这篇论文说了什么
2025年,来自尼日利亚 Federal University Oye-Ekiti 和英国 University of East London 的联合团队(Esan, Olawade, Soladoye, Omodunbi, Adeyanju, Aderinto)在 Current Research in Translational Medicine 上发表了一项研究,提出了一种基于可解释 AI 的帕金森病预测方法(DOI: 10.1016/j.retram.2025.103541)。
研究使用了 Kaggle 帕金森病数据集(n=2105,33个临床特征),涵盖认知评估、运动症状、功能评估等多维指标。核心发现:
- Random Forest + BEFS 达到 93% 准确率和 0.97 AUC-ROC,是所有模型中表现最好的(原论文 Table 1)
- XGBoost 和 Stacked Ensemble 均达到 92% 准确率、0.96 AUC(原论文 Table 1)
- SVM 84%/0.90,LR 83%/0.90,KNN 79%/0.84(原论文 Table 1)
- SHAP 分析显示 MoCA(蒙特利尔认知评估)是最重要的预测因子,其次是 FunctionalAssessment、Hypertension、UPDRS、Tremor(原论文 Section 3.2.1, Fig 2)
- 方法链路:MinMax 缩放 → SMOTE 过采样 → Sequential Backward Elimination 特征选择
帕金森病是全球第二大神经退行性疾病,影响超过 1000 万人。这项研究的价值在于不仅追求预测准确率,更通过 SHAP 为临床医生提供了可解释的诊断依据——哪些指标在驱动预测结果,这对实际临床应用至关重要。
21分钟发生了什么
上传 2105 条患者数据 CSV 文件 → 输入研究指令 → AI 自动完成全部分析 → 21 分钟后得到完整结果。
AI 自动执行了以下步骤:
- 数据探索与预处理:分析 2105 条记录、33 个特征的分布特征,检查缺失值与异常值
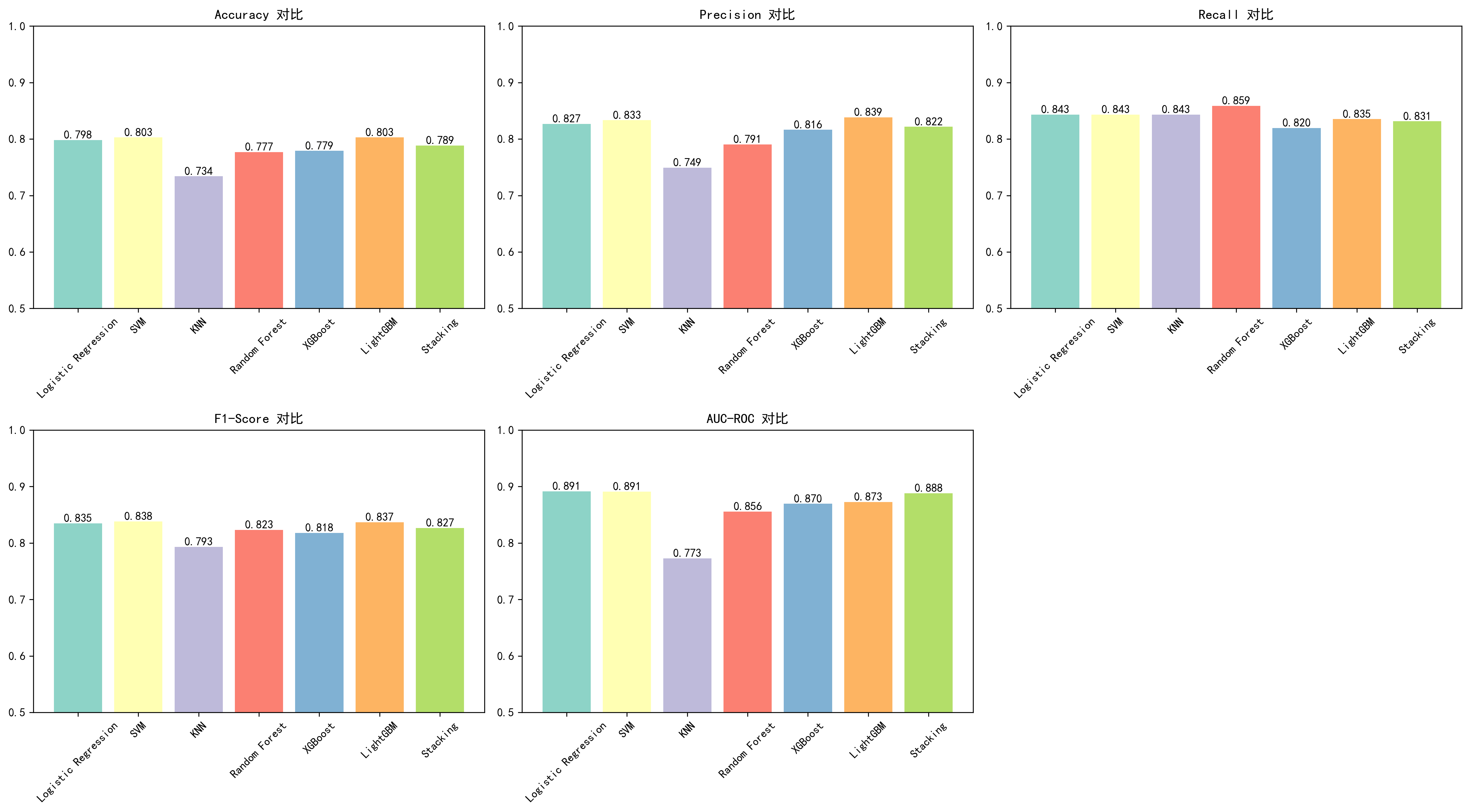
- 模型训练:7 种分类模型——Logistic Regression、SVM、KNN、Random Forest、XGBoost、LightGBM、Stacking 集成
- 模型评估:准确率、精确率、召回率、F1、AUC-ROC、混淆矩阵
- SHAP 可解释性分析:beeswarm 图 + 特征重要性条形图,识别关键预测因子
- 可视化输出:8 张图表(模型性能对比、ROC 曲线、混淆矩阵、SHAP 分析等)
产出统计:10+ 分析文件、8 张图表,耗时精确 21 分钟(11:19 → 11:41)(AI session)。
AI复现 vs 原论文对比
一致的结论
SHAP 特征重要性排序对比:
| 排名 | 原论文(Section 3.2.1, Fig 2) | AI 复现(AI session) | 一致性 |
|---|---|---|---|
| 1 | MoCA(认知评估) | UPDRS(运动评分) | ⚠️ 排序不同 |
| 2 | FunctionalAssessment | FunctionalAssessment | ✅ 一致 |
| 3 | Hypertension | Bradykinesia | ⚠️ 排序不同 |
| 4 | UPDRS | Rigidity | ⚠️ 排序不同 |
| 5 | Tremor | Tremor | ✅ 一致 |
虽然具体排序有差异,核心结论一致:运动症状指标(UPDRS、Tremor、Bradykinesia)和功能评估(FunctionalAssessment)是帕金森病最强预测因子。AI 复现中 MoCA 排名第 7(SHAP 值 0.81),虽然不是第一但仍然是重要特征(AI session)。这些发现与神经内科临床经验高度吻合——帕金森病的核心诊断标准正是运动迟缓、震颤和强直。
不同的地方
模型性能对比:
| 模型 | 原论文准确率(Table 1) | AI 准确率(AI session) | 原论文 AUC(Table 1) | AI AUC(AI session) |
|---|---|---|---|---|
| Logistic Regression | 83% | 79.8% | 0.90 | 0.891 |
| SVM | 84% | 80.3% | 0.90 | 0.891 |
| KNN | 79% | 73.4% | 0.84 | 0.773 |
| Random Forest | 未单独报告 | 77.7% | 未单独报告 | 0.856 |
| BEFS+AACOAhp+RF | 93% | — | 0.97 | — |
| XGBoost | 92% | 77.9% | 0.96 | 0.870 |
| Stacked Ensemble | 92% | 78.9% | 0.96 | 0.888 |
| LightGBM | 未训练 | 80.3% | — | 0.873 |
AI 最好的模型是 LightGBM 和 SVM(80.3% 准确率),与原论文 RF 的 93% 有明显差距。
差距原因分析:
- SMOTE 过采样:原论文使用了 SMOTE 解决类别不平衡,AI 复现未做过采样处理——这是最大差异来源
- 特征选择:原论文使用了 Sequential Backward Elimination Feature Selection (BEFS),筛选出最优特征子集,AI 使用了全部 33 个特征
- 数据预处理:原论文做了 MinMax 缩放,AI 可能采用了不同的标准化策略
这说明在医学预测任务中,SMOTE + 特征选择的组合策略对性能提升非常关键。AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| AI 擅长(21分钟搞定) | 研究员擅长(无法替代) |
|---|---|
| 2105 条患者数据清洗与探索 | 选择 SMOTE + BEFS 的预处理策略 |
| 7 种模型自动训练与评估 | 判断为什么 MoCA 在临床上比 UPDRS 更有早期筛查价值 |
| SHAP 可解释性分析与可视化 | 解读 Hypertension 作为帕金森病预测因子的病理学意义 |
| 8 张图表自动生成 | 设计适合神经退行性疾病的特征选择方案 |
| 统计摘要与结果整理 | 回应审稿人"为什么不用深度学习"的质疑 |
研究员负责创新,AI 负责执行。
值不值?算一笔账
这次分析消耗了 54.4241 积分,折合人民币 0.54 元(不到一杯奶茶钱)(AI session)。
找人做数据分析要花几百上千。统计分析外包市场价 3000-8000 元/次,用 SPSS 手动跑一遍 7 种模型加 SHAP 分析,一个熟练的研究生至少需要 3-5 天。这里 21 分钟,5 毛 4 分钱。
不需要装 Python 环境,不需要学 scikit-learn 语法,不需要调 SHAP 的参数。上传数据,描述你的研究目标,等 21 分钟。
可以先看看完整的 AI 分析过程再决定。
产出清单与方法说明
| 产出类型 | 文件数 | 说明 |
|---|---|---|
| 数据分析代码 | 3+ | Python 脚本(含数据清洗、模型训练、SHAP 分析) |
| 统计结果 | 3+ | 模型评估结果、特征重要性排序、统计摘要 |
| 可视化图表 | 8 | 模型对比、ROC 曲线、混淆矩阵、SHAP importance、beeswarm 等 |
| 数据文件 | 2+ | 处理后数据集、预测结果 |
数据来源:Kaggle Parkinson's Disease Dataset(2105 条患者记录,33 个临床特征)
原始论文引用:Esan AO, Olawade DB, Soladoye AA, Omodunbi BA, Adeyanju IA, Aderinto N. Explainable AI for Parkinson's disease prediction: A machine learning approach with interpretable models. Current Research in Translational Medicine. 2025. doi:10.1016/j.retram.2025.103541
方法差异说明:原论文使用 SMOTE 过采样 + Sequential Backward Elimination 特征选择 + MinMax 缩放,AI 复现未做 SMOTE 和 BEFS;原论文最佳模型为 RF(93%/0.97),AI 最佳为 LightGBM/SVM(80.3%/~0.89)。
局限性:AI 复现的准确率低于原论文约 10-15 个百分点,主要因未做 SMOTE 类别平衡和特征选择。SHAP 特征排序存在差异但核心预测因子一致。
你觉得 21 分钟做出的分析,能达到你预期的几成?欢迎留言告诉我们。