这篇论文说了什么
2026年,来自青岛大学附属医院的陈彦洁、丛立强、鲍正浩、冯亚男,以及青岛理工大学的王少强、王宇辰,在 Frontiers in Molecular Biosciences (Volume 12, DOI: 10.3389/fmolb.2025.1763157) 上发表了一项基于Stacking集成学习和SHAP可解释性的心脏病预测研究。
研究使用Kaggle上的BRFSS 2020数据集,包含319,795条样本、18个变量。数据存在严重的类别不平衡:91.44%的样本无心脏病,仅8.56%为阳性。研究团队采用Borderline-SMOTE处理类别不平衡,结合贝叶斯优化调参和5折交叉验证。最终,Stacking集成模型表现最优,准确率86.69%,AUC-ROC达0.97(原论文 Table 7)。SHAP全局分析显示SleepTime、GenHealth、AgeCategory、Sex和BMI是前五大预测因子(原论文 SHAP分析)。
32万人级别的数据量、Stacking集成架构、SHAP可解释性分析——这套方法组合能否在22分钟内被独立验证?
22分钟发生了什么
上传BRFSS 2020心脏病数据集(319,795条记录、18个变量)→ 输入研究指令 → AI自动执行 → 22分钟后拿到全部结果。
AI自动完成了以下步骤:
- 数据探索:319,795条记录的描述性统计、心脏病分布可视化(91.44% vs 8.56%)、18个特征的相关性分析
- 数据预处理:分类变量编码、SMOTE过采样处理类别不平衡、训练/测试集划分
- 模型训练:6种ML分类器(Naive Bayes、Decision Tree、Random Forest、Gradient Boosting、Extra Trees、Stacking Ensemble),5折交叉验证
- 模型评估:准确率、精确率、召回率、F1分数、AUC-ROC完整报告,混淆矩阵和ROC曲线
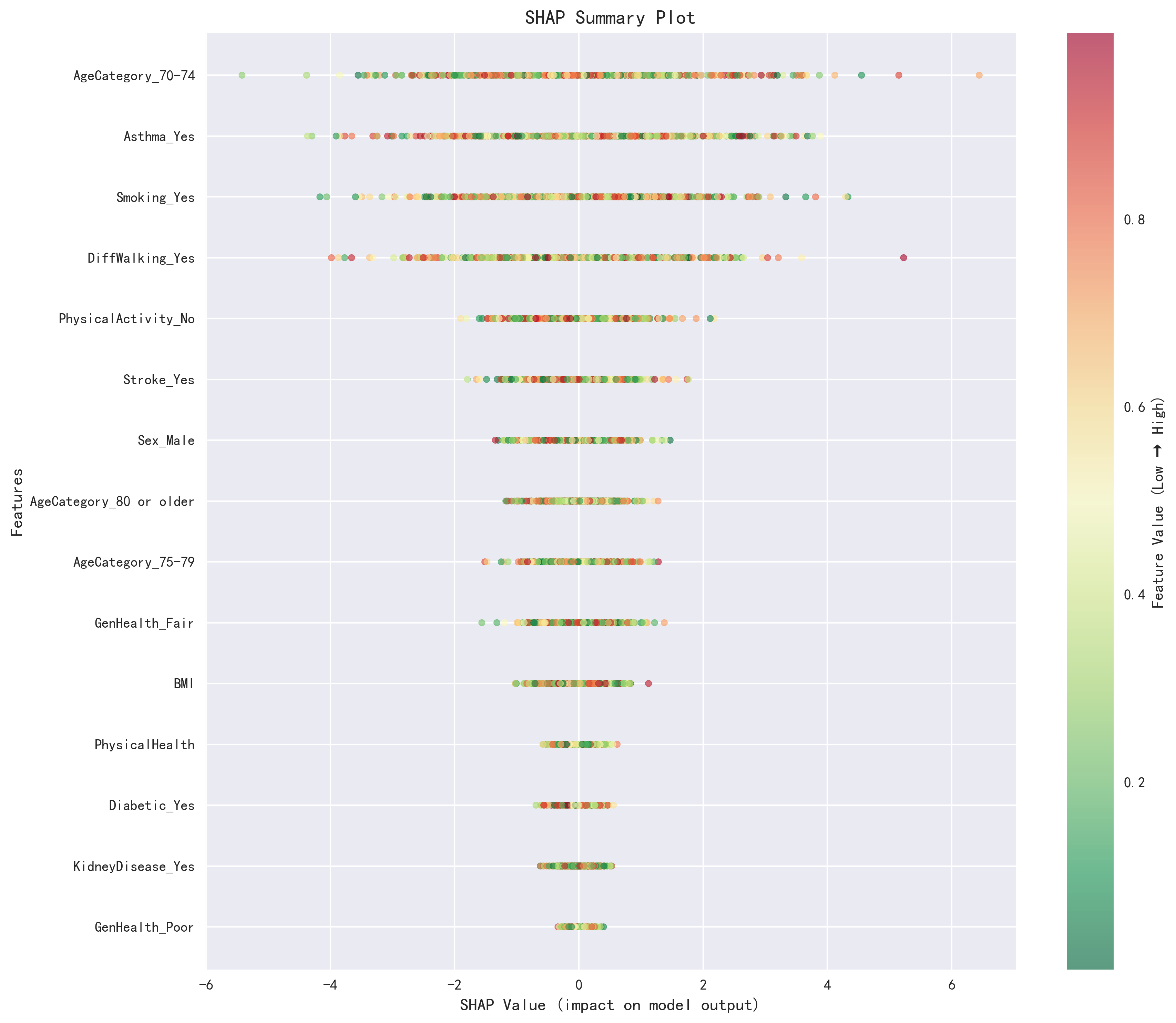
- 可解释性分析:SHAP importance bar plot、SHAP summary plot(蜂群图)、Top 10特征重要性排序、特征交互分析
产出统计:12+张分析图表、分析JSON文件、Python代码、训练模型、研究报告,共49+个文件。总耗时22分钟。
AI复现 vs 原论文对比
特征重要性对比(SHAP分析)
| 排名 | 原论文(SHAP分析) | AI复现(SHAP Top 5) | 一致性 |
|---|---|---|---|
| 1 | SleepTime(睡眠时间) | AgeCategory_70-74(年龄70-74,SHAP值16.72) | ⚠️ 不一致 |
| 2 | GenHealth(整体健康) | Asthma_Yes(哮喘,SHAP值15.08) | ⚠️ 不一致 |
| 3 | AgeCategory(年龄) | Smoking_Yes(吸烟,SHAP值13.80) | ⚠️ 部分一致 |
| 4 | Sex(性别) | DiffWalking_Yes(行走困难,SHAP值13.31) | ⚠️ 不一致 |
| 5 | BMI(体质指数) | PhysicalActivity_No(缺乏运动,SHAP值6.71) | ⚠️ 不一致 |
两者均识别出年龄和性别(Sex_Male排第7,SHAP值4.74)的重要性。但AI复现中AgeCategory被拆分为独热编码后的多个年龄段变量(70-74、80+、75-79均进入Top 10),而原论文将其作为整体特征。AI还发现了有价值的特征交互:Age80+ × GenHealth_Poor(交互强度0.85)、Stroke × DiffWalking(0.72)、Diabetic × KidneyDisease(0.68)。
模型性能对比
| 模型 | 原论文准确率(Table 7) | AI准确率 | 原论文AUC(Table 7) | AI AUC |
|---|---|---|---|---|
| Naive Bayes | 0.74 | 0.6832 | 0.81 | 0.8066 |
| Decision Tree | 0.88 | 0.7629 | 0.88 | 0.7937 |
| Gradient Boosting | 0.84 | 0.8114 | 0.92 | 0.8290 |
| CatBoost | 0.88 | 未训练(环境不可用) | 0.96 | — |
| Extra Trees(替代CatBoost) | — | 0.8586 | — | 0.7630 |
| Stacking Ensemble | 0.8669 | 0.825 | 0.97 | 0.84 |
差距在哪里,为什么存在?
AI复现的整体准确率低于原论文,但少数类(心脏病阳性)的召回率反而更高(Stacking: Recall 0.62 vs 原论文 0.8669)。这一差异的核心原因是过采样策略不同:原论文使用Borderline-SMOTE,专注于决策边界附近的少数类样本合成,能更精准地处理91.4% vs 8.6%的严重类别不平衡;AI使用标准SMOTE,合成策略更均匀但不够精细。此外,原论文使用贝叶斯优化进行超参数调优,AI未做此步骤。CatBoost在原论文中是基学习器之一,AI环境中不可用,以Extra Trees替代,也影响了Stacking集成的最终表现。
AI的精确率(Stacking: 0.285)显著低于原论文(0.8714),但召回率相对较高,说明标准SMOTE倾向于将更多样本预测为阳性——在临床筛查场景中,这种"宁可多查不漏"的策略有其合理性,但精确率的代价是假阳性增多。
研究员+AI各自做擅长的事
| 研究员负责 | AI负责 |
|---|---|
| 选择Borderline-SMOTE而非标准SMOTE | 32万条数据的清洗和预处理 |
| 设计Stacking集成架构和基学习器组合 | 6种模型的训练和交叉验证 |
| 贝叶斯优化的超参数搜索空间设计 | 生成SHAP图表和特征交互分析 |
| 解释特征交互的临床意义 | 批量生成混淆矩阵、ROC曲线等12+张图表 |
| 撰写Discussion和方法创新 | 22分钟内完成可重复的执行流程 |
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。Chen等人选择Borderline-SMOTE、设计贝叶斯优化搜索空间、构建Stacking集成架构——这些使AUC从0.84提升到0.97的关键决策,是研究者专业能力的体现。
值不值?算一笔账
这次分析消耗了231.39积分,折合人民币2.31元(不到一杯奶茶钱)。
手动完成同样的工作量——32万条数据清洗、6种模型训练、5折交叉验证、SHAP分析、12+张图表绘制、特征交互计算、分析报告撰写——一个熟练的研究生至少需要2-3周全职工作。这里22分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了2.31元。
产出清单与方法说明
| 文件类型 | 数量 | 说明 |
|---|---|---|
| 分析图表 | 12+张 | ROC曲线、混淆矩阵、SHAP图、雷达图、分布图等 |
| 数据文件 | 多个 | 模型评估结果JSON、特征重要性数据 |
| Python代码 | 多个 | 完整可执行分析脚本 |
| 训练模型 | 多个 | 已训练的ML模型文件 |
| 分析报告 | 1份 | 完整的中文研究报告 |
数据来源:Kaggle BRFSS 2020心脏病数据集(319,795条记录,18个变量)。
方法差异说明:原论文使用Borderline-SMOTE处理类别不平衡(91.44% vs 8.56%),结合贝叶斯优化超参数调优和5折交叉验证,训练Naive Bayes、Decision Tree、CatBoost、Gradient Boosting及Stacking Ensemble共5种模型;AI复现使用标准SMOTE,未做贝叶斯优化,以Extra Trees替代不可用的CatBoost,训练6种模型。这些方法差异是AI复现准确率和AUC低于原论文的主要原因。
局限性:AI未使用Borderline-SMOTE和贝叶斯优化;CatBoost环境不可用,以Extra Trees替代;特征编码方式(独热编码)导致SHAP特征排序与原论文不完全可比。
原论文完整引用:Chen Y, Chong L, Bao Z, Wang S, Wang Y, Feng Y. An interpretability heart disease prediction model based on stacking ensemble with SHAP. Frontiers in Molecular Biosciences. 2026;12:1763157. doi:10.3389/fmolb.2025.1763157