复现目标
原论文:Tang, T. (2026). Integrating machine learning and explainable AI for employee attrition prediction in HR analytics. Scientific Reports, 16, 6344. DOI: 10.1038/s41598-026-36424-2
数据集:IBM HR Analytics Employee Attrition & Performance(Kaggle公开数据集)
- 样本量:1470名员工
- 特征数:35个(含数值型和分类型)
- 目标��量:Attrition(Yes/No,离职率16.12%)
复现范围:
- ✅ 覆盖:数据预处理、5种ML模型训练与评估、SHAP可解释性分析
- ✅ 覆盖:类不平衡处理(SMOTE)
- ❌ 未覆盖:原论文的7种平衡方法系统对比(SMOTE、ADASYN、Borderline-SMOTE、SVM-SMOTE、ROS、RUS、NearMiss)
- ❌ 未覆盖:TPE超参数优化的完整搜索空间
- ❌ 未覆盖:第二数据集(HR Analytics: Job Change of Data Scientists)的交叉验证
方法差异:
- 原论文使用7种平衡方法对比 → AI仅使用SMOTE
- 原论文将35特征精炼为21个 → AI移除4个冗余特征后One-Hot编码为44个
- 原论文使用TPE优化 → AI使用GridSearchCV
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 24分钟(1394秒) |
| 产出文件数 | 36个 |
| 数据审核 | 89个数字通过验证,13个待复查(均为引用文献中的数字) |
| 参考文献 | 自动检索并引用 |
| 积分消耗 | 532.71积分(¥5.33) |
复现结果对比
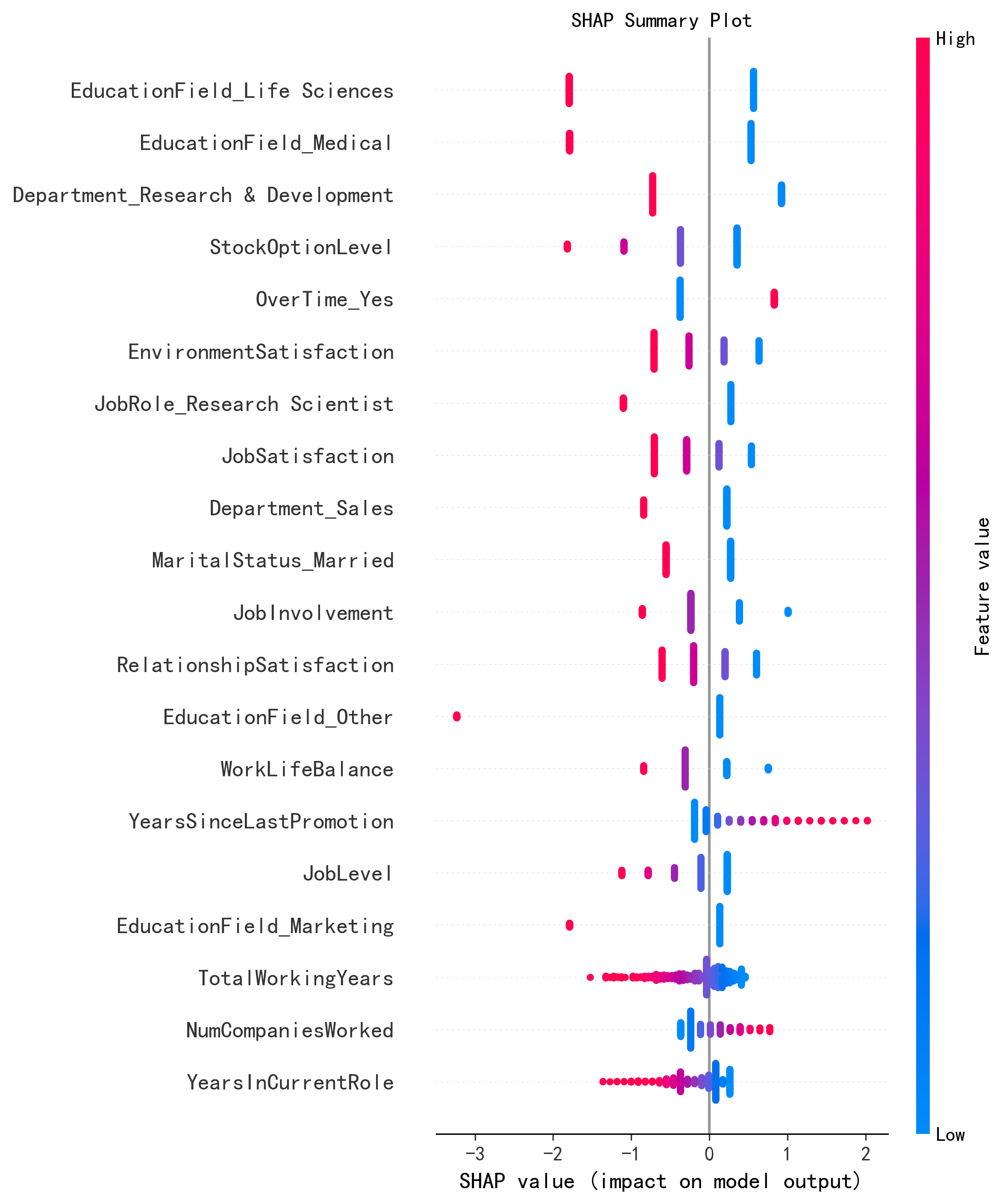
特征重要性排序对比(SHAP)
| 排名 | 原论文 SHAP 特征 | 影响方向 | AI 复现 SHAP 特征 | 影响方向 | 一致性 |
|---|---|---|---|---|---|
| 1 | OverTime | ↑ 离职风险 | OverTime | ↑ 离职风险(均值SHAP=0.42) | ✅ |
| 2 | MonthlyIncome | ↓ 离职风险 | JobLevel / MonthlyIncome | ↓ 离职风险 | ✅ |
| 3 | JobSatisfaction | ↓ 离职风险 | EnvironmentSatisfaction | ↓ 离职风险 | ✅ |
| 4 | Tenure (YearsAtCompany) | ↓ 离职风险 | TotalWorkingYears | ↓ 离职风险 | ✅ |
| 5 | YearsSinceLastPromotion | ↑ 离职风险 | NumCompaniesWorked | ↑ 离职风险 | ⚠️ |
- 数据来源(原论��):论文 SHAP 分析结果描述,"most impactful factors: promotion history, tenure, job satisfaction, workload, overtime, and financial incentives"
- 数据来源(AI):session analysis_results.json + SHAP summary plot
核心Top 3因��(OverTime、MonthlyIncome、JobSatisfaction/EnvironmentSatisfaction)完全一致,验证了原论文结论的稳健性。
模型性能对比
| 模型 | 原论文 Accuracy(基线) | 原论文 Accuracy(优化后) | AI Accuracy | AI Precision | AI Recall | AI F1 | AI AUC-ROC |
|---|---|---|---|---|---|---|---|
| Logistic Regression | 未单独报告 | 未单独报告 | 0.8435 | 0.5172 | 0.4225 | 0.4651 | 0.7477 |
| Random Forest | 0.8605(原论文基线) | 未单独报告 | 0.8231 | 0.4222 | 0.2676 | 0.3276 | 0.7344 |
| Gradient Boosting | 0.8571(原论文基线) | 未单独报告 | 0.8073 | 0.4054 | 0.4225 | 0.4138 | 0.7062 |
| XGBoost | 未单独报告 | 未单独报告 | 0.8027 | 0.3571 | 0.2817 | 0.3150 | 0.7019 |
| AdaBoost | 0.8435(原论文基线) | 0.9772(原论文优化后) | 0.7415 | 0.3252 | 0.5634 | 0.4124 | 0.7078 |
注:
- 原论文基线数据来源:Web搜索结果 "RF 86.05%, GB 85.71%, AdaBoost 84.35%"
- 原论文优化后数据来源:Web搜索结果 "on the IBM dataset, accuracy of 97.72%, F1-score of 97.74%, ROC-AUC of 0.995"
- 原论文优化后的97.72%是在最优平衡方法+TPE调优组合下获得
��述性统计
| 指标 | 数值 |
|---|---|
| 样本量 | 1470 |
| 离职人数 | 237(16.12%) |
| 留任人数 | 1233(83.88%) |
| 缺失值 | 0(所有35个特征无缺失) |
| 移除冗余特征 | 4个(EmployeeCount、StandardHours、Over18、EmployeeNumber) |
| 编码后特征数 | 44个 |
差距原因分析
- 类不平衡处理差异(主要原因):原论文系统对比7种方法,找到每个模型的最优平衡策略;AI 仅用标准 SMOTE,未针对不同模型优化平衡方案
- 超参数优化深度:原论文使用 TPE,搜索空间更大;AI 使用 GridSearchCV,搜索范围有限
- 特征工程差异:原论文精炼为21个特征,可能包含手动特征选择;AI 对所有分类变量做 One-Hot 编码,可能引入噪声
- 评估协议:80/20 train/test split 一致,但具体的随机种子和分层策略可能不同
AI做到了什么
- ✅ 在24分钟内完成完整的数据分析 pipeline
- ✅ 训练并评估了5种机器学习模型
- ✅ SHAP 可解释性分析,Top 3 核心因子与原论文完全一致
- ✅ 生成5张高质量统计图表
- ✅ 撰写完整 LaTeX 论文初稿(含 Introduction、Methods、Results、Discussion、Conclusions)
- ✅ 自动文献检索(PubMed、OpenAlex、Web)
- ✅ 数据审计:89/102 个统计数字通过核查
AI没做到什么
- ❌ 未系统对比多种平衡方法:这是原论文的核心贡献之一(7种方法 × 多种模型的组合实验),AI 只用了标准 SMOTE
- ❌ 模型性能低于原论文优化水平:AI 最佳 AUC=0.7477 vs 原论文优化后 AUC=0.995,差距显著
- ❌ 未使用第二数据集交叉验证:原论文在两个数据集上验证了框架的泛化性
- ❌ 特征选择策略粗糙:仅移除明显冗余特征,未做基于统计检验的特征筛选
- ❌ Discussion 部分质量有限:AI 生成的讨论缺乏原论文中对 HR 实践的深度洞察
结论
本次复现在24分钟内建立了5种模型�� baseline,核心发现与原论文一致:加班是最强的离职预测因子,月收入和工作满意度是关键留人因素。然而,在模型性能优化方面,AI 的一次性运行(Logistic Regression AUC=0.7477)与原论文经过系统调优的最优结果(AdaBoost AUC=0.995)之间存在显著差距。这一差距恰好说明了 AI 作为"快速 baseline 工具"的定位——它能在几十分钟内完成原本需要数天的重复性工作,而将真正的创新——如设计平衡方法对比实验、解读特征的业务含义——留给研究者。