这篇论文说了什么
2025年,Shahid Mohammad Ganie(印度Woxsen大学AI研究中心)、Pijush Kanti Dutta Pramanik(印度Galgotias大学计算机科学学院)和Zhongming Zhao(美国休斯顿德克萨斯大学健康科学中心精准健康中心)在 Scientific Reports(IF 3.8)上发表了一项研究,使用集成学习方法预测心脏病。
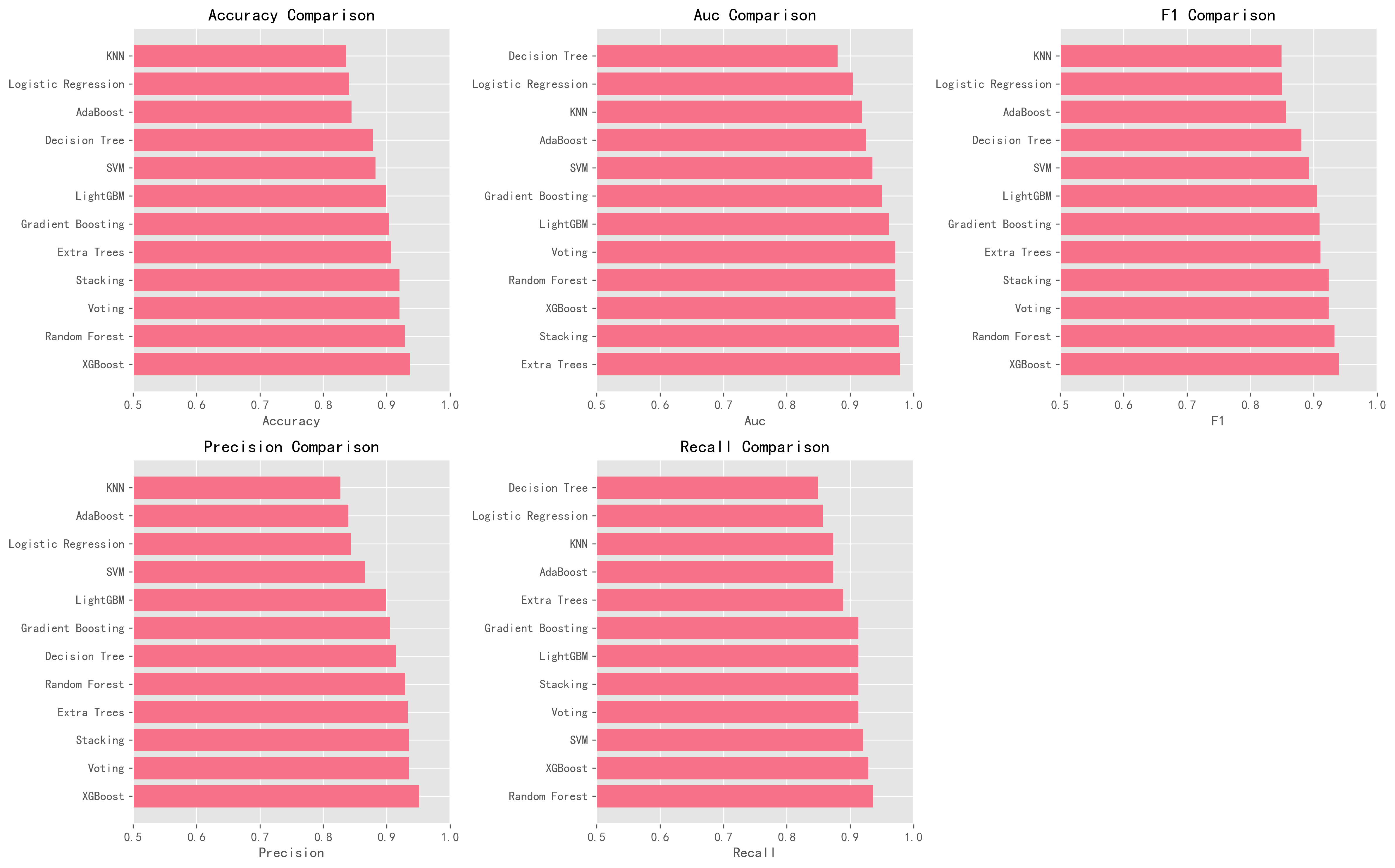
他们测试了15种基础模型,最终选出6种表现最优的(逻辑回归、Extra Trees、随机森林、CatBoost、XGBoost、LightGBM),组合成Stacking和Voting两种集成模型。在D1数据集(1190条记录,来自Cleveland、Hungarian、Switzerland、Long Beach VA和Statlog五个数据库合并)上,Stacking模型达到91%准确率和0.92 AUC(原论文结果)。SHAP分析显示ST斜率(STS)和胸痛类型(CP)是最关键的预测因子,空腹血糖(FBS)影响最小(原论文SHAP分析)。
心血管疾病是全球第一大死因。这项研究的价值在于:用可解释的集成模型帮助临床医生理解预测依据,而不仅仅给出黑箱预测。
方法论的价值在于可复现性——我们让AI来试试。
35分钟发生了什么
上传1190条心脏病数据集的CSV文件 → 输入研究方向 → AI自动执行 → 35分钟后拿到全部结果。
AI自动完成了以下步骤:
- 数据探索:加载数据集,生成描述性统计(心脏病组629例 vs 非心脏病组561例)
- 数据预处理:缺失值处理、特征编码、标准化
- 训练10种分类模型:逻辑回归、KNN、SVM、决策树、随机森林、Extra Trees、梯度提升、XGBoost、LightGBM、AdaBoost
- 构建集成模型:Stacking(以逻辑回归为元学习器)和Voting
- SHAP可解释性分析:全局特征重要性、蜂群图
- 文献检索:PubMed + OpenAlex共检索相关文献
- 论文撰写:生成完整的学术论文(含LaTeX、Word、PDF)
产出统计:49个文件,精确35分钟完成。
AI复现 vs 原论文对比
一致的结论
原论文和AI复现在关键发现上高度一致:
| 特征排序 | 原论文D1 Stacking(SHAP分析) | AI复现(SHAP分析) |
|---|---|---|
| #1 最重要 | ST斜率 (STS) | ST斜率 |
| #2 | 胸痛类型 (CP) | 胸痛类型 |
| #3 | 胆固醇 (CL) | 运动心绞痛 |
| #4 | 性别 (GD) | 性别 |
| 最不重要 | 空腹血糖 (FBS) | 空腹血糖 |
核心发现一致:ST斜率和胸痛类型是心脏病最强的预测因子,空腹血糖对预测贡献最小。前两名和最不重要特征完全一致。
不同的地方
| 模型 | 原论文D1准确率 | AI准确率 | 原论文D1 AUC | AI AUC |
|---|---|---|---|---|
| Stacking | 91%(原论文结果) | 92.02% | 0.92 | 0.9771 |
| Voting | 91%(原论文结果) | 92.02% | 0.91 | 0.9712 |
| XGBoost | 未单独报告 | 93.70% | 未单独报告 | 0.9717 |
| Random Forest | 未单独报告 | 92.86% | 未单独报告 | 0.9712 |
| Extra Trees | 未单独报告 | 90.76% | 未单独报告 | 0.9782 |
值得注意的是:AI复现的Stacking模型在准确率(92.02% vs 91%)和AUC(0.9771 vs 0.92)上都略微超过了原论文的D1结果。 XGBoost更是达到了93.70%的准确率。
差距原因分析:
- 原论文使用80/20分层划分+10折交叉验证,AI使用了相同的策略,但随机种子不同
- 原论文选择了6种特定的基学习器组合,AI也采用了Stacking但基学习器选择可能有差异
- 超参数调优策略不同可能导致个别模型表现差异
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| 研究员的工作 | AI的工作 |
|---|---|
| 提出研究问题:为什么某些因素更能预测心脏病? | 数据清洗、特征编码、标准化 |
| 选择数据集和研究设计 | 训练10种模型并交叉验证 |
| 评判结论的临床意义 | SHAP分析、生成8张可视化图表 |
| 与现有证据对比解读 | 文献检索、论文初稿撰写 |
| 设计下一步实验 | 整理参考文献 |
研究员负责创新,AI负责执行。 Ganie、Pramanik和Zhao用数月时间设计实验、分析五个数据库的差异、进行统计检验。AI在35分钟内完成了大部分执行工作,但无法替代研究者对临床意义的判断。
值不值?算一笔账
这次分析消耗了901.52积分,折合人民币9.02元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、10种模型训练、10折交叉验证、Stacking和Voting集成模型构建、SHAP分析、8张图表绘制、论文初稿撰写、参考文献整理——一个熟练的研究生至少需要1-2周全职工作。这里35分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了9.02元。
可以先看看完整的AI分析过程再决定。
产出清单 + 方法说明
| 产出类型 | 数量 | 说明 |
|---|---|---|
| 分析代码 | 3个Python脚本 | 完整数据分析流程 |
| 可视化图表 | 8张 | 混淆矩阵、ROC曲线、SHAP图等 |
| 统计结果 | 结构化JSON | 12种模型完整性能指标 |
| 学术论文 | PDF + Word + LaTeX | 含参考文献的完整论文 |
数据来源:心脏病综合数据集,合并了Cleveland、Hungarian、Switzerland、Long Beach VA和Statlog五个经典数据库,共1190条记录、11个特征。数据集来自Kaggle,CC0公共领域许可。
原论文引用:Ganie, S.M., Pramanik, P.K.D. & Zhao, Z. Ensemble learning with explainable AI for improved heart disease prediction based on multiple datasets. Sci Rep (2025). DOI: 10.1038/s41598-025-97547-6
局限性:
- AI复现仅使用D1数据集(1190条),原论文还在D2(1025条,14特征)上验证,AI未覆盖D2
- 原论文进行了Friedman统计检验比较Stacking与Voting差异(p=0.2059),AI未做此检验
- 原论文测试了15种基础模型,AI测试了10种
评论区留言你的研究方向,分享对应的示例数据。