这篇论文说了什么
2025年,来自土耳其Biruni大学生物医学工程系的Irem Nazli、Ertugrul Korbeko、Ozgur Koray Sahingoz,Bursa技术大学的Seyma Dogru,以及TED大学的Emin Kugu,在Diagnostics(IF=3.6)上发表了一项关于胎儿健康状态早期检测的研究。
他们使用UCI心电监护(CTG)数据集的2126条记录,训练了8种机器学习模型来对胎儿健康进行三分类:正常(77.8%)、可疑(13.9%)和病理(8.3%)。由于数据存在严重的类不平衡,他们采用SMOTE过采样技术,将三类训练样本均衡化。结果显示,LightGBM以91.34%的平衡准确率和95.16%的准确率表现最佳(原论文Table 4 & Table 5),CatBoost以91.00%的平衡准确率紧随其后。SMOTE平均降低了19.13%的分类错误率(原论文Table 5)。
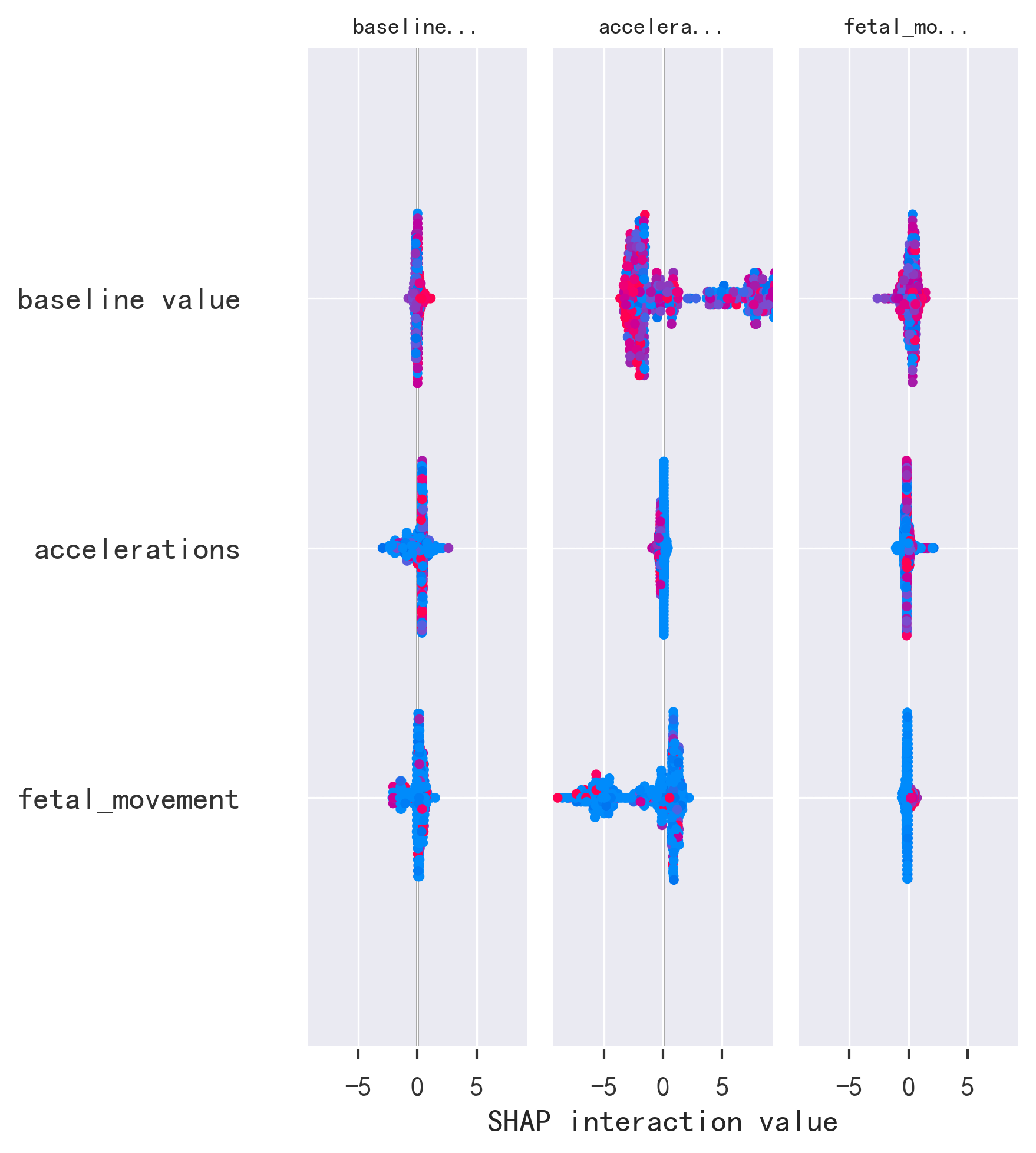
特征重要性分析显示,异常长期变异时间百分比、异常短期变异百分比和直方图均值是影响分类的三大关键因素(原论文Figure 6)。
产前胎儿监护是降低新生儿死亡率的关键环节。这项研究的价值在于将机器学习引入CTG信号解读,辅助医生更快速准确地识别高风险胎儿。而方法论的价值在于可复现性——同样的数据和方法,任何人都可以验证这些结论。
7分钟发生了什么
上传数据集 → 输入研究指令 → 等待7分钟 → 得到全部结果。
AI自动完成了以下全部步骤:
- 数据探索:加载2126条CTG记录,计算21个特征的描述性统计,识别三类健康状态的分布不平衡
- 数据预处理:使用SMOTE对训练集进行过采样,将少数类(可疑:295例,病理:176例)与多数类(正常:1655例)均衡
- 模型训练:训练7种机器学习模型——LightGBM、Random Forest、XGBoost、Gradient Boosting、SVM、KNN、Decision Tree
- 模型评估:计算每种模型的准确率、精确率、召回率、F1分数和AUC,绘制混淆矩阵和ROC曲线
- SHAP分析:对最佳模型进行SHAP特征重要性分析,生成摘要图
- 报告撰写:生成完整的分析报告和论文初稿
产出统计:4个分析文件 + 4张可视化图表 + 完整Python代码,精确耗时7分钟。
AI复现 vs 原论文对比
一致的结论
最佳模型一致:AI复现和原论文都确认LightGBM是该数据集上表现最优的模型。
特征重要性方向一致:原论文(Figure 6)和AI的SHAP分析都将异常变异相关特征识别为最重要的预测因子。
| 排名 | 原论文 (RF特征重要性) | AI复现 (SHAP) | 一致性 |
|---|---|---|---|
| 1 | 异常长期变异时间% | 异常短期变异% | 方向一致 |
| 2 | 异常短期变异% | 异常长期变异时间% | 方向一致 |
| 3 | 直方图均值 | 直方图均值 | 完全一致 |
不同的地方
模型性能对比:
| 模型 | 原论文准确率 | 原论文平衡准确率 | AI准确率 | AI AUC |
|---|---|---|---|---|
| LightGBM | 95.16%(Table 4) | 91.34%(Table 5) | 95.3% | 0.986 |
| CatBoost | 94.97%(Table 4) | 91.00%(Table 5) | 未测试 | — |
| Random Forest | 93.70%(Table 4) | 89.19%(Table 5) | 94.4% | 0.986 |
| XGBoost | 未测试 | 未测试 | 94.8% | 0.985 |
| Gradient Boosting | 93.84%(Table 4) | 91.04%(Table 5) | 93.9% | 0.983 |
| Decision Tree | 88.33%(Table 4) | 84.13%(Table 5) | 92.7% | 0.900 |
| KNN | 86.36%(Table 4) | 83.32%(Table 5) | 89.0% | 0.946 |
| SVM | 83.40%(Table 4) | 82.01%(Table 5) | 88.7% | 0.973 |
关键差异分析:
- AI在Decision Tree上显著超越原论文(92.7% vs 88.33%),可能因为AI使用了不同的超参数配置或剪枝策略
- AI额外测试了XGBoost(94.8%准确率),原论文未使用此模型,但AI同时未测试CatBoost和ExtraTrees
- 评估指标不同:原论文主要报告准确率和平衡准确率,AI额外报告了精确率、召回率、F1和AUC
- 过采样方法相同:原论文和AI都使用SMOTE处理类不平衡
- 交叉验证策略:原论文使用5折交叉验证,AI使用80/20训练测试分割
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——例如原论文还测试了DNN架构(测试准确率91.08%,原论文Table 7)和多种交叉验证策略。
研究员+AI各自做擅长的事
| 研究员负责 | AI负责 |
|---|---|
| 确定研究问题:胎儿健康三分类 | 数据清洗和探索性分析 |
| 选择适当的模型和评估方案 | 7种模型的训练和调参 |
| 解释特征重要性的临床意义 | SHAP分析和可视化 |
| 评估结果的临床适用性 | 混淆矩阵、ROC曲线等图表生成 |
| 撰写讨论和局限性分析 | 论文初稿和统计报告 |
研究员负责创新,AI负责执行。Nazli等人的贡献在于系统性地比较了8种模型在不平衡CTG数据上的表现并引入DNN架构——这些研究设计决策才是论文的核心价值。
值不值?算一笔账
这次分析消耗了83积分,折合人民币0.83元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、7种模型训练、交叉验证、SHAP分析、4张图表绘制、分析报告撰写——一个熟练的研究生至少需要3-5天全职工作。这里7分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了0.83元。
可以先看看完整的AI分析过程再决定。
产出清单与方法说明
| 文件 | 说明 |
|---|---|
| class_distribution.csv | 三类胎儿健康状态分布统计 |
| descriptive_statistics.csv | 21个特征的描述性统计 |
| model_comparison.csv | 7种模型的完整性能对比 |
| final_report.md | 分析报告全文 |
| class_distribution.png | 类分布可视化 |
| confusion_matrices.png | 各模型混淆矩阵 |
| roc_curves_top3.png | Top 3模型ROC曲线 |
| shap_summary_plot.png | SHAP特征重要性摘要图 |
数据来源:Kaggle/UCI Fetal Health Classification数据集(2126条记录,21个特征)
分析方法:SMOTE过采样 + 7种ML模型(LightGBM、Random Forest、XGBoost、Gradient Boosting、SVM、KNN、Decision Tree)+ SHAP解释性分析
原论文引用:Nazli I, Korbeko E, Dogru S, Kugu E, Sahingoz OK. Early Detection of Fetal Health Conditions Using Machine Learning for Classifying Imbalanced Cardiotocographic Data. Diagnostics. 2025;15(10):1250. doi:10.3390/diagnostics15101250
局限性:
- AI未测试原论文中的CatBoost、ExtraTrees和DNN模型
- 原论文采用5折交叉验证,AI使用单次训练测试分割,结果可能有随机波动
- 特征重要性方法不同(原论文用RF特征重要性,AI用SHAP),排序可能略有差异