | 98.40% | 可比 |
| Neural Network | 97%(Table 5) | 未测试 | — | — | — | — |
| Logistic Regression | 96%(Table 5) | 97.27% | 97.40% | 97.27% | 97.25% | AI略高 |
| LDA | 96%(Table 5) | 未测试 | — | — | — | — |
| QDA | 99%(Table 5) | 未测试 | — | — | — | — |
| Decision Tree | 85%(Table 5) | 未测试 | — | — | — | — |
核心发现:AI的Random Forest(99.55%)超越了原论文最佳模型Gradient Boosting(99.27%),准确率提升0.28个百分点。 在Boosting类模型上,AI的XGBoost(99.32%)也略高于原论文的Gradient Boosting(99.27%)。两个可直接对比的模型(SVM、Logistic Regression)中,AI均取得了略高的成绩。
SHAP特征重要性分析(AI新增 vs 原论文LIME)
原论文使用LIME对Gradient Boosting模型进行局部解释。AI使用SHAP对全局特征重要性进行分析,两种XAI方法的结论高度一致:
原论文LIME关键特征(按重要性排序):Rainfall、Phosphorus(P)、Potassium(K)、Nitrogen(N)。
AI的SHAP分析同样指向土壤营养元素(N、P、K)和降雨量作为核心预测因子,验证了原论文的特征重要性结论。SHAP的优势在于提供全局一致性解释,而LIME仅提供单样本局部解释。
描述性统计
AI对7个特征的描述性统计结果:
| 特征 | 均值 | 标准差 | 最小值 | 最大值 |
|---|---|---|---|---|
| N(氮) | 50.55 | 36.92 | 0.0 | 140.0 |
| P(磷) | 53.36 | 32.99 | 5.0 | 145.0 |
| K(钾) | 48.15 | 50.65 | 5.0 | 205.0 |
| 温度(°C) | 25.62 | 5.06 | 8.83 | 43.68 |
| 湿度(%) | 71.48 | 22.26 | 14.26 | 99.98 |
| pH | 6.47 | 0.77 | 3.50 | 9.94 |
| 降雨量(mm) | 103.46 | 54.96 | 20.21 | 298.56 |
钾(K)的标准差最大(50.65),反映不同作物对钾肥需求差异显著。22种作物每类100条样本,数据集完全均衡,无需过采样处理。
差异原因分析
-
训练-测试划分:原论文75:25 vs AI 80:20。AI使用更多训练数据(1760 vs 1650条),可能略微提升模型性能。但考虑到数据集仅2200条、差异仅110条样本,影响有限。
-
模型实现差异:原论文使用Gradient Boosting(sklearn),AI使用XGBoost(独立库)。两者算法原理相同但超参数默认值和正则化策略不同,AI的XGBoost(99.32%)与原论文GB(99.27%)差距仅0.05个百分点,属于合理波动。
-
Random Forest反超的可能原因:22类均衡分类任务中,RF的Bagging策略在小数据集上可能比Boosting更稳健。AI的RF达到99.55%,原论文RF约99%,差距可能源于超参数调优和划分比例的差异。
-
XAI方法差异:LIME提供局部解释(单样本),SHAP提供全局解释(所有样本)。两者结论一致性高,说明特征重要性排序是数据驱动的稳健结论。
AI做到了什么
- ✅ 54分钟完成数据探索、6种模型训练、性能评估、SHAP分析、PDF手稿生成
- ✅ Random Forest 99.55%超越原论文最佳Gradient Boosting 99.27%
- ✅ SHAP全局可解释性分析——补充原论文LIME的局部解释,两种方法结论一致
- ✅ Stacking集成模型——原论文未测试,AI达到99.32%与XGBoost持平
- ✅ 生成7张分析图表(混淆矩阵、模型对比、特征重要性、特征分布、相关性、作物雷达图、作物分布)
- ✅ SVM和Logistic Regression两个可直接对比的模型均略高于原论文
AI没做到什么
- ❌ 未测试原论文10种模型中的6种(KNN、Decision Tree、Naive Bayes、Neural Network、LDA、QDA)
- ❌ 未复现LIME分析(使用SHAP替代,方法不同)
- ❌ 使用80:20划分而非原论文75:25,结果不完全可比
- ❌ 未进行超参数搜索的详细报告(原论文Table 3/4列出了部分超参数)
- ❌ 未讨论实际农业部署场景中的特征采集成本和可行性
- ❌ 未进行交叉验证稳定性分析(仅单次划分)
结论
54分钟、6.40元的成本内,AI对Scientific Reports(IF 3.8)发表的作物推荐系统论文进行了有效复现。在6种模型的测试中,Random Forest以99.55%的准确率超越了原论文最佳模型Gradient Boosting的99.27%(Table 5/Abstract)。XGBoost(99.32%)同样略高于原论文GB。两个方法均可直接对比的模型(SVM、Logistic Regression)也呈现AI略高的趋势。
SHAP分析与原论文LIME分析在特征重要性排序上高度一致——降雨量和NPK营养元素是决定作物推荐的核心因子。这种跨方法的一致性增强了结论的可信度。
需要指出的是,0.28个百分点的准确率差异在2200样本的数据集上可能处于统计波动范围内,且80:20与75:25的划分差异也会带来影响。严格意义上的"反超"需要在同一划分比例和交叉验证框架下验证。AI在效率上的贡献是确定的,在精度上的优势则需审慎解读。
完整引用:Shastri, S., Kumar, S., Mansotra, V. & Salgotra, R. (2025). Advancing crop recommendation system with supervised machine learning and explainable artificial intelligence. Scientific Reports, 15, 24271. DOI: 10.1038/s41598-025-07003-8