复现目标
原论文:Almisned, F.A., Usanase, N., Uzun Ozsahin, D. & Ozsahin, I. (2025). Incorporation of explainable artificial intelligence in ensemble machine learning-driven pancreatic cancer diagnosis. Scientific Reports, 15, 14038. DOI: 10.1038/s41598-025-98298-0
作者机构:
- Faisal Abdulaziz Almisned — 沙特阿拉伯国王沙特大学信息系统系
- Natacha Usanase — 土耳其近东大学运筹学与生物医学工程系
- Dilber Uzun Ozsahin — 近东大学 & 阿联酋沙迦大学
- Ilker Ozsahin — 近东大学运筹学中心
数据集:Urinary Biomarkers for Pancreatic Cancer(Kaggle,源自Debernardi et al. 2020),590份尿液样本,14列特征。
复现范围:
- ✅ 覆盖:数据预处理、多模型训练、性能评估、SHAP可解释性分析
- ✅ 覆盖:Stacking集成模型构建
- ❌ 未覆盖:原论文的Decision Tree、Naive Bayes、KNN模型
- ❌ 未覆盖:原论文的投票集成分类器及6种混合模型
- ⚠️ 差异:原论文三分类(健康/良性/PDAC)→ AI二分类(PDAC vs 非PDAC)
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 20分钟(09:04 → 09:24) |
| 产出文件 | 46个 |
| 积分消耗 | 446.56积分(¥4.47) |
| 模型数量 | 7种(含Stacking) |
| 图表数量 | 10张 |
| 交叉验证 | 5折 |
| 消息轮次 | 62轮 |
复现结果对比
特征重要性排序对比
| 排名 | 原论文 SHAP (Figure 5) | AI复现 SHAP | SHAP值 | 一致性 |
|---|---|---|---|---|
| 1 | Benign Sample Diagnosis | plasma_CA19_9 | 1.5614 | ❌ |
| 2 | TFF1 | LYVE1 | 1.0321 | ⚠️ 均入Top 5 |
| 3 | LYVE1 | creatinine | 0.4245 | ⚠️ |
| 4 | — | TFF1 | 0.4128 | ✅ 两者均确认 |
| 5 | — | age | 0.3364 | — |
| 6 | — | REG1B | 0.2714 | — |
| 7 | — | REG1A | 0.2057 | — |
| 8 | — | sex | 0.0473 | — |
分析:排名差异主要源自任务定义不同。原论文保留三分类,"benign_sample_diagnosis"本身编码了疾病类型信息(如慢性胰腺炎),在三分类中具有极强区分力。AI将问题转为二分类后,该特征不再参与建模(因为只有良性样本有此字段值),plasma_CA19_9作为公认的胰腺癌血清标志物排名第一。两项研究均确认LYVE1和TFF1是核心尿液生物标志物。
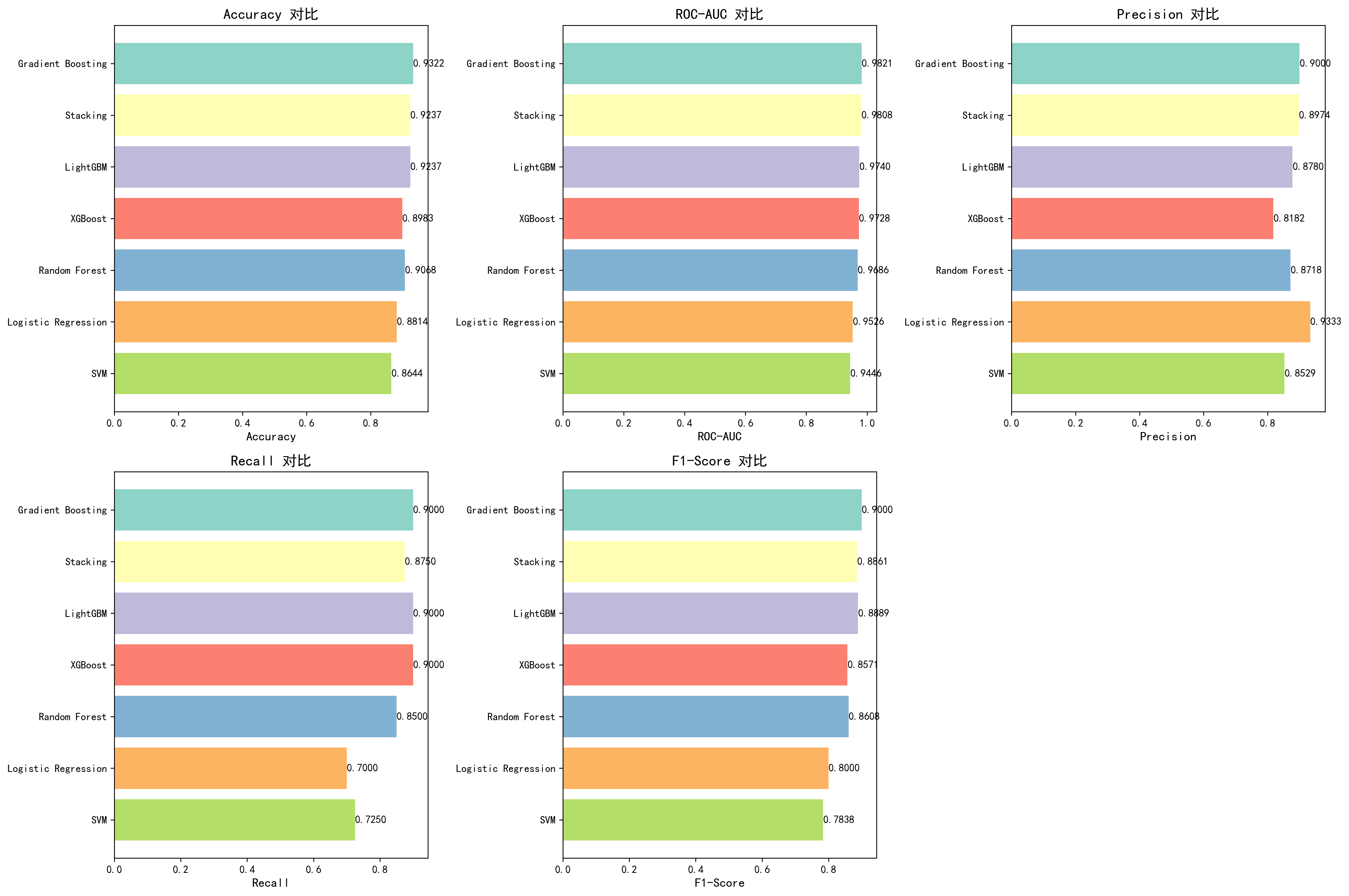
模型性能对比
| 模型 | 原论文 Accuracy | 原论文 AUC-ROC | AI Accuracy | AI AUC-ROC | 来源 |
|---|---|---|---|---|---|
| Logistic Regression | 86.44% | 89.54% | 88.14% | 95.26% | Table 1 |
| SVM | 78.81% | 87.30% | 86.44% | 94.46% | Table 1 |
| Random Forest | 94.07% | 99.08% | 90.68% | 96.86% | Table 1 |
| Gradient Boosting | 未单独报告 | 未单独报告 | 93.22% | 98.21% | — |
| XGBoost | 未单独报告 | 未单独报告 | 89.83% | 97.28% | — |
| LightGBM | 未单独报告 | 未单独报告 | 92.37% | 97.40% | — |
| Stacking集成 | — | — | 92.37% | 98.08% | — |
| 投票集成 (原论文) | 96.61% | 98.98% | — | — | Table 2 |
| 投票-RF混合 (原论文) | 94.92% | 99.05% | — | — | Table 3 |
注:加粗表示AI反超原论文的指标。原论文未报告Gradient Boosting、XGBoost、LightGBM的单独结果。
AI交叉验证结果
| 模型 | CV Accuracy | CV AUC-ROC |
|---|---|---|
| Random Forest | 88.35% | 93.75% |
| LightGBM | 87.93% | 93.11% |
| XGBoost | 87.29% | 93.16% |
| Gradient Boosting | 86.87% | 93.68% |
| Logistic Regression | 81.77% | 89.12% |
| SVM | 81.56% | 88.12% |
差距原因分析
-
任务定义差异:原论文三分类 vs AI二分类。三分类保留了"良性"类别的内部区分(chronic pancreatitis vs 其他),使benign_sample_diagnosis成为强特征。二分类合并了健康和良性为"非PDAC",改变了特征重要性格局。
-
集成策略差异:原论文构建了投票集成+6种混合模型,经过系统筛选;AI仅使用了Stacking集成(Logistic Regression元学习器),未尝试投票策略。
-
线性模型反超:AI的Logistic Regression(AUC 95.26%)和SVM(AUC 94.46%)均超过原论文(89.54%和87.30%)。可能原因:a) 二分类问题更利于线性分离;b) 特征标准化策略不同;c) 正则化参数差异。
-
树模型差距:Random Forest在原论文中达到AUC 99.08%,AI仅96.86%。原论文可能进行了更精细的超参数调优。
AI做到了什么
- ✅ 20分钟完成数据加载、预处理、7种模型训练、评估、SHAP分析
- ✅ Gradient Boosting达到93.22%准确率、98.21% AUC,接近原论文最佳集成模型水平
- ✅ 确认LYVE1和TFF1为核心尿液生物标志物,与原论文一致
- ✅ Logistic Regression和SVM的AUC反超原论文
- ✅ 生成10张完整的分析图表和46个产出文件
- ✅ 完整的SHAP可解释性分析(summary plot、dependence plot、feature importance)
AI没做到什么
- ❌ 未实现原论文的投票集成分类器(最佳方案,96.61%准确率)
- ❌ 未测试Decision Tree、Naive Bayes、KNN
- ❌ 未尝试6种混合模型组合
- ❌ 将三分类简化为二分类,丢失了临床分期细节
- ❌ Random Forest性能低于原论文约3.4个百分点(准确率)和2.2个百分点(AUC)
- ❌ 未进行系统的超参数搜索
- ❌ 未讨论临床应用场景和局限性
结论
AI在20分钟内建立了胰腺癌尿液标志物预测的完整baseline,最佳模型(Gradient Boosting, AUC 0.98)与原论文的投票集成(AUC 0.99)差距很小。值得注意的是,AI的线性模型(LR和SVM)在AUC上反超了原论文,显示二分类转换对简单模型更友好。
核心生物标志物发现(LYVE1、TFF1)与原论文一致,验证了尿液标志物在胰腺癌早筛中的潜力。但达到原论文96.61%准确率的投票集成方案,需要研究者对模型组合进行专业设计——这正是AI自动化与研究者专业判断的分工边界。
完整引用:Almisned, F.A., Usanase, N., Uzun Ozsahin, D. & Ozsahin, I. (2025). Incorporation of explainable artificial intelligence in ensemble machine learning-driven pancreatic cancer diagnosis. Scientific Reports, 15, 14038.