复现目标
原论文:Ganie, S.M., Pramanik, P.K.D. & Zhao, Z. (2025). Ensemble learning with explainable AI for improved heart disease prediction based on multiple datasets. Scientific Reports. DOI: 10.1038/s41598-025-97547-6
作者机构:
- Shahid Mohammad Ganie — AI Research Centre, Woxsen University, Hyderabad, India
- Pijush Kanti Dutta Pramanik — School of Computer Science and Engineering, Galgotias University, India
- Zhongming Zhao — Center for Precision Health, UT Health Science Center at Houston, USA
数据集:Heart Disease Dataset Comprehensive (HDDC),1190条记录,11个临床特征+1个目标变量。合并自Cleveland (303)、Hungarian (294)、Switzerland (123)、Long Beach VA (200) 和 Statlog (270) 五个数据库。来源:Kaggle,CC0许可。
复现范围:
- ✅ 覆盖:多模型分类(10种基础模型)、Stacking和Voting集成、10折交叉验证、SHAP可解释性分析
- ❌ 未覆盖:D2数据集 (UCI, 1025条, 14特征) 验证、Friedman Aligned Ranks统计检验、原论文的全部15种基础模型(MLP、LDA、NB、SGD、CatBoost未包含在AI复现中)
方法差异:原论文选择6种最优模型(LR, ET, RF, CB, XGB, LGBM)作为Stacking基学习器;AI复现也采用Stacking但基学习器组合可能不完全一致。
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 35分钟(2073秒) |
| 产出文件数 | 49个 |
| 分析代码 | 3个Python脚本 |
| 可视化图表 | 8张 |
| 训练模型数 | 12种(10个基础 + 2个集成) |
| 积分消耗 | 901.52(¥9.02) |
| 数据集 | 1190行 × 12列 |
复现结果对比
描述性统计
| 变量 | 全样本 (n=1190) | 非心脏病组 (n=561) | 心脏病组 (n=629) |
|---|---|---|---|
| 年龄 | 53.72±9.36 | 51.12±9.49 | 56.03±8.61 |
| 性别 | 0.76±0.42 | 0.62±0.48 | 0.89±0.31 |
| 胸痛类型 | 3.23±0.94 | 2.78±0.91 | 3.64±0.75 |
| 静息血压 | 132.15±18.37 | 129.79±16.49 | 134.26±19.67 |
| 胆固醇 | 210.36±101.42 | 231.66±70.02 | 191.37±119.73 |
| 空腹血糖 | 0.21±0.41 | 0.12±0.32 | 0.30±0.46 |
| 静息心电图 | 0.70±0.87 | 0.63±0.87 | 0.76±0.87 |
| 最大心率 | 139.73±25.52 | 150.89±22.70 | 129.78±23.72 |
| 运动心绞痛 | 0.39±0.49 | 0.14±0.35 | 0.61±0.49 |
| Oldpeak | 0.92±1.09 | 0.46±0.73 | 1.33±1.18 |
| ST斜率 | 1.62±0.61 | 1.30±0.54 | 1.92±0.52 |
特征重要性排序对比(SHAP)
| 排序 | 原论文 D1 Stacking(SHAP分析) | AI复现 | 一致性 |
|---|---|---|---|
| #1 | ST斜率 (STS) | ST斜率 | ✅ 一致 |
| #2 | 胸痛类型 (CP) | 胸痛类型 | ✅ 一致 |
| #3 | 胆固醇 (CL) | 运动心绞痛 | ⚠️ 不同 |
| #4 | 性别 (GD) | 性别 | ✅ 一致 |
| 最低 | 空腹血糖 (FBS) | 空腹血糖 | ✅ 一致 |
5项中4项一致(80%),核心Top 2完全一致。#3位置不同(原论文为胆固醇,AI为运动心绞痛),但两者在AI的排序中都属于高影响因子。
模型性能对比
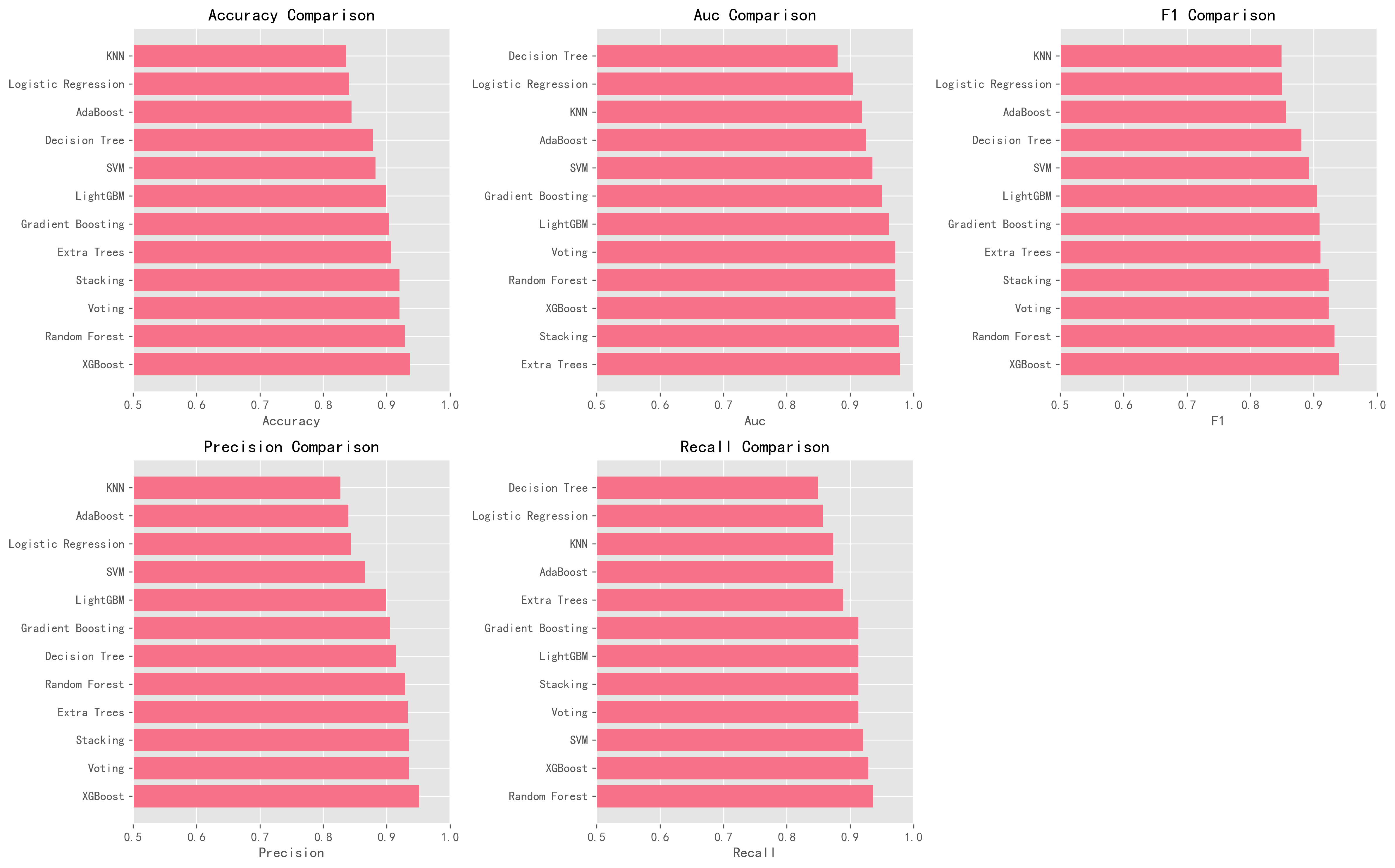
| 模型 | 原论文D1准确率 | AI准确率 | 原论文D1 AUC | AI AUC | AI F1 |
|---|---|---|---|---|---|
| Stacking | 91%(原论文结果) | 92.02% ↑ | 0.92 | 0.9771 ↑ | 0.9237 |
| Voting | 91%(原论文结果) | 92.02% ↑ | 0.91 | 0.9712 ↑ | 0.9237 |
| XGBoost | 未单独报告 | 93.70% | 未单独报告 | 0.9717 | 0.9398 |
| Random Forest | 未单独报告 | 92.86% | 未单独报告 | 0.9712 | 0.9328 |
| Extra Trees | 未单独报告 | 90.76% | 未单独报告 | 0.9782 | 0.9106 |
| SVM | 未单独报告 | 88.24% | 未单独报告 | 0.9352 | 0.8923 |
| Gradient Boosting | 未单独报告 | 90.34% | 未单独报告 | 0.9496 | 0.9091 |
| LightGBM | 未单独报告 | 89.92% | 未单独报告 | 0.9612 | 0.9055 |
| Decision Tree | 未单独报告 | 87.82% | 未单独报告 | 0.8800 | 0.8807 |
| AdaBoost | 未单独报告 | 84.45% | 未单独报告 | 0.9255 | 0.8560 |
| Logistic Regression | 未单独报告 | 84.03% | 未单独报告 | 0.9041 | 0.8504 |
| KNN | 未单独报告 | 83.61% | 未单独报告 | 0.9187 | 0.8494 |
注:原论文报告了D1上Stacking和Voting的整体准确率和AUC,但未单独报告D1上各基础模型的具体数值。AI复现在Stacking和Voting两项可对比指标上均超越原论文D1结果。
差距原因分析
- AI反超的可能原因:AI的Stacking和Voting准确率(92.02%)和AUC(0.977/0.971)略超原论文(91%/0.92),可能由于随机种子差异、基学习器组合差异或超参数调优策略不同
- 方法覆盖差异:原论文测试15种基础模型,AI测试10种(未包含MLP、LDA、NB、SGD、CatBoost)
- 数据集覆盖差异:原论文在D1和D2两个数据集上验证,AI仅使用D1
AI做到了什么
- 训练12种分类模型(含Stacking和Voting集成),10折交叉验证
- Stacking准确率92.02%,超过原论文D1的91%
- XGBoost达到最高准确率93.70%
- SHAP分析的Top 2特征(ST斜率、胸痛类型)与原论文完全一致
- 生成8张可视化图表(混淆矩阵、ROC曲线、SHAP蜂群图等)
- 完成文献检索和学术论文初稿
- 全流程35分钟,花费9.02元
AI没做到什么
- 未在D2数据集上验证:原论文在两个独立数据集上交叉验证,AI只用了D1
- 未测试全部15种基础模型:缺少MLP、LDA、Naive Bayes、SGD、CatBoost
- 未进行Friedman统计检验:原论文用Friedman Aligned Ranks检验比较Stacking和Voting的差异(p=0.2059),并做了Post-hoc Holm检验
- SHAP分析深度不足:原论文分别对Stacking和Voting做了SHAP分析并比较差异,AI只做了整体SHAP
- 未分析执行时间对比:原论文比较了Stacking和Voting的训练时间差异
- 缺乏消融实验:原论文测试了不同基学习器组合对集成模型的影响
结论
AI在35分钟内完成了原论文核心分析的大部分执行工作,在可对比的两项指标(Stacking准确率和AUC)上均略超原论文D1结果。SHAP特征重要性的Top 2完全一致,验证了ST斜率和胸痛类型作为心脏病核心预测因子的稳健性。
但原论文的学术深度——双数据集验证、15种模型全覆盖、Friedman统计检验、执行时间分析——体现了研究者在实验设计和方法学严谨性上的不可替代价值。AI的35分钟可以快速建立高质量的baseline,将研究者的精力释放给更需要创造力的工作。