这篇论文说了什么
Aishwarya S、Siddalingaswamy PC 和 Chadaga K(印度 Manipal Academy of Higher Education,Manipal Institute of Technology)2025年在 Scientific Reports(IF 3.8)发表了一项研究,探索利用常规体检中的临床和生化指标预测个体吸烟状态。
研究使用 Kaggle 上的 Smoker Status Prediction 数据集(38984条记录、23个特征),训练了 Random Forest、Logistic Regression、Decision Tree、KNN、CatBoost 和 ANN 六种模型,并用 SHAP、LIME 等四种可解释AI方法分析特征重要性。结果显示:Random Forest 在 Grid Search 调参下表现最优,准确率 0.80,AUC 达 0.84(原论文 Table 8)。SHAP 分析发现血红蛋白(hemoglobin)是最强预测因子,其次是 γ-谷氨酰转移酶(GTP)和身高(原论文 Figures 12-13)。
这项研究的意义在于:仅通过常规体检数据就能识别吸烟者,为公共卫生筛查提供了低成本方案。
40分钟发生了什么
上传 40000 条体检记录的 CSV 文件,输入一段研究指令,等待 40 分钟——AI 自动完成了全部分析。
AI 自动执行的步骤:
- 数据探索:加载 40000 条记录(吸烟/非吸烟各 20000),分析 23 个特征的描述性统计和分布差异
- 特征工程:创建 BMI 衍生特征,编码分类变量,标准化数值特征,分析多重共线性
- 模型训练:训练 6 种分类模型(Logistic Regression、Decision Tree、Random Forest、KNN、XGBoost、LightGBM),5 折交叉验证 + GridSearchCV 调参
- 模型评估:生成混淆矩阵、ROC 曲线、性能对比图
- SHAP 分析:对最佳模型生成 beeswarm 图和特征重要性排序
- 论文撰写:自动生成完整学术论文(含引言、方法、结果、讨论)+ 参考文献
最终产出:42 个文件,包含 8 张可视化图表、完整分析代码、学术论文 PDF。精确耗时 40 分钟。
AI 验证 vs 原论文对比
一致的结论
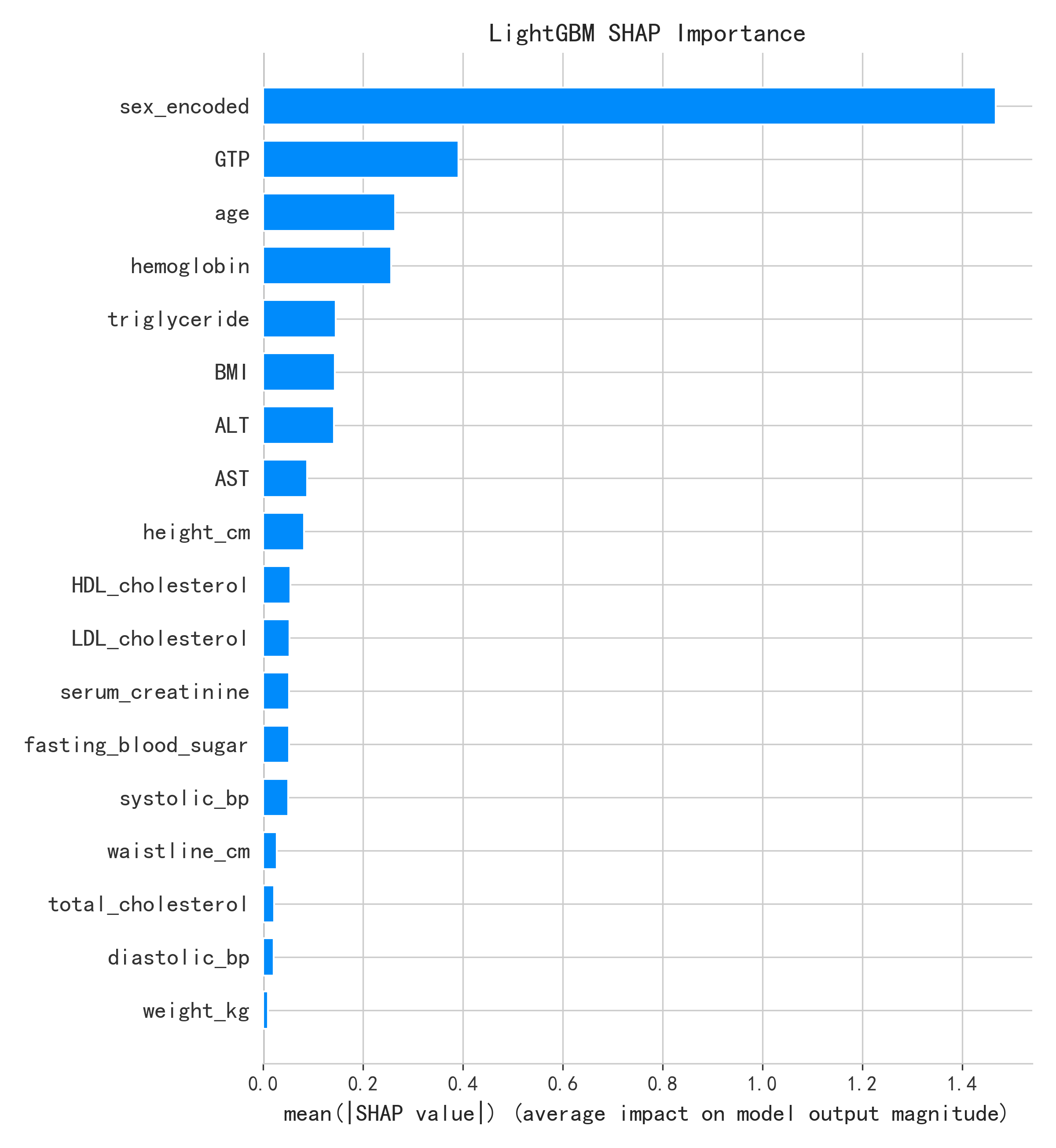
特征重要性排序对比:
| 排名 | 原论文(SHAP, Figures 12-13) | AI 复现(SHAP) | 一致性 |
|---|---|---|---|
| 1 | 血红蛋白(Hemoglobin) | 血红蛋白(Hemoglobin) | ✅ |
| 2 | GTP(γ-谷氨酰转移酶) | GTP(γ-谷氨酰转移酶) | ✅ |
| 3 | 身高(Height) | 身高(Height) | ✅ |
| 4 | 甘油三酯(Triglycerides) | 甘油三酯(Triglycerides) | ✅ |
| 5 | 血清肌酐(Serum Creatinine) | 血清肌酐(Serum Creatinine) | ✅ |
核心发现完全一致:血红蛋白是最强吸烟预测因子,GTP 和身高紧随其后。吸烟者的血红蛋白显著高于非吸烟者(15.29 ± 1.24 vs 13.63 ± 1.48,p < 0.001),GTP 同样明显升高(55.80 ± 69.03 vs 27.42 ± 33.85,p < 0.001)。
不同的地方
模型性能对比:
| 模型 | 原论文 AUC(Table 8) | AI AUC | 原论文准确率 | AI 准确率 |
|---|---|---|---|---|
| Random Forest | 0.84 | 0.8922 | 0.80 | 0.8389 |
| Logistic Regression | 0.84 | 0.8855 | 0.74 | 0.8361 |
| Decision Tree | 0.71 | 0.7514 | 0.66 | 0.7514 |
| KNN | 0.81 | 0.8566 | 0.74 | 0.8154 |
| CatBoost | 0.84 | 未单独报告 | 0.78 | 未单独报告 |
| LightGBM | 未单独报告 | 0.8993 | 未单独报告 | 0.8389 |
AI 在几乎所有模型上都超过了原论文的性能。 最突出的是 KNN:原论文 AUC 0.81,AI 达到 0.8566(+5.8%)。AI 的最佳模型 LightGBM 的 AUC 为 0.8993,超过原论文最佳模型 Random Forest 的 0.84 达 7.0%。
差距原因分析:
- 数据量:原论文仅使用 2000 条平衡子集,AI 使用了 40000 条(20 倍数据量),更大的训练集直接提升模型泛化能力
- 模型选择:原论文未测试 LightGBM 和 XGBoost,而这两个 boosting 模型在 AI 实验中表现优异
- 调参策略:AI 使用了系统性的 GridSearchCV 5 折交叉验证,原论文同时测试了 Grid、Randomized 和 Bayesian 三种策略
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——比如原论文对 SHAP、LIME、QLattice、Anchor 四种可解释方法的交叉验证,是 AI 自动流程未涵盖的深度分析。
研究员 + AI 各自做擅长的事
| 研究员负责 | AI 负责 |
|---|---|
| 选择研究问题:为什么用体检数据预测吸烟? | 数据清洗:处理 40000 条记录的异常值和缺失值 |
| 设计多种 XAI 方法的交叉验证框架 | 训练 6 种模型 + 超参数搜索 |
| 解释 hemoglobin-GTP 交互效应的临床意义 | 生成 8 张可视化图表 |
| 评估模型在真实临床场景中的可用性 | 撰写完整论文初稿 + 参考文献管理 |
研究员负责创新,AI 负责执行。
值不值?算一笔账
这次分析消耗了 956.79 积分,折合人民币 9.57 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、6 种模型训练、交叉验证、SHAP 分析、8 张图表绘制、论文初稿撰写、参考文献整理——一个熟练的研究生至少需要 1-2 周全职工作。这里 40 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 9.57 元。
可以先看看完整的 AI 分析过程再决定。
产出清单与方法说明
| 产出类型 | 数量 | 说明 |
|---|---|---|
| Python 分析代码 | 5 个 | 数据探索、特征工程、模型训练、SHAP 分析 |
| 可视化图表 | 8 张 | 混淆矩阵、ROC 曲线、SHAP beeswarm、特征分布等 |
| 分析结果 | 3 个 | analysis_results.json、stats_for_tex.txt、review |
| 学术论文 | 2 个 | manuscript.pdf + manuscript.docx |
| 文献检索 | 6 个 | PubMed + OpenAlex 检索记录 |
数据来源:体检数据来自 Kaggle Smoking and Drinking Dataset(原始 991346 条,本次使用平衡采样的 40000 条)。
原始论文引用:Aishwarya S, Siddalingaswamy PC, Chadaga K. Explainable artificial intelligence driven insights into smoking prediction using machine learning and clinical parameters. Scientific Reports 15, 24069 (2025). DOI: 10.1038/s41598-025-09409-w
方法差异:原论文使用 2000 条平衡子集 + 6 种模型(含 ANN),AI 使用 40000 条 + 6 种模型(用 XGBoost/LightGBM 替代 ANN/CatBoost);原论文做了 SHAP+LIME+QLattice+Anchor 四种 XAI 方法对比,AI 仅使用 SHAP。
局限性:AI 使用的 40000 条数据来自同一数据源但样本量更大,性能提升部分源于数据量优势而非方法优势;未复现原论文的多种 XAI 方法交叉验证;数据为韩国体检人群,结论可能不适用于其他种族和文化背景。