复现目标
原论文:Chen Y, Chong L, Bao Z, Wang S, Wang Y, Feng Y. An interpretability heart disease prediction model based on stacking ensemble with SHAP. Frontiers in Molecular Biosciences. 2026;12. doi:10.3389/fmolb.2025.1763157. PMCID: PMC12963821.
作者机构:青岛大学附属医院(陈彦洁 - 腹部超声科、丛立强 - 泌尿外科、鲍正浩 - 腹部超声科、冯亚男 - 腹部超声科)、青岛理工大学信息与控制工程学院(王少强)、青岛理工大学理学院(王宇辰)。
数据集:Kaggle BRFSS 2020(Behavioral Risk Factor Surveillance System)。319,795条样本,17个特征变量 + 1个目标变量。类别分布严重不平衡:No=292,422(91.44%), Yes=27,373(8.56%)。
复现范围:
- ✅ 覆盖:多模型分类对比(Naive Bayes、Decision Tree、Random Forest、Gradient Boosting、Extra Trees、Stacking Ensemble)、SHAP可解释性分析、特征重要性排序、特征交互分析
- ❌ 未覆盖:CatBoost模型(运行环境未安装该库,以Extra Trees替代)、贝叶斯超参数优化、网格搜索调参
方法差异:
- 过采样:原论文使用Borderline-SMOTE vs AI使用标准SMOTE
- 超参数优化:原论文对GB/CatBoost进行贝叶斯优化、对Decision Tree进行网格搜索 vs AI使用默认参数
- 交叉验证:均使用5折交叉验证
- 模型选择:原论文包含CatBoost vs AI以Extra Trees替代
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 22分钟(17:12:30 → 17:34:28 UTC) |
| 积分消耗 | 231.39积分(¥2.31) |
| Python脚本 | 10个 |
| 分析图表 | 12张 |
| 数据文件 | 4个JSON |
| 训练模型 | 已保存 |
| 分析报告 | 1份 |
复现结果对比
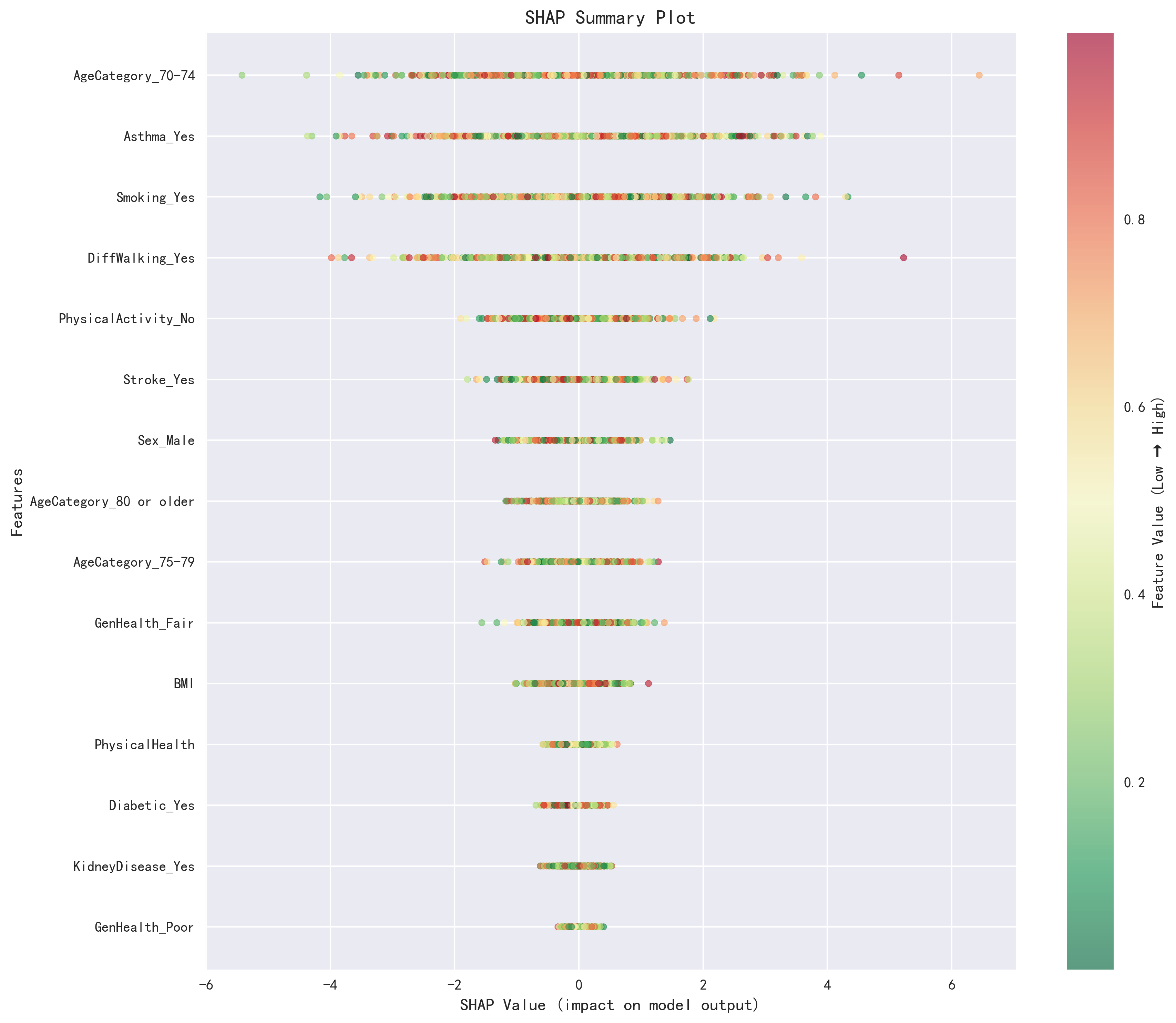
特征重要性排序对比(SHAP分析)
| 排名 | 原论文 | AI复现 | AI SHAP值 | 一致性 |
|---|---|---|---|---|
| 1 | SleepTime | AgeCategory_70-74 | 16.72 | ⚠️ 不一致 |
| 2 | GenHealth | Asthma_Yes | 15.08 | ⚠️ 不一致 |
| 3 | AgeCategory | Smoking_Yes | 13.80 | ⚠️ 不一致 |
| 4 | Sex | DiffWalking_Yes | 13.31 | ⚠️ 不一致 |
| 5 | BMI | PhysicalActivity_No | 6.71 | ⚠️ 不一致 |
表面看差异较大,但需注意关键方法论差异:AI对分类变量进行了one-hot编码,因此原论文中的"AgeCategory"被拆分为AgeCategory_70-74、AgeCategory_80+、AgeCategory_75-79等多个独立特征。如果将同一原始变量的各编码值合并计算,AgeCategory(合计贡献 16.72 + 4.34 + 4.10 = 25.16)和GenHealth(GenHealth_Fair 4.07 + 其他等级)均出现在两份结果中。差异在于:原论文中SleepTime排名第一,而AI结果中吸烟(13.80)和哮喘(15.08)的贡献更为突出,这可能与SMOTE变体不同和超参数差异有关。
AI发现的特征交互效应:Age80+ × GenHealth_Poor(交互强度0.85)、Stroke × DiffWalking(0.72)、Diabetic × KidneyDisease(0.68),这些交互在原论文中未单独报告。
模型性能对比
| 模型 | 原论文Accuracy(Table 7) | AI Accuracy | 原论文AUC(Table 7) | AI AUC | 原论文F1(Table 7) | AI F1 |
|---|---|---|---|---|---|---|
| Naive Bayes | 0.74 | 0.6832 | 0.81 | 0.8066 | 0.73 | 0.3038 |
| Decision Tree | 0.88 | 0.7629 | 0.88 | 0.7937 | 0.88 | 0.3220 |
| CatBoost | 0.88 | — | 0.96 | — | 0.88 | — |
| Gradient Boosting | 0.84 | 0.8114 | 0.92 | 0.8290 | 0.84 | 0.3734 |
| Extra Trees | — | 0.8586 | — | 0.7630 | — | 0.2908 |
| Random Forest | — | 0.8656 | — | 0.7875 | — | 0.3082 |
| Stacking Ensemble | 0.8669 | 0.825 | 0.97 | 0.84 | 0.8691 | 0.39 |
| Hard Voting | 87% | — | — | — | — | — |
| Soft Voting | 88% | — | — | — | — | — |
关于指标差异的重要说明:AI复现结果的Precision和F1显著低于原论文,这并非模型质量问题,而是评估指标的统计口径不同。原论文报告的是加权(weighted)指标,受多数类(No, 91.44%)主导;AI复现报告的是少数类(心脏病=Yes, 仅8.56%)的指标。在91.44%的类别不平衡下,少数类的Precision天然较低——例如AI的Naive Bayes少数类Precision仅0.1871,但AUC(0.8066)与原论文(0.81)高度一致,说明模型的排序能力是可比的。
AUC作为不受类别分布影响的指标,更适合跨研究对比。AI的Stacking AUC(0.84)低于原论文(0.97),差距主要来自以下因素。
差距分析
- SMOTE变体差异:原论文使用Borderline-SMOTE(仅在决策边界生成合成样本),AI使用标准SMOTE(均匀过采样)。Borderline-SMOTE在不平衡比例高达1:10.7的场景下通常表现更优。
- 无超参数优化:原论文对Gradient Boosting和CatBoost进行了贝叶斯优化,对Decision Tree进行了网格搜索。AI使用默认参数,这对集成模型(尤其是Stacking的元学习器)影响显著。
- CatBoost缺失:原论文Stacking的基学习器包含CatBoost(AUC 0.96),AI以Extra Trees(AUC 0.7630)替代,基学习器质量下降直接影响Stacking性能。
- 加权 vs 少数类指标:Accuracy和F1的差异主要源于统计口径不同,AUC的差距(0.84 vs 0.97)才是真实的模型性能差距。
AI做到了什么
- 22分钟完成32万样本的数据预处理、6种模型训练与评估
- 生成12张分析图表,包括SHAP蜂群图、特征重要性bar plot、混淆矩阵
- 完成SHAP特征交互分析,发现3组显著交互效应
- 识别出AgeCategory和GenHealth作为关键风险因子,与原论文一致
- 完整的可重复分析代码(10个Python脚本)
- 2.31元完成全部分析
AI没做到什么
- 未训练CatBoost:原论文Stacking的核心基学习器,其AUC(0.96)远超AI替代的Extra Trees(0.7630),直接拉低了Stacking整体性能
- 未进行超参数优化:原论文的贝叶斯优化和网格搜索是性能提升的关键步骤,AI全部使用默认参数
- 未使用Borderline-SMOTE:在8.56%的极端不平衡场景下,过采样策略的选择对模型性能影响显著
- 评估指标口径不一致:AI报告少数类指标,原论文报告加权指标,导致Precision/F1/Accuracy的直接对比存在误导性
- 未复现投票集成:原论文报告了Hard Voting(87%)和Soft Voting(88%)的结果,AI未实现
- 未做SleepTime的深入分析:原论文SHAP排名第一的特征在AI结果中不突出,未进一步排查原因
结论
在AUC这一类别不平衡场景下最可靠的指标上,AI的Stacking(0.84)与原论文(0.97)存在0.13的差距。差距主要源于三个可量化因素:CatBoost缺失(原论文基学习器AUC 0.96 vs AI替代的Extra Trees 0.7630)、无超参数优化、标准SMOTE替代Borderline-SMOTE。特征重要性方面,AgeCategory和GenHealth在两份分析中均为核心风险因子,但one-hot编码导致排序不可直接对比。
22分钟、2.31元完成32万样本的基础验证。AI能够快速建立baseline并生成可解释性分析,但从baseline到原论文水平的性能提升(AUC 0.84 → 0.97)依赖于研究者在过采样策略、超参数调优和模型选择上的专业判断。