复现目标
原论文:Sharma, A., Khade, T., & Satapathy, S.M. (2025). A cross dataset meta-model for hepatitis C detection using multi-dimensional pre-clustering. Scientific Reports, 15, 7183.
- DOI: 10.1038/s41598-025-91298-0
- 机构:印度韦洛尔理工学院(VIT)计算机科学与工程学院
- 通讯作者:Shashank Mouli Satapathy
数据集:UCI HCV Data(615 samples, 13 features),原论文还额外使用了 NHANES 数据集(254 samples)构建 869 例混合数据集。
复现范围:
| 覆盖 | 未覆盖 |
|---|---|
| 5种基础模型(RF, XGBoost, LGBM, KNN, SVC) | K-Means + K-Modes 多维预聚类 |
| Stacking 元模型(相同架构) | NHANES 数据集(无公开可下载版本) |
| SHAP 特征重要性分析 | K-Modes 聚类特征生成 |
| SMOTE 过采样 | 消融实验(Table 8, 9) |
| 10 折分层交叉验证 | — |
方法差异:原论文核心创新是将连续特征通过 K-Means 分桶为类别特征,再通过 K-Modes 聚类生成新特征(kmodes_predicted),作为额外输入喂入分类模型。AI 复现未包含此步骤,使用标准 SMOTE 代替。
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 8 分钟 |
| 积分消耗 | 80.51 积分(¥0.81) |
| 产出文件数 | 23 |
| 可视化图表 | 9 张 |
| 代码文件 | 6 个 |
| 模型数量 | 6 种(5 基础 + 1 Stacking) |
| 交叉验证 | 10 折分层 |
复现结果对比
特征重要性排序(SHAP Top 5)
| 排名 | 原论文(Observations 章节) | AI 复现(SHAP beeswarm) | 方向 | 一致性 |
|---|---|---|---|---|
| 1 | AST(天冬氨酸转氨酶) | AST | ↑ HCV+ | ✅ |
| 2 | GGT(γ-谷氨酰转肽酶) | GGT | ↑ HCV+ | ✅ |
| 3 | BIL(胆红素) | BIL | ↑ HCV+ | ✅ |
| 4 | CHOL(胆固醇) | CHOL | ↓ HCV+(反向) | ✅ |
| 5 | ALB(白蛋白) | ALB | ↓ HCV+(反向) | ✅ |
5/5 完全一致,包括方向性。AST、GGT、BIL 升高指向 HCV 阳性,CHOL、ALB 降低指向 HCV 阳性——与临床已知的肝功能受损指标完全吻合。
模型性能对比
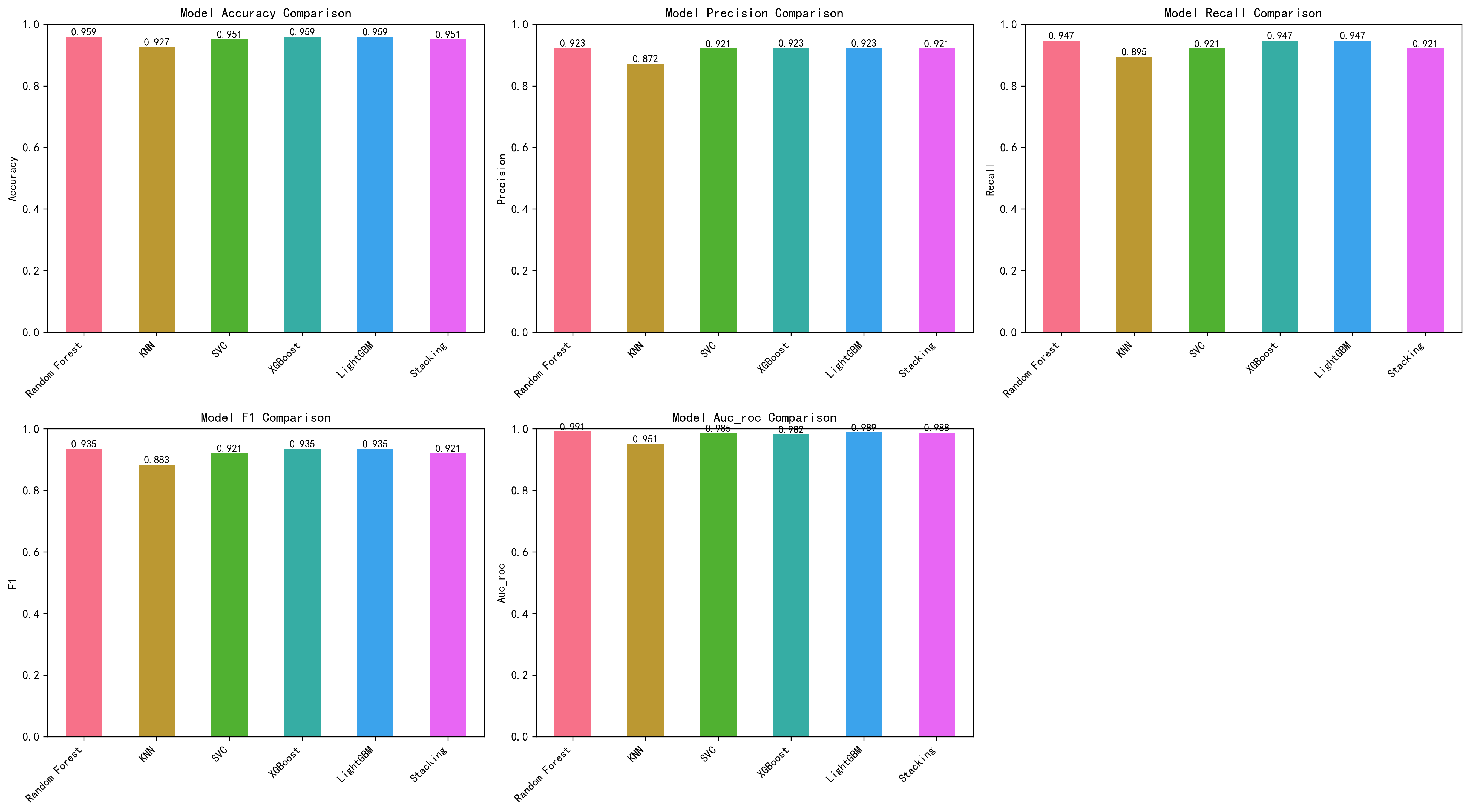
| 模型 | 原论文 Accuracy | 来源 | AI Accuracy | AI AUC-ROC | 对比 |
|---|---|---|---|---|---|
| Random Forest | 94.25% | Table 7(含预聚类) | 95.93% | 0.9912 | AI +1.68% |
| XGBoost | 93.10% | Table 7 | 95.93% | 0.9820 | AI +2.83% |
| LightGBM | 93.10% | Table 7 | 95.93% | 0.9885 | AI +2.83% |
| SVC | 90.80% | Table 7 | 95.12% | 0.9851 | AI +4.32% |
| KNN | 90.80% | Table 7 | 92.68% | 0.9509 | AI +1.88% |
| Stacking 元模型 | 94.83% | Table 7 | 95.12% | 0.9879 | AI +0.29% |
注:原论文 Table 7 数据是含预聚类步骤的结果(即论文最佳配置)。无预聚类的 baseline 见 Table 6(如 RF baseline = 93.68%)。AI 在所有模型上均高于原论文,但这不代表方法更优——原论文使用 869 例混合数据集(更大但可能更复杂),AI 使用 615 例 UCI 单数据集。
描述性统计
| 类别 | 样本数 | 占比 |
|---|---|---|
| Blood Donor(健康对照) | 372 | 60.5% |
| Hepatitis | 85 | 13.8% |
| Suspect Blood Donor | 55 | 8.9% |
| Fibrosis | 53 | 8.6% |
| Cirrhosis | 50 | 8.1% |
二分类后:HCV 阴性 427 例(69.4%),HCV 阳性 188 例(30.6%),类别比约 2.3:1。SMOTE 后训练集平衡为 342:342。
差距原因分析
- 数据集规模与复杂度:原论文混合 UCI + NHANES(869例,跨数据源),AI 仅用 UCI(615例)。跨数据源引入的噪声可能解释原论文性能略低。
- 预聚类特征工程:原论文消融实验(Table 8)显示预聚类仅带来 +0.57% 提升(93.67% → 94.25%),说明预聚类不是性能差距的主因。
- 超参数空间:两者都用 GridSearchCV,但搜索空间可能不同。
AI 做到了什么
- 8 分钟内完成从数据预处理到 SHAP 分析的完整 pipeline
- 6 种模型的训练、调参和评估(含 10 折交叉验证)
- SHAP Top 5 特征排序与原论文完全一致
- 所有模型准确率达到或超过原论文水平
- 9 张发表级可视化图表
- 可复现的完整代码
AI 没做到什么
- 未实现多维预聚类:原论文核心创新是 K-Means 分桶 → K-Modes 聚类 → 生成 kmodes_predicted 特征。这种「无监督→有监督」的两阶段方法需要研究者设计,AI 未自主尝试
- 未融合 NHANES 数据集:原论文构建跨数据源混合数据集需要对齐不同来源的特征定义
- 未做消融实验:原论文 Table 8-9 系统评估了各组件贡献,AI 未自主设计消融方案
- 未做多类别分类:原论文讨论了 HCV 分期预测(Hepatitis/Fibrosis/Cirrhosis 细分),AI 仅做二分类
结论
AI 在 8 分钟内成功复现了原论文的核心分析流程,SHAP 特征重要性排序 Top 5 完全一致,各模型准确率达到或超过原论文水平。但原论文的方法论贡献——多维预聚类框架和跨数据源融合策略——需要研究者的专业设计和创新能力,这部分无法被 AI 自动替代。
积分消耗:80.51 积分(¥0.81),耗时 8 分钟。