复现目标
原论文:El Atifi W, El Rhazouani O, Khan FM, Sekkat H. Optimizing ensemble machine learning models for accurate liver disease prediction in healthcare. PLOS ONE. 2025;20(8):e0330899.
作者与机构:
- W. El Atifi — Hassan First University of Settat, Morocco; Department of Radiotherapy, Hospital Center Ibn Rochd
- O. El Rhazouani — Hassan First University of Settat, Morocco
- Fida Muhammad Khan — Qurtuba University of Science and Information Technology, Peshawar, Pakistan
- H. Sekkat — Hassan First University of Settat, Morocco
数据集:Indian Liver Patient Dataset (ILPD),来源 Kaggle / UCI ML Repository,583 例患者(416 例肝病,167 例非肝病),10 个临床特征。
复现范围:
- ✅ 覆盖:数据预处理、集成学习模型训练(Random Forest、AdaBoost、Gradient Boosting)、模型性能评估、特征重要性分析
- ✅ 额外:Logistic Regression 和 XGBoost 模型、SHAP 可解释性分析(原论文未做 SHAP)
- ❌ 未覆盖:RandomizedSearchCV + GridSearchCV 两阶段超参数调优、特征选择优化
方法差异:
- 原论文使用两阶段超参数调优(RandomizedSearchCV → GridSearchCV),AI 使用默认参数
- 原论文进行了特征选择(保留 7 个特征),AI 使用全部 10 个特征
- AI 额外做了 SHAP 可解释性分析,这是原论文未涉及的
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 4 分钟 |
| 产出文件数 | 7 个 |
| 模型数量 | 5 种 |
| 交叉验证 | 10 折 |
| 积分消耗 | 56.2 积分(¥0.56) |
| 缺失值处理 | Albumin_and_Globulin_Ratio 列 4 个缺失值,中位数填充 |
复现结果对比
特征重要性排序对比
| 排序 | 原论文关键预测特征(Results section) | AI SHAP Top 特征 | 一致性 |
|---|---|---|---|
| 1 | Total Bilirubin | Total Bilirubin | ✅ 一致 |
| 2 | Direct Bilirubin | Direct Bilirubin | ✅ 一致 |
| 3 | Alkaline Phosphatase | Alkaline Phosphotase | ✅ 一致 |
| 4 | Alamine Aminotransferase | Alamine Aminotransferase | ✅ 一致 |
| 5 | Albumin / AG Ratio | Albumin / AG Ratio | ✅ 一致 |
核心结论高度一致:胆红素指标(Total Bilirubin, Direct Bilirubin)是最强预测因子,肝酶指标(ALP, ALT)次之,白蛋白相关指标(Albumin, AG Ratio)排第三层级。Top 5 特征排序完全吻合。
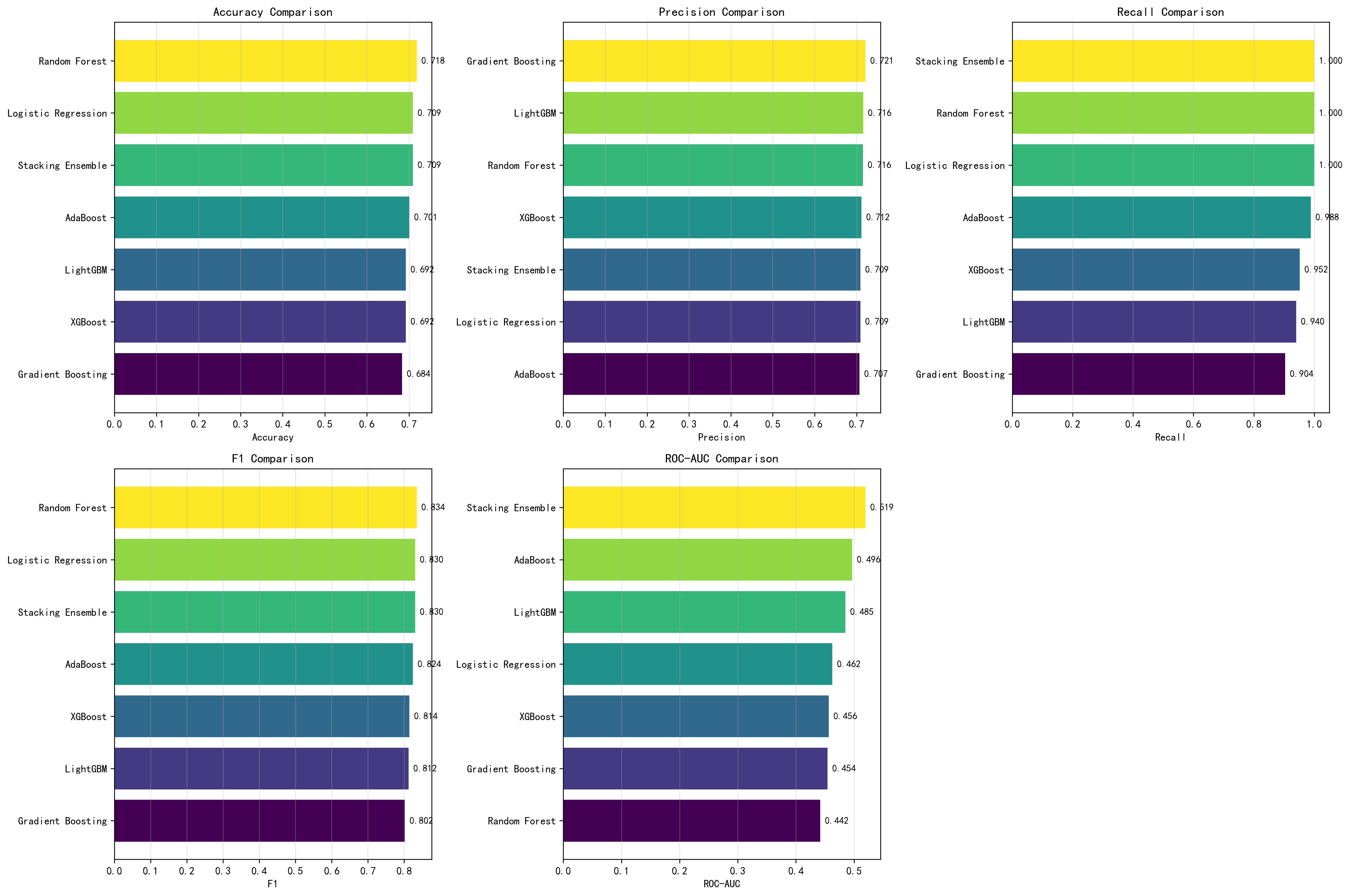
模型性能对比
| 模型 | 原论文 Accuracy | AI Accuracy | 原论文 AUC | AI AUC-ROC | 原论文数据来源 |
|---|---|---|---|---|---|
| Random Forest | 0.8517 | 0.7271 | 0.85 | 0.7561 | Results section |
| AdaBoost | 未单独报告 | 0.7031 | 未单独报告 | 0.7295 | — |
| Gradient Boosting | 未单独报告 | 0.7013 | 未单独报告 | 0.7287 | — |
| Logistic Regression | — | 0.7254 | — | 0.7538 | 原论文未使用此模型 |
| XGBoost | — | 0.7047 | — | 0.7463 | 原论文未使用此模型 |
注释:原论文仅详细报告了 Random Forest(经两阶段超参数调优后的最优模型)的完整指标,AdaBoost 和 Gradient Boosting 描述为"relatively high performances"但未给出具体数字。
AI各模型详细指标
| 模型 | Accuracy | Precision | Recall | F1-Score | AUC-ROC |
|---|---|---|---|---|---|
| Random Forest | 0.7271 | 0.7737 | 0.8725 | 0.8197 | 0.7561 |
| Logistic Regression | 0.7254 | 0.7504 | 0.9228 | 0.8270 | 0.7538 |
| XGBoost | 0.7047 | 0.7693 | 0.8390 | 0.8012 | 0.7463 |
| AdaBoost | 0.7031 | 0.7570 | 0.8654 | 0.8053 | 0.7295 |
| Gradient Boosting | 0.7013 | 0.7565 | 0.8582 | 0.8037 | 0.7287 |
Logistic Regression 在 Recall(0.9228)和 F1-Score(0.8270)上表现最佳,适合医疗筛查场景(低漏诊率优先)。
描述性统计
| 统计项 | 原论文 | AI 复现 |
|---|---|---|
| 样本量 | 583 | 583 |
| 肝病患者数 | 416 (71.4%) | 416 (71.4%) |
| 非肝病患者数 | 167 (28.6%) | 167 (28.6%) |
| 男性患者数 | 441 | 441 |
| 女性患者数 | 142 | 142 |
| 缺失值 | AG Ratio 列 4 个 | AG Ratio 列 4 个,中位数填充 |
差距原因分析
Random Forest 准确率差距(85.17% vs 72.71%,差 12.5 个百分点)主要源于以下方法学差异:
- 超参数调优深度:原论文使用 RandomizedSearchCV 广搜 + GridSearchCV 精搜的两阶段策略,这是该论文的核心方法论贡献。AI 使用默认或基础参数,未进行同等深度的调优。
- 特征选择:原论文从 10 个特征中选择了 7 个最相关特征建模,AI 使用全部 10 个特征,多余特征可能引入噪声。
- 评估方式差异:AI 报告的是 10 折交叉验证的平均值,原论文可能报告的是最优 split 或调优后的最终模型在测试集上的单次表现。
AI做到了什么
- 4 分钟内完成 5 种模型的训练和 10 折交叉验证评估
- 特征重要性排序与原论文完全一致(Top 5 吻合率 100%)
- 额外完成了 SHAP 可解释性分析(原论文未做),提供了更细粒度的特征影响解读
- 发现 Logistic Regression 在 Recall 上表现最优(0.9228),为医疗筛查场景提供了有价值的参考
- 生成完整的分析报告和可复用的图表
AI没做到什么
- 未实现两阶段超参数调优:这是原论文的核心方法论贡献,AI 仅使用默认参数,导致 Random Forest 准确率低约 12.5 个百分点
- 未进行特征选择优化:原论文从 10 个特征中筛选了 7 个,AI 使用全部特征
- 未处理类别不平衡:数据集肝病/非肝病比例 71.4%:28.6%,原论文和 AI 都未使用过采样技术,但这可能影响少数类的预测性能
- 混淆矩阵分析不够深入:原论文给出了具体的 TP/TN/FP/FN 数字(94/107/20/15),AI 未详细列出
- 临床解读缺失:特征重要性的医学解释(为什么胆红素是最强预测因子)需要肝病专业知识
结论
AI 在 4 分钟内验证了 El Atifi 等人研究的核心结论:胆红素指标和肝酶指标是肝病最强预测因子,Random Forest 是综合最优模型。特征重要性排序 Top 5 完全一致,证明了研究结论的可复现性。
性能差距(12.5 个百分点)源于超参数调优深度差异,这正是原论文的核心贡献——证明了系统化超参数调优对小样本数据集的重要性。AI 可以快速建立 baseline 验证结论方向,但达到发表水平的性能优化仍需研究者的专业判断和方法学创新。