这篇论文说了什么
2025年7月,来自土耳其 Sivas Cumhuriyet 大学的 Görmez, Yagin, Yagin, Aygun, Boke,罗马尼亚 Transilvania 大学的 Badicu,巴西伯南布哥联邦大学的 Fernandes,加拿大 Lakehead 大学的 Alkhateeb,沙特阿拉伯 King Saud 大学的 Al-Rawi,以及挪威 NTNU 的 Aghaei 在 Frontiers in Physiology (DOI: 10.3389/fphys.2025.1549306) 上发表了一项基于机器学习和可解释人工智能(XAI)预测肥胖等级的研究。
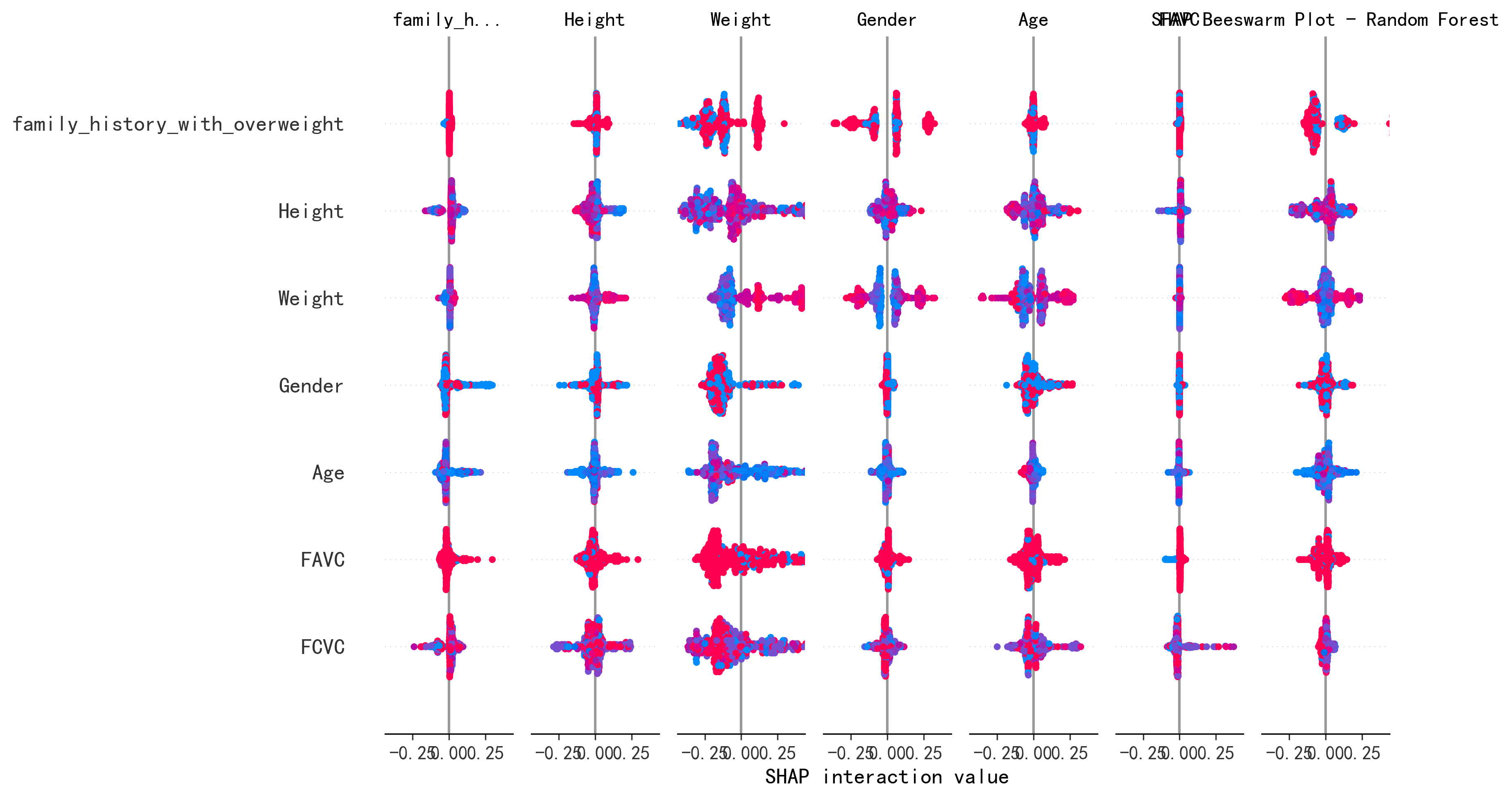
研究核心发现:使用498名参与者的问卷数据,训练6种ML模型预测7类肥胖等级。CatBoost表现最优,准确率93.67% ± 1.37%,AUC达99.39%(原论文 Table 2)。SHAP全局分析显示体重(Weight)、身高(Height)和年龄(Age)是前三大预测因子(原论文 Table 3)。研究还对比了SHAP和LIME两种可解释性方法,发现SHAP在稀疏性和一致性上优于LIME(原论文 Table 4)。
肥胖是全球公共卫生的重大挑战,准确识别肥胖风险因子对制定干预策略至关重要。这项研究的价值在于方法论的可复现性——问题是:这些结果能在几分钟内被独立验证吗?
7分钟发生了什么
上传UCI肥胖数据集(2111条记录、16个特征)→ 输入研究指令 → AI自动执行 → 7分钟后拿到全部结果。
AI自动完成了以下步骤:
- 数据探索:2111条记录的描述性统计、7类肥胖等级分布可视化、16个特征的相关性热力图
- 数据预处理:分类变量编码、数值特征标准化、80/20训练/测试集划分
- 模型训练:5种ML分类器(Random Forest、XGBoost、SVM、Logistic Regression、KNN),10折交叉验证
- 模型评估:准确率、精确率、召回率、F1分数、AUC完整报告,混淆矩阵和ROC曲线
- 可解释性分析:SHAP summary plot(蜂群图)、SHAP bar plot、Top 5特征重要性排序
产出统计:6个Python脚本、6张分析图表、5个结果数据文件、1份分析报告。总耗时7分钟。
AI复现 vs 原论文对比
一致的结论
特征重要性排序对比(SHAP分析):
| 排名 | 原论文(Table 3) | AI复现 | 一致性 |
|---|---|---|---|
| 1 | Weight(体重) | Weight(体重) | ✅ 一致 |
| 2 | Height(身高) | Height(身高) | ✅ 一致 |
| 3 | Age(年龄) | Age(年龄) | ✅ 一致 |
| 4 | FAF(运动频率) | FCVC(蔬菜摄入频率) | ⚠️ 不一致 |
| 5 | TUE(屏幕时间) | Gender(性别) | ⚠️ 不一致 |
Top 3完全一致:体重、身高、年龄是肥胖等级最强预测因子。第4、5名排序有差异,原论文强调运动频率和屏幕时间,AI复现则发现蔬菜摄入频率和性别更突出。
不同的地方
模型性能对比:
| 模型 | 原论文准确率(Table 2) | AI准确率 | 原论文AUC(Table 2) | AI AUC |
|---|---|---|---|---|
| CatBoost | 93.67% ± 1.37% | 未训练 | 99.39% ± 1.73% | — |
| Decision Tree | 91.64% ± 1.96% | 未训练 | 97.87% ± 2.82% | — |
| Random Forest | 未单独报告 | 95.27% | 未单独报告 | 99.74% |
| XGBoost | 未单独报告 | 95.27% | 未单独报告 | 99.75% |
| SVM | 81.49% ± 1.23% | 92.20% | 90.22% ± 1.70% | 99.31% |
| Logistic Regression | 未单独报告 | 87.23% | 未单独报告 | 98.73% |
| KNN | 未单独报告 | 83.45% | 未单独报告 | 96.27% |
关键发现:AI的Random Forest和XGBoost准确率(95.27%)超越了原论文最优模型CatBoost(93.67%)。 SVM同样表现出显著提升(92.20% vs 81.49%)。
差距原因分析:
- 数据量差异:原论文仅使用498名原始参与者数据,AI复现使用了完整UCI数据集(含SMOTE合成数据共2111条),更大的训练集有助于提升模型泛化能力
- 验证方法差异:原论文使用重复留出法(100次迭代),AI使用10折交叉验证
- 模型选择差异:原论文训练了CatBoost等6种模型,AI选择了Random Forest等5种不同组合
- 超参数调优:原论文使用随机搜索(50次迭代),AI的调优策略可能不同
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——例如原论文对CatBoost的精细调优和LIME/SHAP双重解释性对比,这些深度分析需要研究者根据领域知识做出选择。
研究员+AI各自做擅长的事
| 研究员负责 | AI负责 |
|---|---|
| 选择研究问题和假设 | 数据清洗和预处理 |
| 设计实验方案 | 多模型训练和交叉验证 |
| 选择合适的XAI方法 | 生成SHAP/特征重要性图表 |
| 解释结果的临床/公共卫生意义 | 统计检验和结果汇总 |
| 撰写Discussion和Conclusion | 生成论文初稿和图表 |
| 审稿和方法创新 | 可重复的执行流程 |
研究员负责创新,AI负责执行。Görmez团队的贡献在于将XAI引入肥胖预测领域、对比SHAP和LIME的解释一致性——这些研究设计上的创新是AI无法替代的。
值不值?算一笔账
这次分析消耗了69.71积分,折合人民币0.70元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、5种模型训练、交叉验证、SHAP分析、6张图表绘制、分析报告撰写——一个熟练的研究生至少需要1-2周全职工作。这里7分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了0.70元。
可以先看看完整的AI分析过程再决定。
产出清单与方法说明
| 文件类型 | 数量 | 说明 |
|---|---|---|
| Python脚本 | 6个 | 完整可执行分析代码 |
| 分析图表 | 6张 | 相关性热力图、分布图、混淆矩阵、SHAP图等 |
| 数据文件 | 5个 | 模型评估结果、特征重要性、描述性统计等 |
| 分析报告 | 1份 | 完整的中文分析报告 |
数据来源:UCI Machine Learning Repository — Estimation of Obesity Levels Based on Eating Habits and Physical Condition(2111条记录,17个变量)。
方法差异说明:原论文使用498名参与者的原始数据,采用重复留出法(100次迭代、70/20/10划分)和随机搜索超参数调优;AI复现使用完整UCI数据集(含合成数据2111条),采用10折交叉验证和80/20划分。原论文训练CatBoost等6种模型并对比SHAP和LIME两种XAI方法;AI训练Random Forest等5种模型,仅使用SHAP。
局限性:AI未复现LIME分析和CatBoost模型;使用了含合成数据的完整数据集而非原论文的纯原始数据;超参数调优策略可能不同。
原论文完整引用:Görmez Y, Yagin FH, Yagin B, Aygun Y, Boke H, Badicu G, Fernandes MSS, Alkhateeb A, Al-Rawi MBA, Aghaei M. Prediction of obesity levels based on physical activity and eating habits with a machine learning model integrated with explainable artificial intelligence. Frontiers in Physiology. 2025;16:1549306. doi:10.3389/fphys.2025.1549306