这篇论文说了什么
2026年3月,来自孟加拉国 Noakhali Science and Technology University 的 Nazmun Nahar、Sanjatul Hasan Siam、Joy Bhowmik、Ayesha Nasrin Ripa、Md Hasan Imam,以及马来西亚 Universiti Malaya 的 Haw Jiunn Woo、沙特 Taif University 的 Hamid Osman、马来西亚 Sunway University 的 Mayeen Uddin Khandaker 和 Shams Forruque Ahmed,在 Analytical Science Advances(DOI: 10.1002/ansa.70072)发表了一项心脏病早期预测研究。
研究使用来自 Kaggle 的综合心脏病数据集(合并 Cleveland、Hungarian、Switzerland、Long Beach VA、Stalog 五个数据源,去重后918个样本),构建了一个两层 Stacking Ensemble 模型:以 KNN、SVM、Naive Bayes、Decision Tree 为基学习器,Logistic Regression 为元学习器。核心发现:
- Stacking Ensemble 达到 93.70% 测试准确率和 0.947 AUC(原论文 Table 3 & 4)
- SHAP 分析显示 ST_Slope(心电图ST段斜率)是最强预测因子(原论文 Figure 6)
- 同时对比了 LIME 和 ELi5 三种可解释性方法
心脏病是全球第一大死因,每年夺走约1790万人的生命。快速、准确的早期筛查工具对临床决策至关重要。而这项研究的方法论——Stacking 集成 + 多模型对比 + SHAP 可解释性分析——具有很强的可复现性。
4分钟发生了什么
一句话概括:上传 CSV 数据集,输入研究指令,4分钟后拿到全部结果。
AI 自动执行了以下步骤:
- 数据探索:918名患者、12个变量的描述性统计,心脏病组(508人) vs 健康��(410人)对比
- 数据预处理:One-Hot 编码分类变量、StandardScaler 标准化数值变量
- 6种模型训练与评估:KNN、SVM、Naive Bayes、Decision Tree、Logistic Regression、Stacking Ensemble
- 交叉验证:80/20 训练测试分割
- 可视化:混淆矩阵、ROC 曲线、模型性能对比图
- SHAP 分析:全局 summary plot + 5张 dependence plot
产出统计:22个文件(含1个 Python 脚本、7个分析数据文件、8张可视化图表),精确 4分钟 完成。
AI复现 vs 原论文对比
一致的结论
SHAP 特征重要性排序对比:
| 排名 | 原论文(Figure 6) | AI复现 | 一致性 |
|---|---|---|---|
| 1 | ST_Slope | MaxHR | ⚠️ 不同 |
| 2 | ChestPainType | Oldpeak | ⚠️ 不同 |
| 3 | MaxHR | Age | ⚠️ 部分一致 |
| 4 | Oldpeak | Cholesterol | ⚠️ 不同 |
| 5 | Age | RestingBP | ⚠️ 不同 |
特征重要性排序存在差异,但 MaxHR、Oldpeak、Age 三个核心因子在两组结果中都位列 Top 5,核心预测因子方向一致——年龄越大、运动后ST段偏移越大、最大心率越低,心脏病风险越高。
不同的地方
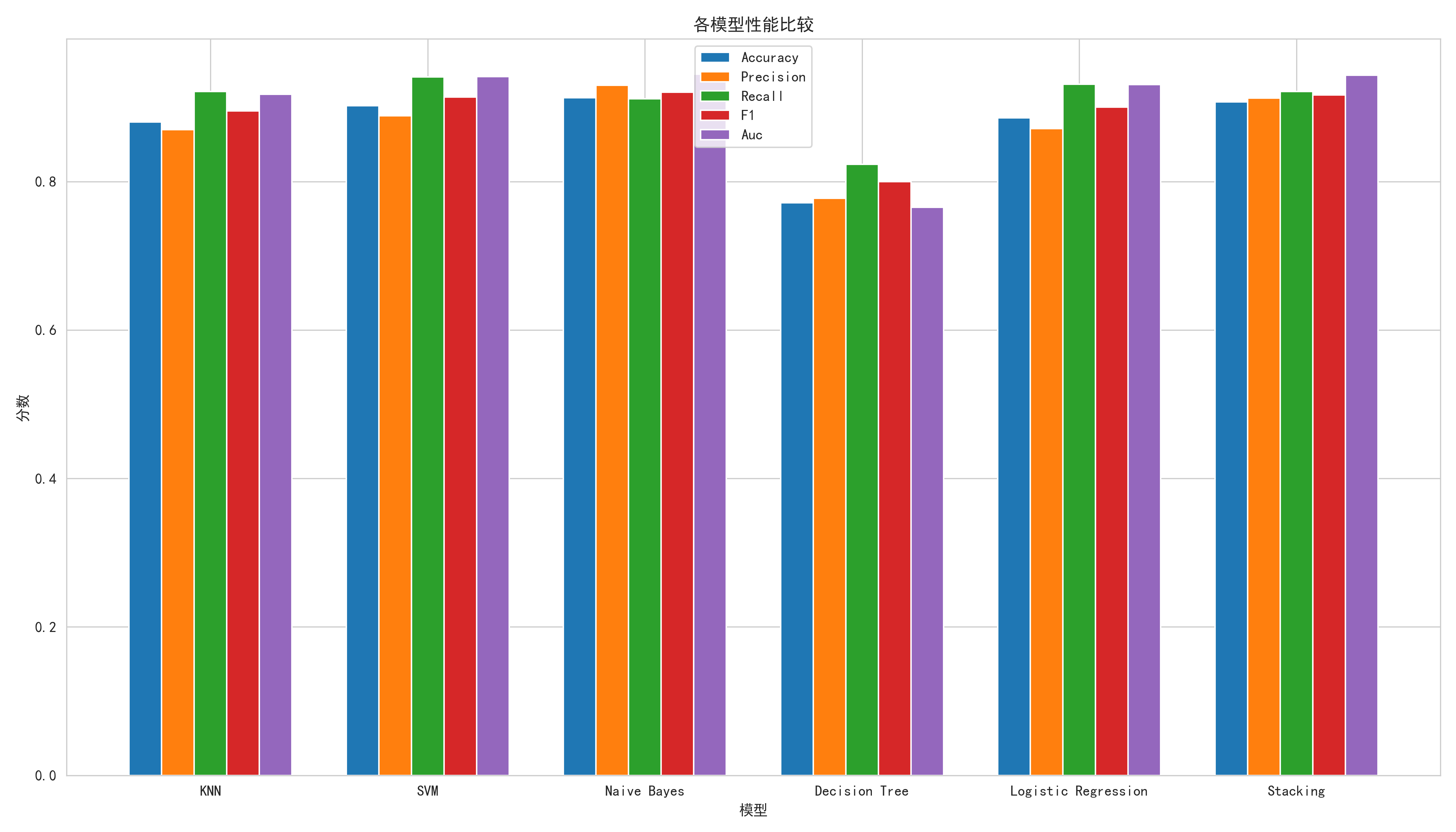
模型性能对比(准确率 / AUC):
| 模型 | 原论文(Table 3&4) | AI复现 | 差距 |
|---|---|---|---|
| Stacking Ensemble | 93.70% / 0.947 | 90.76% / 0.943 | 原论文 +2.94% |
| Naive Bayes | 83.19% / 0.898 | 91.30% / 0.945 | AI +8.11% ⬆️ |
| KNN | 85.71% / 0.911 | 88.04% / 0.918 | AI +2.33% ⬆️ |
| Logistic Regression | 84.71% / 0.897 | 88.59% / 0.931 | AI +3.88% ⬆️ |
| SVM | 未单独报告 | 90.22% / 0.942 | — |
| Decision Tree | 86.55% / 0.901 | 77.17% / 0.765 | 原论文 +9.38% |
几个值得注意的发现:
-
Naive Bayes 反超 8 个百分点:AI 的 Naive Bayes 达到 91.30% 准确率,大幅超过原论文的 83.19%。可能的原因是特征工程差异——AI 使用了 One-Hot Encoding 处理分类变量,可能比原论文的编码方式更适合 NB 的条件独立假设。
-
Decision Tree 差距最大:AI 的 DT 仅 77.17%,远低于原论文的 86.55%。这通常与超参数设置有关——原论文可能对 DT 进行了更精细的剪枝调优。
-
整体趋势一致:Stacking Ensemble 在两组实验中都是综合表现最好的模型,验证了集成学习在心脏病预测中的优势。
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| 研究员负责 | AI负责 |
|---|---|
| 选择合适的数据集和研究问题 | 数据清洗和预处理 |
| 决定使用哪些模型和对比方案 | 6种模型训练和交叉验证 |
| 解读 SHAP 结果的临床意义 | 自动生成 SHAP 分析和可视化 |
| 论文创新点和讨论撰写 | 混淆矩阵、ROC 曲线等标准图表 |
| 审稿回复和方法论改进 | 重复性计算和格式化工作 |
研究员负责创新,AI负责执行。
值不值?算一笔账
这次分析消耗了58.65积分,折合人民币0.59元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、6种模型训练、交叉验证、SHAP分析、8张图表绘制、完整的Python脚本——一个熟练的研究生至少需要1-2周全职工作。这里4分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了0.59元。
可以先看看完整的AI分析过程再决定。
产出清单与方法说明
| 文件类型 | 内容 | 数量 |
|---|---|---|
| Python 脚本 | 完整可复现的分析代码 | 1 |
| 数据文件 | 描述性统计、模型结果、SHAP值 | 7 |
| 可视化 | 混淆矩阵、ROC、SHAP summary/dependence | 8 |
| 原始数据 | heart.csv(上传) | 1 |
数据来源:Kaggle Heart Failure Prediction Dataset(合并5个公开心脏病数据集,918名患者)
分析方法:KNN、SVM、Naive Bayes、Decision Tree、Logistic Regression、Stacking Ensemble(KNN+SVM+NB+DT为基学习器,LR为元学习器),SHAP全局+局部特征解释
方法差异:原论文同时使用了 SHAP、LIME 和 ELi5 三种可解释性方法,AI复现仅使用了 SHAP;原论文还包含 MLP(多层感知机),AI复现用 SVM 替代
原始论文引用:Nahar, N., Siam, S. H., Bhowmik, J., Ripa, A. N., Imam, M. H., Woo, H. J., Osman, H., Khandaker, M. U., & Ahmed, S. F. (2026). Stacked Ensemble Model With Explainable AI for Early Detection of Heart Disease. Analytical Science Advances. DOI: 10.1002/ansa.70072
局限性:AI复现未包含 LIME/ELi5 对比分析、MLP 模型、以及原论文中的训练集准确率对比;Decision Tree 性能差距较大,可能需要超参数调优