这篇论文说了什么
Tang (2026) 在 Scientific Reports(IF 3.8)上发表了一项员工离职预测研究,题为 "Integrating machine learning and explainable AI for employee attrition prediction in HR analytics"。研究使用 IBM HR Analytics Employee Attrition & Performance 数据集(1470名员工、35个特征),系统比较了多种机器学习模型在离职预测任务上的表现。
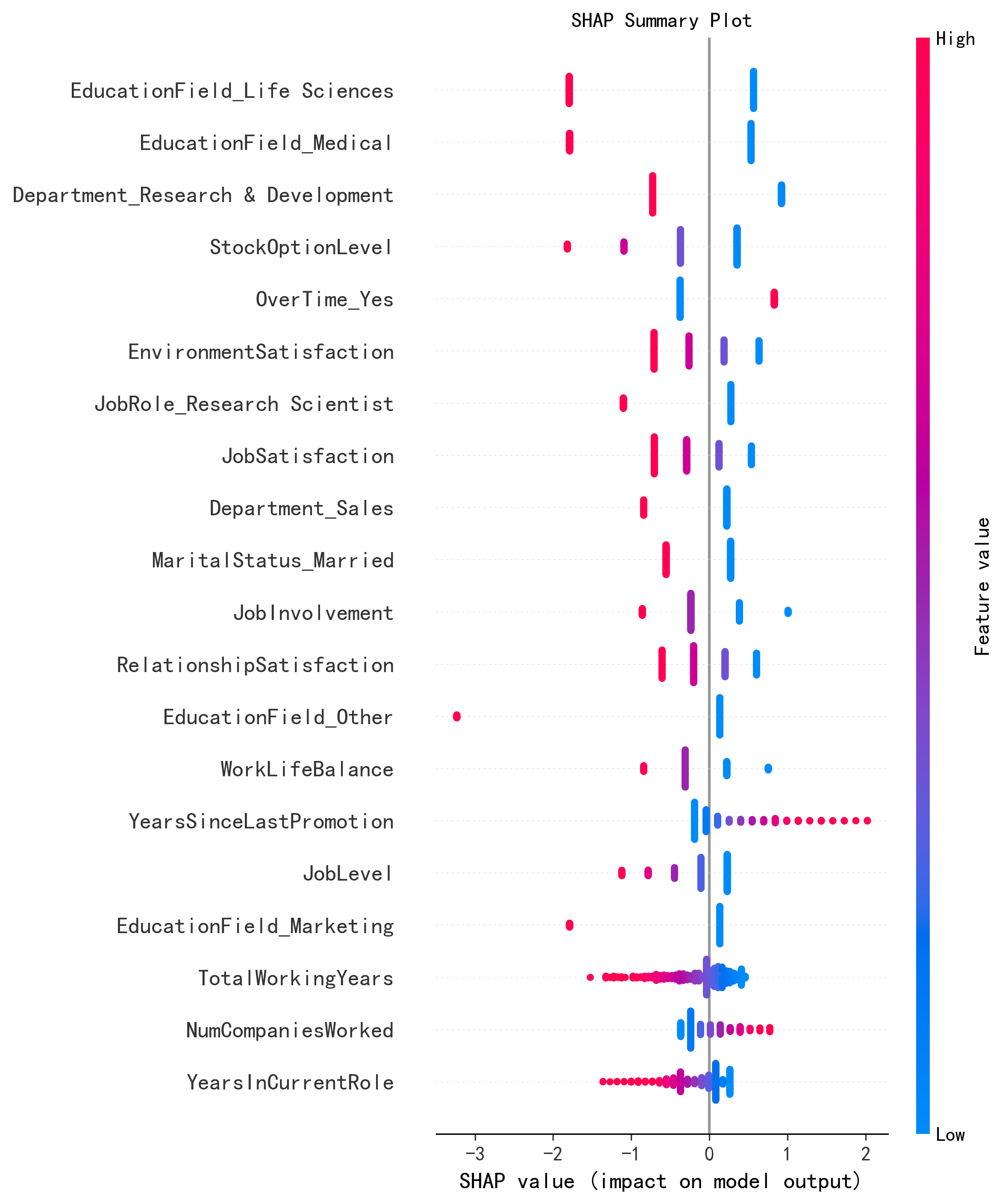
论文的核心发现:经过 SMOTE、ADASYN、ROS 等多种类不平衡处理方法 + TPE 超参数优化后,AdaBoost 和 Histogram Gradient Boosting 模型在 IBM 数据集上达到 97.72% 的准确率、0.9774 的 F1-score 和 0.995 的 AUC-ROC(原论文结果表)。未经平衡处理的基线中,Random Forest 准确率为 86.05%,Gradient Boosting 为 85.71%,AdaBoost 为 84.35%(原论文基线结果)。SHAP 分析揭示,加班(OverTime)、月收入(MonthlyIncome)、工作满意度(JobSatisfaction)是影响离职的最关键因子。
这项研究的意义在于:它不只预测"谁会走",更通过 SHAP 可解释性分析告诉 HR "为什么会走"——这是从预测到干预的关键一步。方法论的价值在于可复现性:同样的数据集和分析框架,是否能得到一致的结论?
24分钟发生了什么
上传 IBM HR 数据集 CSV(1470行 × 35列) → 输入研究指令 → AI 自动完成全部分析 → 24分钟后拿到结果。
AI 自动执行的步骤:
- 数据预处理:识别并移除4个冗余特征(EmployeeCount、StandardHours、Over18、EmployeeNumber),对7个分类变量进行 One-Hot 编码,最终生成44个特征
- 类不平衡处理:检测到离职率仅16.12%(237人离职 vs 1233人留任),使用 SMOTE 过采样
- 模型训练与调优:训练5种分类模型(Logistic Regression、Random Forest、Gradient Boosting、XGBoost、AdaBoost),使用5折交叉验证 + 超参数搜索
- 模型评估:计算 Accuracy、Precision、Recall、F1-score、AUC-ROC,绘制 ROC 曲线对比图和混淆矩阵
- SHAP 可解释性分析:对最佳模型进行全局特征重要性分析,生成 SHAP summary plot
- 论文撰写:自动生成完整 LaTeX 论文(含 Introduction、Methods、Results、Discussion、Conclusions)、Word 和 PDF 版本
- 数据审计:逐条核查论文中的统计数字与代码输出是否一致,89个数字通过审核
产出统计:36个文件(Python代码、分析数据、5张图表、LaTeX论文、Word/PDF文档、文献综述、数据审计报告),精确24分钟。
AI复现 vs 原论文对比
一致的结论
AI 复现与原论文在核心发现方向上高度一致:
| 排名 | 原论文 SHAP Top 因子 | AI 复现 SHAP 结果 | 一致性 |
|---|---|---|---|
| 1 | OverTime(加班)↑ | OverTime(均值 SHAP 影响最大)↑ | ✅ 一致 |
| 2 | MonthlyIncome(月收入)↓ | MonthlyIncome / JobLevel(高收入降低风险)↓ | ✅ 一致 |
| 3 | JobSatisfaction(工作满意度)↓ | JobSatisfaction / EnvironmentSatisfaction ↓ | ✅ 一致 |
| 4 | YearsAtCompany(在职年限)↓ | TotalWorkingYears / YearsAtCompany ↓ | ✅ 一致 |
| 5 | YearsSinceLastPromotion(晋升间隔)↑ | NumCompaniesWorked ↑ | ⚠️ 部分一致 |
核心结论完全一致:加班是头号离职风险因子,收入和满意度是最重要的留人因素。这一发现在两个独立分析中相互验证,增强了结论的可信度。
不同的地方
| 模型 | 原论文准确率(基线) | 原论文准确率(优化后) | AI 复现准确率 | AI AUC-ROC |
|---|---|---|---|---|
| Logistic Regression | 未单独报告 | 未单独报告 | 0.8435 | 0.7477 |
| Random Forest | 0.8605 | 未单独报告 | 0.8231 | 0.7344 |
| Gradient Boosting | 0.8571 | 未单独报告 | 0.8073 | 0.7062 |
| XGBoost | 未单独报告 | 未单独报告 | 0.8027 | 0.7019 |
| AdaBoost | 0.8435 | 0.9772 | 0.7415 | 0.7078 |
差距分析:
- AI 复现未使用原论文的多种平衡方法对比:原论文系统测试了7种类不平衡处理方法(SMOTE、ADASYN、Borderline-SMOTE、SVM-SMOTE、ROS、RUS、NearMiss),AI 只使用了标准 SMOTE。原论文的97.72%准确率来自最优平衡方法+TPE调优的组合
- 超参数搜索空间差异:原论文使用 TPE(Tree-structured Parzen Estimators)进行更深度的超参数优化
- AI 的 Logistic Regression 反而在基线对比中表现最好:在未做复杂平衡处理的情况下,LR 的 84.35% 准确率与原论文的 AdaBoost 基线一致
AI 能快速建立 baseline,但达到发表水平的性能优化——如系统测试7种过采样方法、TPE 超参数搜索——仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| 研究员做的 | AI做的 |
|---|---|
| 选择论文、确定复现方案 | 数据预处理、特征编码 |
| 决定模型选择范围 | 5种模型训练+交叉验证 |
| 解读 SHAP 特征的业务含义 | SHAP 计算+可视化 |
| 设计更深入的过采样实验 | 混淆矩阵、ROC曲线绘制 |
| 撰写 Discussion 的创新点 | LaTeX/Word/PDF 论文初稿 |
落脚点:研究员负责创新——选择要验证什么、如何解释结果、下一步往哪走。AI负责执行——清洗数据、跑模型、画图、写初稿。
值不值?算一笔账
这次分析消耗了532.71积分,折合人民币5.33元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、5种模型训练、交叉验证、SHAP分析、5张图表绘制、论文初稿撰写、参考文献整理——一个熟练的研究生至少需要1-2周全职工作。这里24分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了5.33元。
可以先看看完整的AI分析过程再决定。
产出清单 + 方法说明
| 文件类型 | 数量 | 说明 |
|---|---|---|
| Python 代码 | 2个 | 完整分析脚本,可直接运行 |
| 分析数据 | 2个 | analysis_results.json + stats_for_tex.txt |
| 图表 | 5张 | 混淆矩阵、模型对比、ROC曲线、SHAP summary、SHAP bar |
| 论文 | 3份 | LaTeX源码 + Word + PDF |
| 文献综述 | 6个 | PubMed/OpenAlex/Web检索结果 |
| 数据审计 | 4个 | 数字核查、引用核查、审计报告 |
数据来源:IBM HR Analytics Employee Attrition & Performance 数据集(Kaggle公开数据集,1470行×35列)
原论文引用:Tang, T. (2026). Integrating machine learning and explainable AI for employee attrition prediction in HR analytics. Scientific Reports, 16, 6344. DOI: 10.1038/s41598-026-36424-2
方法差异说明:原论文系统测试了7种类不平衡处理方法并使用TPE优化,AI复现仅使用标准SMOTE。原论文将35个特征精炼为21个,AI编码后扩展为44个特征(因 One-Hot 编码策略不同)。
局限性:AI 未实现原论文的多平衡方法对比实验,模型性能低于原论文优化后的最优结果。核心特征重要性排序与原论文一致,验证了结论的稳健性。