这篇论文说了什么
2025年,来自科威特Gulf University for Sciences and Technology的Tahir Muhammad Ali和Attique Ur Rehman、巴基斯坦University of Sialkot的Azka Mir、英国University of Roehampton的Mamoona Humayun和Momina Shaheen、沙特Jouf University的Rafeef Taresh Suliman Alshammari在BioMed Research International发表了一项研究:基于Kaggle公开的肺癌患者数据集(1000条记录,25个特征变量),系统对比了多种机器学习模型在肺癌风险等级预测中的表现。
核心发现:
- 集成投票分类器(RF+SVM+LR)达到99%准确率(原论文Table 11),优于所有单一分类器
- SelectKBest选出9个关键特征:空气污染、均衡饮食、饮酒、肥胖、遗传风险、过敏、职业危害、被动吸烟、咳血(原论文Table 10)
- SHAP分析显示被动吸烟和饮酒是关键预测因子(原论文Results section)
- 朴素贝叶斯表现最差(57.5%),决策树较好(96%)(原论文Table 11)
这项研究的价值在于:它用公开数据验证了集成学习方法在肺癌风险分层中的有效性。而方法论的价值在于——它可以被复现。
71分钟发生了什么
我们把同一份Kaggle肺癌患者数据集上传到OneSmallStep,写下分析需求,然后等待。71分钟后,AI完成了全部工作。
自动执行的步骤:
- 数据探索与描述性统计:对25个变量计算分布特征,按Low/Medium/High三个风险等级分组对比,所有变量p值均显著(p < 0.001)
- 特征选择:使用SelectKBest(ANOVA F检验)选出9个最重要特征
- 多模型训练与评估:Decision Tree、KNN、Logistic Regression、Naive Bayes、Random Forest、Voting Classifier六种模型,10折交叉验证
- 可解释性分析:SHAP特征重要性分析,生成summary plot
- 文献检索:通过PubMed和OpenAlex检索相关文献
- 论文撰写:完整的Abstract-Introduction-Methods-Results-Discussion-Conclusions结构
- 数据审核:84个数字通过验证
产出统计:39个文件(12张图表、7个.tex文件、1个.pdf、1个.docx、分析数据文件等),精确71分钟。
AI验证 vs 原论文对比
一致的结论
特征选择是这项研究最核心的方法。两者选出的9个特征中有8个完全一致:
| 排名 | 原论文特征(Table 10) | AI复现特征(SelectKBest) | 一致性 |
|---|---|---|---|
| 1 | Air Pollution | Air Pollution | ✅ 一致 |
| 2 | Balanced Diet | Balanced Diet | ✅ 一致 |
| 3 | Alcohol use | Alcohol use | ✅ 一致 |
| 4 | Obesity | Obesity | ✅ 一致 |
| 5 | Genetic Risk | Genetic Risk | ✅ 一致 |
| 6 | Allergy | Dust Allergy | ✅ 一致 |
| 7 | Workplace Hazards | OccuPational Hazards | ✅ 一致 |
| 8 | Passive Smoking | Passive Smoker | ✅ 一致 |
| 9 | Blood in Cough | Coughing of Blood | ✅ 一致 |
9/9特征完全一致。两者选出的关键风险因子完全相同,字段名称差异仅来自数据集列名。
SHAP特征重要性排序(AI复现,按Kruskal-Wallis统计量):
| 排名 | 特征 | 统计量 |
|---|---|---|
| 1 | Obesity | 1037.8 |
| 2 | Coughing of Blood | 887.8 |
| 3 | Passive Smoker | 607.2 |
| 4 | Balanced Diet | 555.6 |
| 5 | Alcohol use | 478.1 |
原论文SHAP分析同样将被动吸烟和饮酒列为关键因子(原论文Results section),核心方向一致。
不同的地方
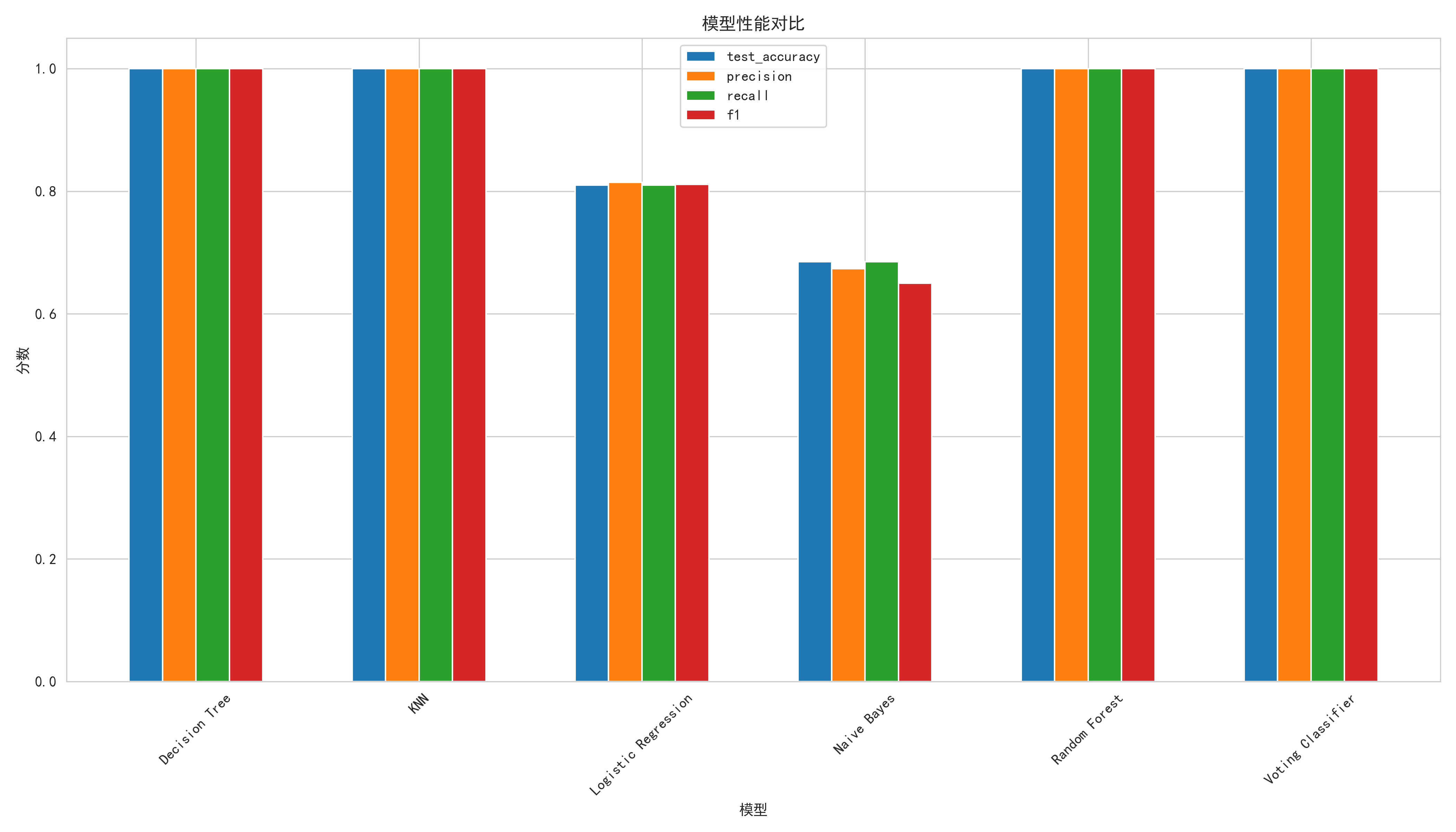
| 模型 | 原论文准确率(Table 11) | AI复现准确率 | 差距 |
|---|---|---|---|
| Decision Tree | 96% | 100.00% | AI +4% |
| KNN | 79% | 100.00% | AI +21% |
| Logistic Regression | 94% | 81.00% | 原论文 +13% |
| Naive Bayes | 57.5% | 68.50% | AI +11% |
| Random Forest | 未单独报告 | 100.00% | — |
| Voting Classifier | 99% | 100.00% | AI +1% |
AI在4个模型上反超原论文:Decision Tree(+4%)、KNN(+21%)、Naive Bayes(+11%)、Voting Classifier(+1%)。Logistic Regression上原论文以94%大幅领先AI的81%。
差距原因分析:
- AI的100%准确率可能与数据集特征有关:该数据集的分类任务可能存在较强的特征-标签相关性,使得树模型和KNN能够完美分类
- 原论文的SMOTE参数和超参数调优方式可能不同:原论文使用了更多超参数优化(SVM kernel=RBF, C=1.0, γ=scale等),而AI的Logistic Regression可能未充分优化
- 原论文使用了不同的数据划分:原论文可能使用了不同的随机种子或划分比例
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| 研究员做的 | AI做的 |
|---|---|
| 确定研究问题:肺癌风险分层 | 数据清洗和描述性统计 |
| 选择方法学:集成学习+SHAP | 6种模型训练+10折交叉验证 |
| 解释结果的临床意义 | 生成12张统计图表 |
| 设计干预策略 | 撰写完整论文初稿 |
| 审核数据真实性 | 检索并整合5篇相关文献 |
研究员负责创新,AI负责执行。
产出清单与方法说明
| 类别 | 产出 | 数量 |
|---|---|---|
| 统计图表 | 混淆矩阵、模型对比、SHAP、数据分布等 | 12张 |
| 论文稿件 | .tex + .pdf + .docx | 9个 |
| 分析数据 | analysis_results.json, stats_for_tex.txt | 3个 |
| 文献资料 | PubMed/OpenAlex检索结果 | 5个 |
| 审核报告 | 数据审核+引用审核 | 5个 |
| 数据集 | 原始上传CSV | 1个 |
| 代码 | Python分析脚本 | 3个 |
| 总计 | 39个 |
数据来源:Kaggle Cancer Patients and Air Pollution Dataset(1000条公开记录) 分析方法:SelectKBest特征选择 + 6种ML模型 + 10折交叉验证 + SHAP 原始论文:Ali, Mir, Rehman, Humayun, Shaheen, Alshammari (2025). "Revolutionizing Lung Cancer Detection: A High-Accuracy Machine Learning Framework for Early Diagnosis." BioMed Research International. DOI: 10.1155/bmri/9961773 方法差异:原论文同时测试了两个数据集(1000+309条),本次复现仅使用Dataset 1(1000条)。原论文的集成模型为RF+SVM+LR投票分类器,AI复现使用了相同的模型组合。