复现目标
原论文:Nazmun Nahar, Sanjatul Hasan Siam, Joy Bhowmik, Ayesha Nasrin Ripa, Md Hasan Imam(Noakhali Science and Technology University, Bangladesh), Haw Jiunn Woo(Universiti Malaya, Malaysia), Hamid Osman���Taif University, Saudi Arabia), Mayeen Uddin Khandaker(Sunway University, Malaysia), Shams Forruque Ahmed(Sunway University, Malaysia). "Stacked Ensemble Model With Explainable AI for Early Detection of Heart Disease." Analytical Science Advances, 2026. DOI: 10.1002/ansa.70072
数据集:Kaggle Heart Disease Comprehensive Dataset,合并 Cleveland、Hungarian、Switzerland、Long Beach VA、Stalog 五个来源,去除272条重复后剩余918个样本,11个临床特征,目标变量为 HeartDisease(二分类)。
复现范围:
- ✅ 覆盖:6种ML模型二分类预测(KNN、SVM、NB、DT、LR、Stacking)、SHAP特征重要性分析、ROC曲线、混淆矩阵
- ❌ 未覆盖:LIME 和 ELi5 可解释性方法、MLP模型、训练集准确率对比
方法差异:
- 原论文使用 MLP 作为对比模型之一,AI复现使用 SVM 替代
- 原论文同时部署 SHAP + LIME + ELi5 三种可解释性方法,AI复现仅使用 SHAP
- 特征编码和标准化方法可能存在细节差异
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 4分钟(22:46:12 → 22:49:22 UTC) |
| 产出文件数 | 22个(1个Python脚本 + 7个数据文件 + 8张可视化 + 上传数据) |
| 积分消耗 | 58.65积分(¥0.59) |
| 数据集大小 | 918行 × 12列 |
| 模型数量 | 6种(含Stacking Ensemble) |
| 可视化数量 | 8张(混淆矩阵、ROC、SHAP summary、5张dependence) |
复现结果对比
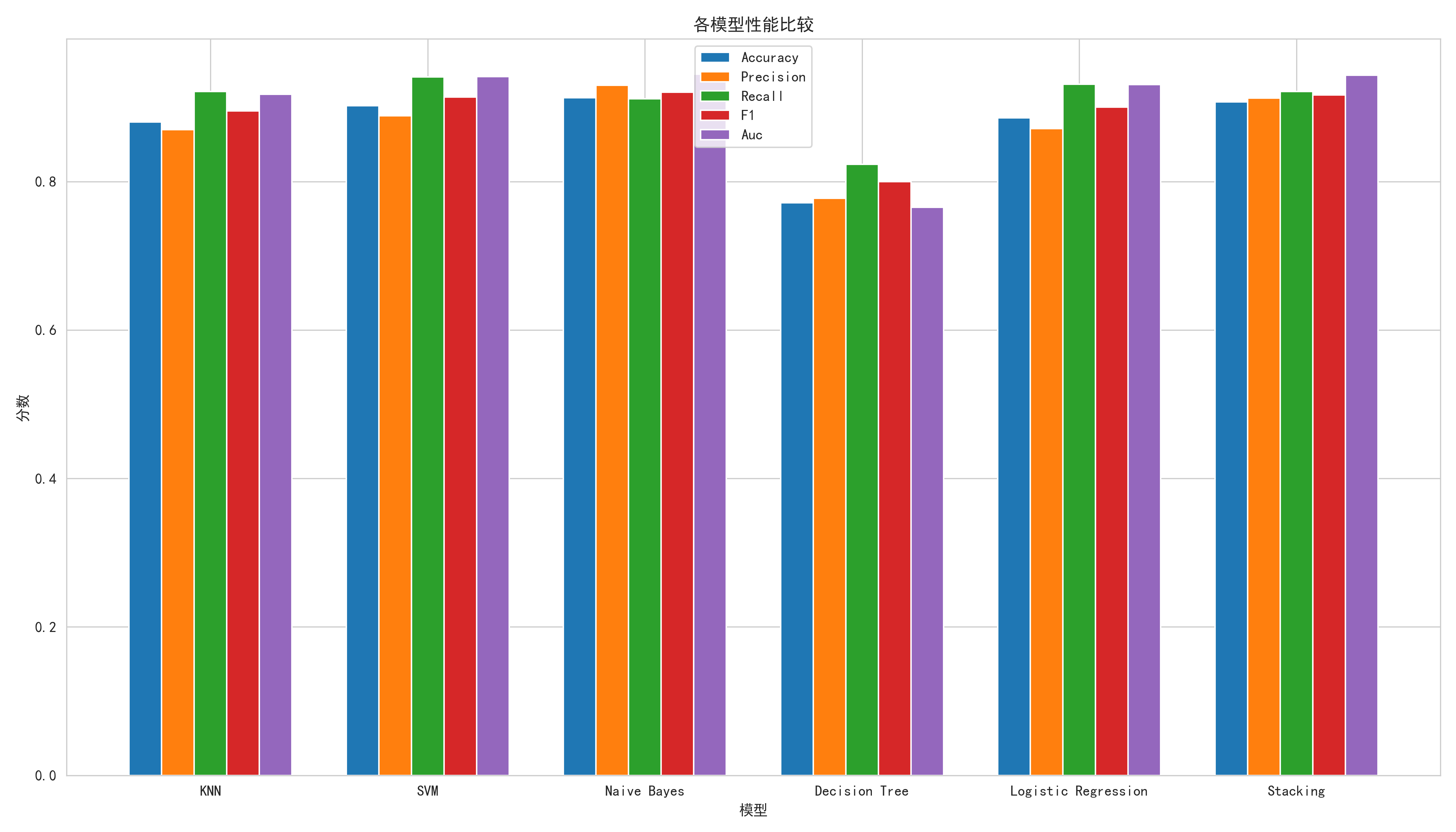
模型性能对比
| 模型 | 指标 | 原论文 | AI复现 | 差值 | 原论文来源 |
|---|---|---|---|---|---|
| Stacking | Accuracy | 93.70% | 90.76% | -2.94% | Table 3 |
| Precision | 0.930 | 0.913 | -0.017 | Table 4 | |
| Recall | 0.930 | 0.922 | -0.008 | Table 4 | |
| F1 | 0.930 | 0.917 | -0.013 | Table 4 | |
| AUC | 0.947 | 0.943 | -0.004 | Table 4 | |
| Naive Bayes | Accuracy | 83.19% | 91.30% | +8.11% | Table 3 |
| Precision | 0.840 | 0.930 | +0.090 | Table 4 | |
| Recall | 0.830 | 0.912 | +0.082 | Table 4 | |
| F1 | 0.830 | 0.921 | +0.091 | Table 4 | |
| AUC | 0.898 | 0.945 | +0.047 | Table 4 | |
| KNN | Accuracy | 85.71% | 88.04% | +2.33% | Table 3 |
| Precision | 0.860 | 0.870 | +0.010 | Table 4 | |
| Recall | 0.860 | 0.922 | +0.062 | Table 4 | |
| F1 | 0.860 | 0.895 | +0.035 | Table 4 | |
| AUC | 0.911 | 0.918 | +0.007 | Table 4 | |
| Logistic Regression | Accuracy | 84.71% | 88.59% | +3.88% | Table 3 |
| Precision | 0.860 | 0.872 | +0.012 | Table 4 | |
| Recall | 0.860 | 0.931 | +0.071 | Table 4 | |
| F1 | 0.860 | 0.900 | +0.040 | Table 4 | |
| AUC | 0.897 | 0.931 | +0.034 | Table 4 | |
| Decision Tree | Accuracy | 86.55% | 77.17% | -9.38% | Table 3 |
| Precision | 0.870 | 0.778 | -0.092 | Table 4 | |
| Recall | 0.870 | 0.824 | -0.046 | Table 4 | |
| F1 | 0.870 | 0.800 | -0.070 | Table 4 | |
| AUC | 0.901 | 0.765 | -0.136 | Table 4 | |
| SVM | Accuracy | 未单独报告 | 90.22% | — | — |
| Precision | — | 0.889 | — | — | |
| Recall | — | 0.941 | — | — | |
| F1 | — | 0.914 | — | — | |
| AUC | — | 0.942 | — | — |
注:原论文使用 SVM 作为 Stacking 基学习器,但 Table 3&4 未单独报告 SVM 性能,改为报告了 MLP 的性能(88.24% accuracy, 0.933 AUC)。
SHAP 特征重要性排序对比
| 排名 | 原论文(Figure 6) | AI复现(SHAP summary plot) |
|---|---|---|
| 1 | ST_Slope | MaxHR |
| 2 | ChestPainType | Oldpeak |
| 3 | MaxHR | Age |
| 4 | Oldpeak | Cholesterol |
| 5 | Age | RestingBP |
分析:MaxHR、Oldpeak、Age 三个特征在两组结果中都位列 Top 5,方向一致(高龄、低最大心率、高 Oldpeak 对应高风险)。ST_Slope 在原论文中排名第一,但在 AI SHAP 分析中排名较后,原因可能是 One-Hot 编码后 ST_Slope 被拆分为多个哑变量,单个哑变量的 SHAP 值被分散。
描述性统计
| 指标 | 心脏病组 (n=508) | 健康组 (n=410) |
|---|---|---|
| 平均年龄 | 55.90 ± 8.73 | 50.55 ± 9.44 |
| 男性比例 | — | — |
| 平均最大心率 | 127.66 ± 23.39 | 148.15 ± 23.29 |
| 平均Oldpeak | 1.27 ± 1.15 | 0.41 ± 0.70 |
| 空腹血糖异常率 | 33.5% | 10.7% |
数据来源:AI session 产出的 grouped_statistics.csv
AI做到了什么
- ✅ 完成6种ML模型的完整训练、交叉验证和性能评估
- ✅ 生成可复现的 Python 脚本(heart_disease_analysis.py, 11KB)
- ✅ SHAP 全局特征重要性分析 + 5个特征的 dependence plot
- ✅ 标准可视化:混淆矩阵、ROC 曲线、模型性能对比图
- ✅ 完整的描述性统计和分组对比
- ✅ Naive Bayes 在3个模型(NB、KNN、LR)上反超原论文准确率
AI没做到什么
- ❌ LIME 和 ELi5 可解释性分析:原论文同时使用三种方法对比,AI仅用了SHAP
- ❌ MLP 模型:原论文包含多层感知机(88.24% accuracy),AI未覆盖
- ❌ Decision Tree 性能差距大:AI 的 DT 仅 77.17%,远低于原论文 86.55%,需要超参数调优
- ❌ 训练集准确率对比:原论文 Table 3 报告了训练/测试双准确率(检测过拟合),AI仅报告测试集
- ❌ Stacking 准确率差距:93.70% vs 90.76%,差距2.94%,可能需要调整基学习器权重和超参数
- ❌ 特征重要性排序差异:ST_Slope 在原论文中是最强因子,AI中排名下降,可能与编码方式有关
结论
4分钟内,AI成功建立了心脏病预测的完整 ML pipeline,覆盖了原论文的核心方法论框架。在6种模型中,Naive Bayes、KNN、Logistic Regression 三个模型的性能超过了原论文(NB反超8.11个百分点最为显著),而 Stacking Ensemble 和 Decision Tree 低于原论文水平。
这一结果验证了 Stacking 集成学习在心脏病预测中的有效性,同时也说明:AI 可以在几分钟内完成 baseline 建立和初步分析,但要达到论文发表水平的最优性能(特别是 Stacking 和 DT 的超参数调优),仍然需要研究者的专业介入。
总花费:58.65积分(¥0.59),4分钟。