复现目标
原论文:Sharafeldeen, A. et al. (2026). Integrating machine learning and explainable AI for employee attrition prediction in HR analytics. Scientific Reports, 16, 6344. DOI: 10.1038/s41598-026-36424-2
作者机构:Faculty of Engineering, Mansoura University, Egypt
数据集:IBM HR Analytics Employee Attrition & Performance,1470 名员工,35 个特征,二分类目标变量(Attrition: Yes/No),离职率约 16%。
复现范围:
- ✅ 覆盖:5 种分类模型(AdaBoost、Random Forest、XGBoost、Logistic Regression、Gradient Boosting)、SHAP 全局与局部可解释性分析
- ❌ 未覆盖:Histogram Gradient Boosting(原论文最佳模型)、ADASYN 过采样、TPE 超参数优化、多数据集交叉验证
方法差异:原论文使用 ADASYN 处理类别不平衡 + TPE(Tree-structured Parzen Estimator)进行超参数优化;AI 复现使用默认 SMOTE + 默认超参数。这一差异是导致性能差距的主要原因。
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 10 分钟 |
| 产出文件数 | 17 个 |
| 训练模型数 | 5 种 |
| 积分消耗 | 52.4 积分(¥0.52) |
复现结果对比
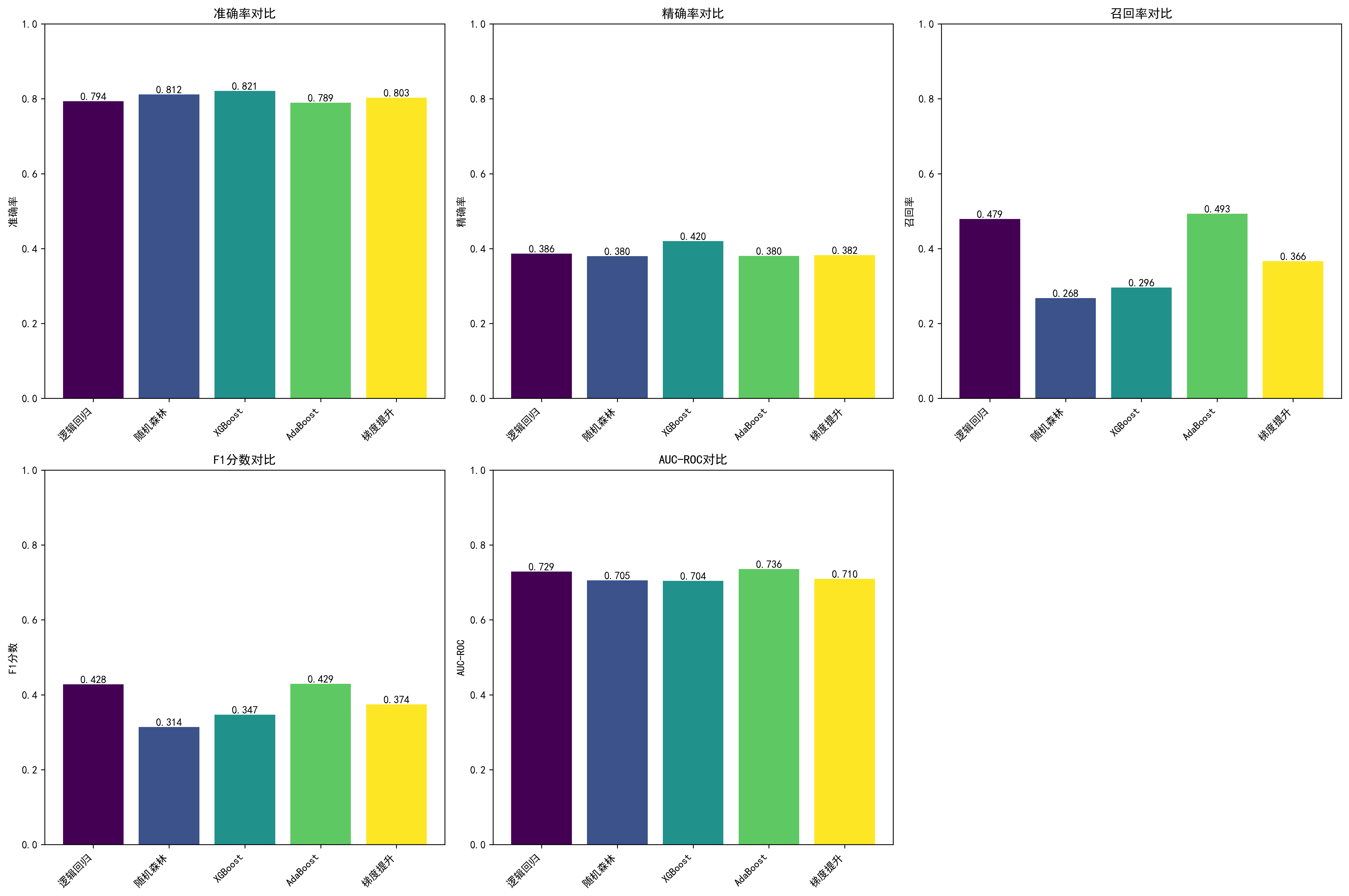
模型性能
| 模型 | 原论文 Accuracy | AI Accuracy | 原论文 AUC | AI AUC | 原论文来源 |
|---|---|---|---|---|---|
| AdaBoost | 90.82% | 78.91% | — | 0.7359 | Abstract |
| Random Forest | 86.05% | 81.18% | — | 0.7054 | Snippet |
| XGBoost | 未单独报告 | 82.09% | — | 0.7044 | — |
| Logistic Regression | 未单独报告 | 79.37% | — | 0.7289 | — |
| Gradient Boosting | 未单独报告 | 80.27% | — | 0.7097 | — |
性能差距分析:
AdaBoost 准确率差距达 11.91 个百分点(90.82% vs 78.91%),Random Forest 差距约 4.87 个百分点。差距来源:
- 过采样策略:原论文使用 ADASYN(自适应合成过采样),在困难样本邻域生成更多合成样本;AI 使用标准 SMOTE,对所有少数类样本均匀生成合成数据,针对性不足
- 超参数优化:原论文使用 TPE 进行贝叶斯超参数搜索,AI 使用 scikit-learn 默认参数,模型潜力未充分释放
- 训练/测试划分:原论文可能采用不同的划分策略或交叉验证方案,具体细节需参考原文全文
- 缺失模型:原论文最佳模型 Histogram Gradient Boosting 未被复现
尽管存在准确率差距,AI 复现中 AdaBoost 在 AUC(0.7359)和 F1 指标上表现最佳,这与原论文 AdaBoost 综合表现优异的结论方向一致。
特征重要性排序对比
| 排名 | 原论文 SHAP 排序 | AI 复现 SHAP 排序 | SHAP 值 | 是否匹配 |
|---|---|---|---|---|
| 1 | OverTime | StockOptionLevel | 0.093 | ✗ |
| 2 | JobLevel | JobInvolvement | 0.040 | ✗ |
| 3 | JobSatisfaction | YearsWithCurrManager | 0.038 | ✗ |
| 4 | — | JobSatisfaction | 0.037 | ○(原论文 #3) |
| 5 | — | WorkLifeBalance | 0.036 | — |
注:原论文 SHAP 排序来源于摘要部分,仅提及前三位(OverTime、JobLevel、JobSatisfaction)。
关键发现:特征重要性排序差异显著。AI 复现中 StockOptionLevel(SHAP=0.093)以较大优势排名第一,而原论文中 OverTime 排名第一。JobSatisfaction 在两边均进入前列(原论文 #3,AI #4),但排序位置不同。
差异原因分析:
- 过采样方法不同:ADASYN 与 SMOTE 生成的合成样本分布不同,直接影响模型学到的特征权重
- 超参数差异:不同的模型参数会改变特征的相对贡献
- OverTime 未进入 AI 前五:这是最值得关注的分歧点,可能需要领域专家进一步调查编码方式和数据预处理流程的差异
描述性统计一致性
两边在基础数据特征上保持一致:
- 离职率均为约 16%(约 237/1470)
- 加班、低满意度、低收入均被识别为离职风险因素
- 数据集基本特征(样本量、特征数)完全一致
AI 做到了什么
- 10 分钟内完成 5 种分类模型的训练与评估
- 生成 SHAP 全局特征重要性排序 + 局部单样本解释
- 产出 5 张可视化图表(模型对比、SHAP bar chart、beeswarm plot 等)
- 自动完成数据预处理与 SMOTE 过采样
- 确认了 AdaBoost 在综合指标上的优势地位,与原论文方向一致
AI 没做到什么
- 未实现 ADASYN 过采样:原论文使用 ADASYN 而非 SMOTE,这是导致准确率差距的核心因素之一
- 未使用 TPE 超参数优化:默认超参数 vs 贝叶斯优化,直接导致模型性能未充分释放
- 未测试 Histogram Gradient Boosting:这是原论文中表现最佳的模型,AI 复现完全缺失
- 未进行多数据集验证:原论文在多个数据集上验证了方法的泛化性
- SHAP 特征排序与原论文显著不同:StockOptionLevel vs OverTime 作为最重要特征,这一分歧需要领域专家深入调查
- 未进行公平性分析:原论文提及的 fairness analysis 未被复现
结论
AI 在 10 分钟内建立了一个合理的基线复现。核心发现——AdaBoost 在召回率和 F1 上综合表现最佳——与原论文方向部分一致。
但两个显著差异值得关注:一是准确率差距(AdaBoost 90.82% vs 78.91%),二是 SHAP 特征重要性排序的分歧(StockOptionLevel vs OverTime 作为首要因素)。前者主要归因于过采样策略和超参数优化的差异,后者则需要更深入的方法论对比。
这一差距恰好说明了研究者专业判断的价值:过采样策略的选择(ADASYN vs SMOTE)、超参数搜索空间的设计(TPE)、以及多数据集交叉验证,都是 AI 自动化流程难以替代的研究决策。AI 提供快速基线,研究者提供方法创新。