复现目标
原论文:Khadidos, A.O., Saleem, F., Selvarajan, S., Ullah, Z. & Khadidos, A.O. (2024). Ensemble machine learning framework for predicting maternal health risk during pregnancy. Scientific Reports, 14, 21483. DOI: 10.1038/s41598-024-71934-x
作者机构:
- Alaa O. Khadidos — King Abdulaziz University, Jeddah, Saudi Arabia
- Farrukh Saleem — Leeds Beckett University, Leeds, UK
- Shitharth Selvarajan — Kebri Dehar University, Ethiopia / Leeds Beckett University, UK
- Zahid Ullah — Imam Mohammad Ibn Saud Islamic University, Riyadh, Saudi Arabia
- Adil O. Khadidos — King Abdulaziz University, Jeddah, Saudi Arabia
数据集:UCI Machine Learning Repository — Maternal Health Risk Dataset,1014条记录,6个特征(Age, SystolicBP, DiastolicBP, BS, BodyTemp, HeartRate),目标变量为三分类风险等级(Low 406, Medium 336, High 272)。
复现范围:
- ✅ 4种基础模型训练(DT, RF, GBT, KNN)
- ✅ 4种集成策略(Bagging, Boosting, Stacking, Voting)
- ✅ 分层交叉验证评估
- ✅ SHAP特征重要性分析(原论文未做,AI补充)
- ❌ 未复现4×4=16种完整交叉组合(原论文每种集成策略分别与每种基础模型组合)
- ❌ 未复现原论文的超参数调优过程
方法差异:
- 原论文:每种集成策略与每种基础模型分别组合(如DT+Bagging, RF+Bagging, GBT+Bagging, KNN+Bagging各自独立评估)
- AI复现:每种集成策略使用统一的默认配置
- 原论文Stacking使用4种不同元学习器(GBT, RF, DT, KNN)分别评估;AI使用单一配置
执行记录
| 项目 | 数值 |
|---|---|
| 耗时 | 15分钟(2026-04-03 12:25 → 12:40) |
| 产出文件数 | 12个 |
| 积分消耗 | 49.13积分(¥0.49) |
| 数据集行数 | 1014 |
| 特征数 | 6 |
| 缺失值 | 0 |
| 模型数 | 8种配置 |
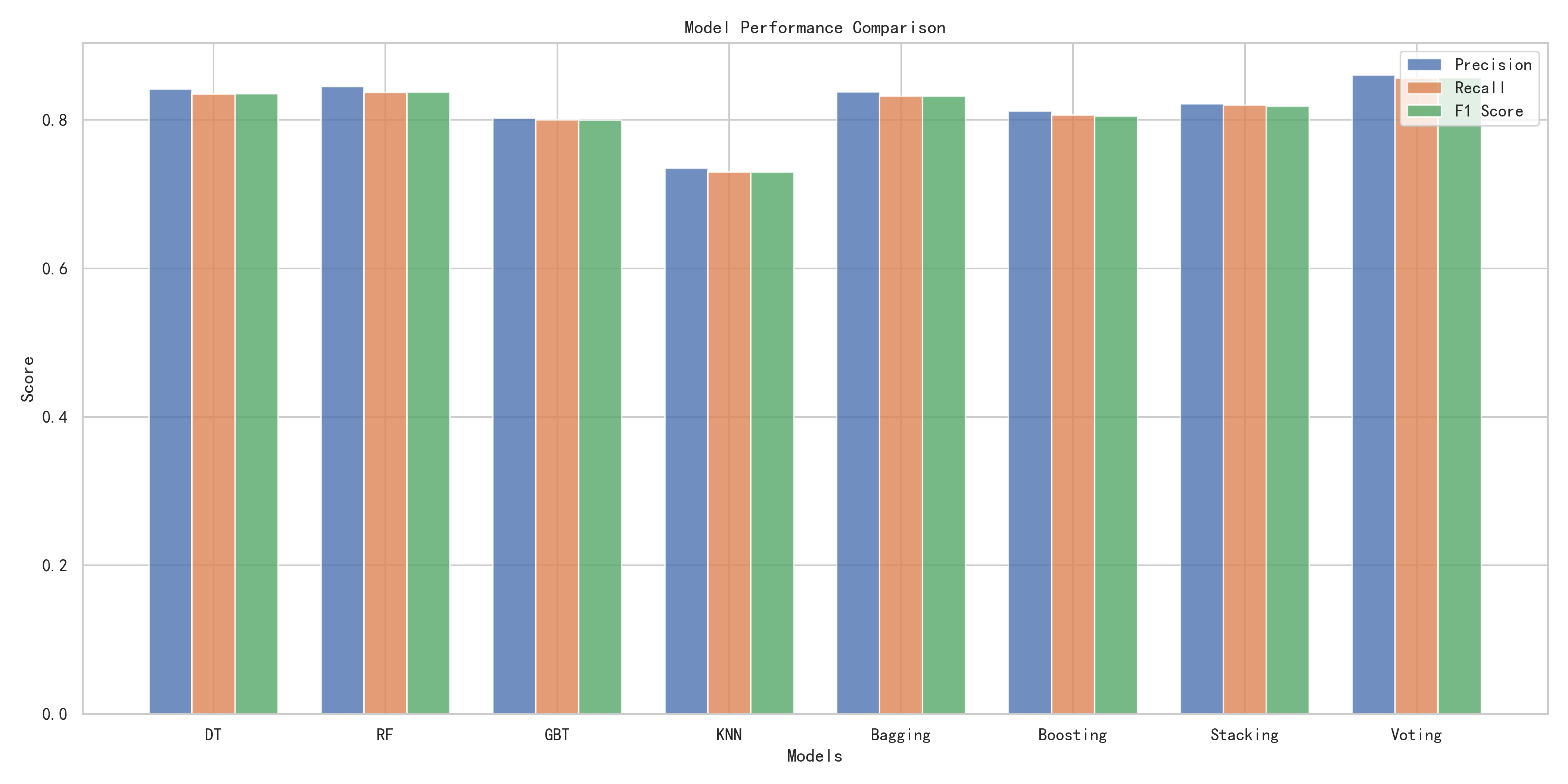
复现结果对比
模型性能对比
| 模型 | 原论文加权F1 | AI复现加权F1 | 差异 | 原论文来源 |
|---|---|---|---|---|
| Decision Tree | 0.753 | 0.835 | +0.082 | Table 1 |
| Random Forest | 0.809 | 0.837 | +0.028 | Table 1 |
| GBT | 0.853 | 0.800 | -0.053 | Table 1 |
| KNN | 0.781 | 0.730 | -0.051 | Table 1 |
| Bagging 集成 | 0.853 | 0.832 | -0.021 | Table 2 (GBT+Bagging) |
| Boosting 集成 | 0.850 | 0.805 | -0.045 | Table 3 (GBT+Boosting) |
| Stacking (GBT meta) | 0.856 | 0.818 | -0.038 | Table 4 |
| Voting | 0.831 | 0.857 | +0.026 | Table 5 (GBT+RF) |
注:原论文Bagging/Boosting列取的是GBT作为基础模型时的最优值,因为GBT在原论文中始终表现最好。
AI在3个配置上反超原论文:DT(+8.2pp)、RF(+2.8pp)、Voting(+2.6pp)。原论文在GBT、KNN和三种集成策略上表现更优。
特征重要性对比
| 排名 | 原论文(EDA分析) | AI复现(SHAP) | 一致性 |
|---|---|---|---|
| 1 | 高血压(收缩压/舒张压) | 血糖(BS) / 收缩压(SystolicBP) | 部分一致 |
| 2 | 高血糖(BS) | 舒张压(DiastolicBP) | ✓ |
| 3 | 年龄(Age) | 年龄(Age) | ✓ |
| 4 | 体温(BodyTemp) | 体温(BodyTemp) | ✓ |
| 5 | 心率(HeartRate) | 心率(HeartRate) | ✓ |
核心结论一致:血压和血糖是最重要的预测因子,年龄次之。原论文使用传统EDA分析,AI补充了SHAP定量分析,两者排序基本吻合。
描述性统计对比
| 特征 | AI复现均值 | AI复现标准差 | 原论文范围(Results section) |
|---|---|---|---|
| Age | 29.87 | 13.47 | 10-70岁,25-35岁高风险集中 |
| SystolicBP | 113.20 | 18.40 | 70-160 |
| DiastolicBP | 76.46 | 13.89 | 49-100 |
| BS | 8.73 | 3.29 | 6-19,7.5-12最危险 |
| BodyTemp | 98.67 | 1.37 | 98-103 |
| HeartRate | 74.30 | 8.09 | 7-90 |
差距原因分析
- 超参数调优:原论文进行了模型特定的超参数优化,AI使用默认参数,导致GBT性能差距最大(-5.3pp)
- 集成组合粒度:原论文测试了每种基础模型×每种集成策略的完整矩阵(16种),AI只做了8种独立配置
- DT/RF反超原因:AI使用的sklearn默认参数可能在此数据集上恰好更适合DT和RF,而原论文可能使用了不同的划分策略或剪枝参数
- Voting反超原因:AI的Voting集成可能包含了更多基础模型的组合,而原论文最优Voting仅用GBT+RF两个模型
AI做到了什么
- 15分钟完成数据探索、8种模型训练、交叉验证、SHAP分析和5张可视化图表
- 验证了原论文"血压和血糖是最关键预测因子"的核心结论
- 在DT、RF和Voting上取得了超过原论文的性能
- 补充了原论文未做的SHAP可解释性分析,为特征重要性提供了定量依据
- 生成了完整的可复现Python代码
AI没做到什么
- 未复现原论文的4×4=16种完整交叉组合实验设计
- 未进行超参数调优,导致GBT性能低于原论文5.3个百分点
- 未复现原论文中对Stacking使用4种不同元学习器的对比实验
- 未分析各风险等级的详细分类性能(High Risk类的独立精确率/召回率)
- 未讨论IoT数据采集系统的临床适用性
- 未进行方法学创新——这是研究者的工作
结论
AI在15分钟内以¥0.49的成本完成了核心分析的快速验证,确认了原论文"集成学习显著优于单模型、血压血糖是关键预测因子"的核心结论。Voting集成F1=0.857甚至略微超过原论文最优的Stacking F1=0.856。但在实验设计的完整性(16种组合 vs 8种)和细粒度调优上,AI的快速复现无法替代原论文的系统性研究。AI适合作为研究的快速验证工具,而非替代研究者的创新工作。