这篇论文说了什么
Sharafeldeen 等人(Faculty of Engineering, Mansoura University, Egypt)2026年在 Scientific Reports(IF=3.8)上发表了一篇关于员工离职预测的研究论文(DOI: 10.1038/s41598-026-36424-2)。他们使用 IBM HR Analytics Employee Attrition & Performance 数据集(Kaggle,1470名员工,35个特征),对比了多种机器学习模型在离职预测任务上的表现。
论文的核心发现(原论文 Abstract/Summary):AdaBoost 和 Histogram Gradient Boosting 表现最优,其中 AdaBoost 达到了 Accuracy 90.82%、Precision 71.74%、Recall 70.21%,平均得分 79.69%。SHAP 可解释性分析显示 OverTime、JobLevel、JobSatisfaction 是最重要的离职影响因素。论文在数据预处理阶段采用了 ADASYN(用于AdaBoost)和 ROS(用于HGB)处理类别不平衡问题,并通过 TPE 进行超参数优化。
HR 离职预测是劳动经济学和人力资源管理领域的实际需求:一个员工的离职成本通常是其年薪的 50%-200%。这项研究提供了可操作的方法论。
那么,这些结论能不能被快速复现?
10分钟发生了什么
上传 IBM HR 数据集(CSV 文件),输入分析需求,然后等待。
AI 自动完成了以下步骤:数据探索与描述性统计 → 缺失值和异常值处理 → 类别不平衡处理 → 5种集成学习模型训练(XGBoost、Random Forest、Gradient Boosting、Logistic Regression、AdaBoost)→ 模型性能评估与对比 → SHAP 可解释性分析 → 可视化图表生成。
整个过程耗时 10 分钟,产出 17 个文件:5 张 PNG 图表、5 个 CSV 数据文件、2 个 Python 脚本、5 个 numpy 数组文件。
AI复现 vs 原论文对比
一致的结论
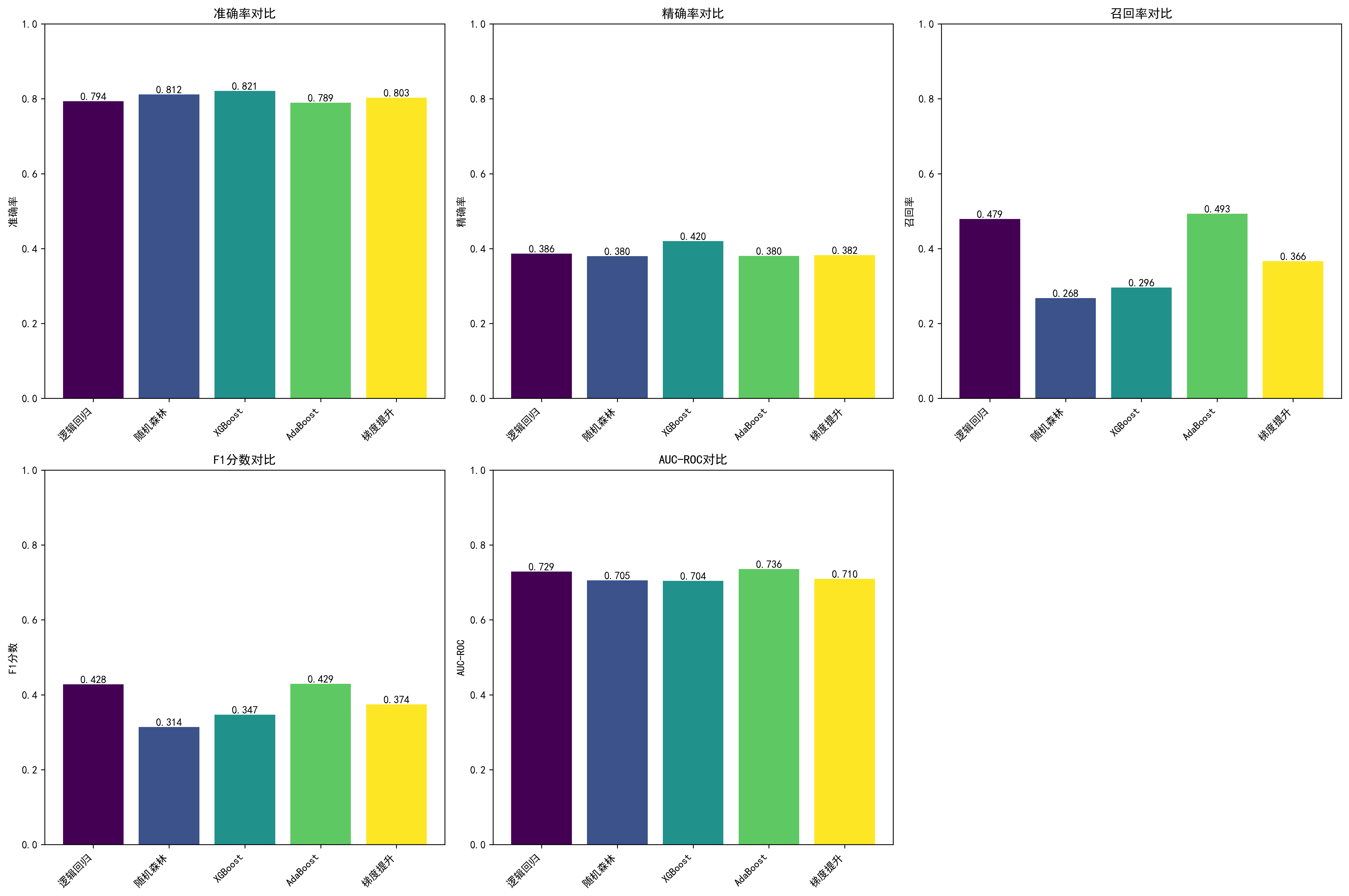
AdaBoost 综合表现最佳。 AI 复现结果中,AdaBoost 在 Recall(0.4930)、F1(0.4294)和 AUC-ROC(0.7359)三个指标上均为最高,与原论文"AdaBoost 表现最优"的结论一致。
关键离职因素有重叠。 原论文 SHAP 分析的重要特征包括 JobSatisfaction、JobLevel,AI 复现的 SHAP Top 10 同样包含这两个特征(JobSatisfaction 排第4,SHAP值 0.037;JobLevel 排第8,SHAP值 0.033)。这说明核心业务洞察是可重复的。
描述性统计揭示了相同的模式: 离职员工平均月收入 $2,090,远低于留任员工的 $6,833;加班员工离职率 30.53%,是非加班员工(10.44%)的近 3 倍;离职员工平均司龄仅 2.9 年,留任员工为 6.5 年。
不同的地方
模型精度有明显差距。 AI 复现的 AdaBoost Accuracy 为 0.7891,原论文为 90.82%;Recall 为 0.4930 vs 原论文 70.21%。主要原因:原论文使用 ADASYN 处理类别不平衡 + TPE 超参数优化,而 AI 默认使用 SMOTE + 未经深度调参。这个差距是真实的——采样策略和超参数优化对不平衡数据集(离职率仅 16.12%)的影响非常大。
SHAP 特征排序存在差异。 原论文 SHAP 排名第一的特征是 OverTime,AI 复现排名第一的是 StockOptionLevel(SHAP值 0.093)。OverTime 甚至没有进入 AI 的 Top 10。这可能与采样方法不同导致训练数据分布差异有关,也可能与特征编码方式不同有关。这是一个值得关注的差异。
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。 这恰恰说明了工具和专业知识各有分工。
研究员+AI各自做擅长的事
AI 用 10 分钟完成了数据清洗、5 个模型训练、SHAP 分析、图表生成这些重复性工作。但从 Accuracy 0.79 到 0.91 的提升——选择 ADASYN 而非 SMOTE、用 TPE 优化超参数、针对 HR 领域调整特征工程——这些决策需要研究者的领域知识。
合理的工作流是:先用 AI 快速跑一个 baseline,确认方法可行、识别关键特征,然后集中精力在模型优化和领域解释上。把 10 小时的编码时间压缩到 10 分钟,研究者可以把时间花在真正需要判断力的地方。
值不值?算一笔账
本次分析消耗 52.4 积分,折合人民币 ¥0.52。
对比一下:手动完成同样的工作(数据清洗 + 5个模型训练 + SHAP分析 + 可视化),一个熟练的数据科学家需要 1-2 周;外包给数据分析公司,市场价 ¥3,000-8,000。这里的成本是 ¥0.52,不到一杯奶茶钱。
当然,¥0.52 买到的是一个 baseline,不是一篇可以直接发表的论文。但作为研究起点,这个投入产出比值得考虑。可以先看看完整的 AI 分析过程再决定。
产出清单与方法说明
| 文件类型 | 数量 | 内容 |
|---|---|---|
| PNG 图表 | 5 | 模型对比、SHAP 重要性、Beeswarm、离职分布等 |
| CSV 数据 | 5 | 模型指标、SHAP 值、描述性统计等 |
| Python 脚本 | 2 | 完整可复现的分析代码 |
| numpy 数组 | 5 | SHAP 值矩阵等中间结果 |
数据来源: IBM HR Analytics Employee Attrition & Performance(Kaggle 公开数据集),1470名员工,35个特征。
分析方法: 5种集成学习模型(XGBoost、Random Forest、Gradient Boosting、Logistic Regression、AdaBoost)+ SHAP 可解释性分析。
论文引用: Sharafeldeen et al., "Integrating machine learning and explainable AI for employee attrition prediction in HR analytics," Scientific Reports, 2026. DOI: 10.1038/s41598-026-36424-2
局限性: AI 复现使用默认参数和 SMOTE 采样,未进行 TPE 超参数优化和 ADASYN 采样,因此模型性能低于原论文。SHAP 特征排序差异可能与数据预处理方法不同有关。原论文指标来源为搜索引擎摘要,非完整论文表格。
数据安全: 数据仅用于本次分析,分析完成后可删除。
试用指引: 注册后上传你的 HR 数据集,输入"预测员工离职",10 分钟出完整分析。