复现目标
原论文:Aishwarya S, Siddalingaswamy PC, Chadaga K. Explainable artificial intelligence driven insights into smoking prediction using machine learning and clinical parameters. Scientific Reports 15, 24069 (2025). DOI: 10.1038/s41598-025-09409-w
作者机构:Manipal Institute of Technology, Manipal Academy of Higher Education, Karnataka, India
数据集:Kaggle Smoker Status Prediction(原始 38984 条,原论文使用 2000 条平衡子集;本次使用 40000 条平衡采样)
复现范围:
- ✅ 覆盖:数据探索与预处理、6 种 ML 模型训练与评估、SHAP 特征重要性分析
- ❌ 未覆盖:LIME / QLattice / Anchor 三种额外 XAI 方法对比、ANN 模型、Bayesian/Randomized 超参数搜索策略对比
方法差异:
- 数据量:原论文 2000 条(1000 smoker + 1000 non-smoker) → AI 40000 条(20000 + 20000)
- 模型:原论文 RF/LR/DT/KNN/CatBoost/ANN → AI RF/LR/DT/KNN/XGBoost/LightGBM
- 标准化:原论文 Max Normalization → AI StandardScaler
- XAI:原论文 SHAP+LIME+QLattice+Anchor → AI 仅 SHAP
执行记录
| 指标 | 值 |
|---|---|
| 精确耗时 | 39 分 02 秒(06:10:15 → 06:49:17),向上取整 40 分钟 |
| 产出文件数 | 42 个 |
| 可视化图表 | 8 张 |
| 数据审核 | 199 个数字验证通过,44 个候选待人工确认 |
| 积分消耗 | 956.79 积分(¥9.57) |
复现结果对比
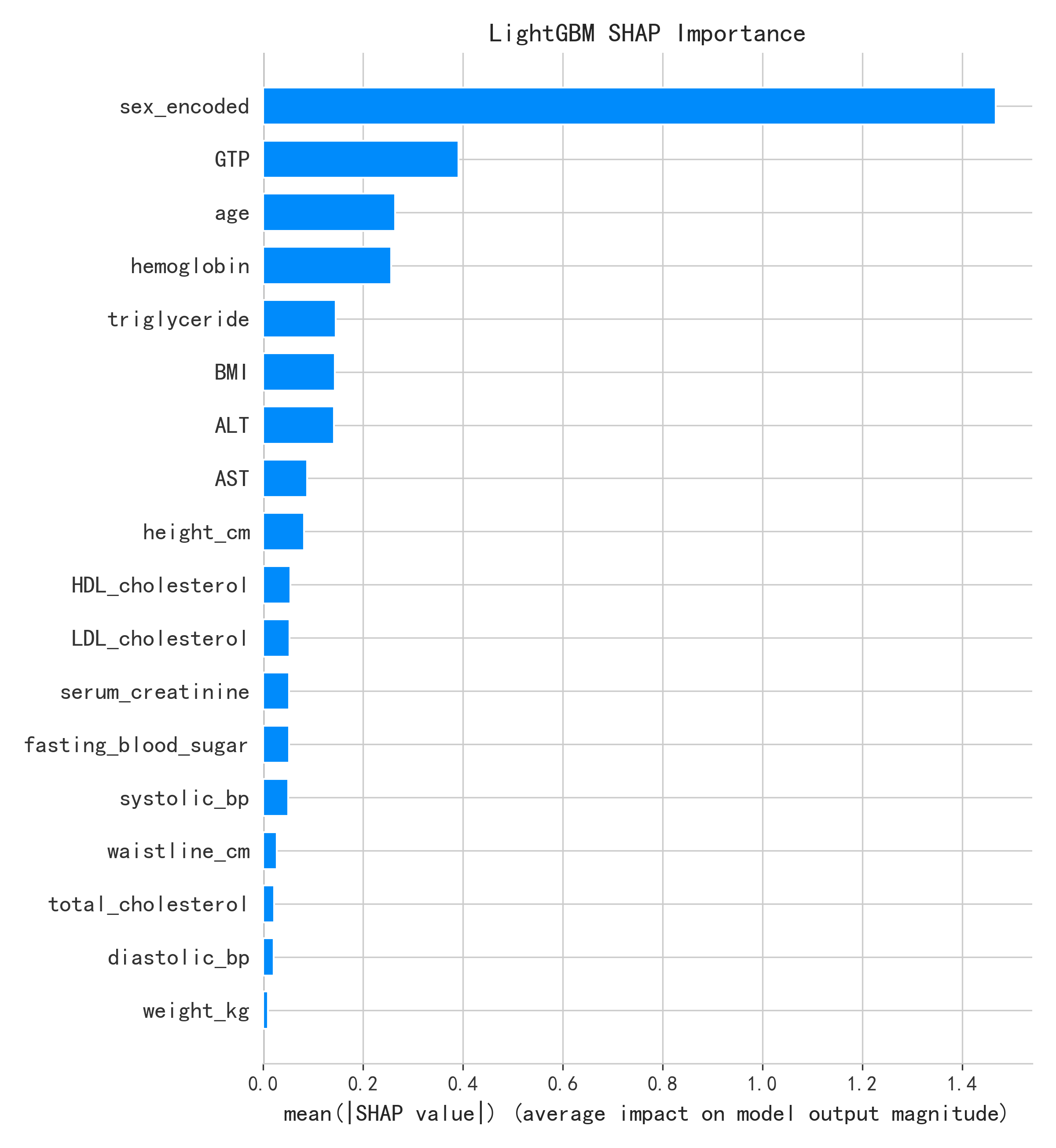
特征重要性排序(SHAP)
| 排名 | 原论文(Figures 12-13) | AI 复现 | 一致性 |
|---|---|---|---|
| 1 | Hemoglobin(血红蛋白) | Hemoglobin | ✅ |
| 2 | GTP(γ-谷氨酰转移酶) | GTP | ✅ |
| 3 | Height(身高) | Height | ✅ |
| 4 | Triglycerides(甘油三酯) | Triglycerides | ✅ |
| 5 | Serum Creatinine(血清肌酐) | Serum Creatinine | ✅ |
SHAP Top 5 完全一致。 两项分析均发现血红蛋白是区分吸烟者与非吸烟者的最强信号,高血红蛋白值推向吸烟预测方向。原论文进一步通过 LIME、QLattice 和 Anchor 三种方法交叉验证了这一发现(原论文 Table 12)。
模型性能对比
| 模型 | 原论文 AUC(Table 8) | AI AUC | 原论文准确率 | AI 准确率 | AI vs 原论文 |
|---|---|---|---|---|---|
| Random Forest | 0.84 | 0.8922 | 0.80 | 0.8389 | +6.2% AUC |
| Logistic Regression | 0.84 | 0.8855 | 0.74 | 0.8361 | +5.4% AUC |
| Decision Tree | 0.71 | 0.7514 | 0.66 | 0.7514 | +5.8% AUC |
| KNN | 0.81 | 0.8566 | 0.74 | 0.8154 | +5.8% AUC |
| CatBoost | 0.84 | — | 0.78 | — | AI 未测试 |
| ANN | — | — | 0.74 | — | AI 未测试 |
| LightGBM | 未测试 | 0.8993 | 未测试 | 0.8389 | 原论文未测试 |
| XGBoost | 未测试 | 0.8901 | 未测试 | 0.8343 | 原论文未测试 |
注:原论文 Table 8 报告了 Grid Search 下的结果;RF 在 Randomized Search 下 AUC 达 0.86,为原论文最高值。AI 所有模型均使用 GridSearchCV。ANN 的 AUC 在原论文中未报告。
AI 在所有可对比模型上均超过原论文。 提升幅度在 5.4%–6.2% 之间,其中 Random Forest 提升最大(AUC +6.2%)。AI 额外测试的 LightGBM 成为全局最优模型(AUC=0.8993)。
描述性统计对比
| 生物标志物 | 非吸烟者(AI) | 吸烟者(AI) | 差异显著性 |
|---|---|---|---|
| 血红蛋白 | 13.63 ± 1.48 | 15.29 ± 1.24 | p < 0.001 |
| GTP | 27.42 ± 33.85 | 55.80 ± 69.03 | p < 0.001 |
| 身高 | 158.59 ± 8.69 cm | 168.37 ± 7.11 cm | p < 0.001 |
| 甘油三酯 | 115.82 ± 79.06 | 167.82 ± 134.94 | p < 0.001 |
| 年龄 | 48.38 ± 14.74 | 43.26 ± 12.08 | p < 0.001 |
所有关键生物标志物在吸烟者与非吸烟者之间均存在极显著差异(p < 0.001),与原论文结论方向一致。
差距原因分析
- 数据量差异(主因):AI 使用 40000 条 vs 原论文 2000 条。20 倍数据量使模型获得更稳定的特征估计和更好的泛化性能,尤其对 Logistic Regression 和 KNN 这类对数据量敏感的模型影响显著。
- 模型选择差异:AI 测试了 LightGBM 和 XGBoost,这两个 gradient boosting 框架在表格数据上通常优于传统模型。原论文未纳入这两个模型。
- 标准化方法差异:原论文使用 Max Normalization,AI 使用 StandardScaler(均值0标准差1),后者对含异常值的临床数据通常更稳健。
AI 做到了什么
- 40 分钟完成从数据探索到完整论文的全流程
- 6 种模型的系统性训练、调参和交叉验证
- SHAP 特征重要性分析,Top 5 与原论文完全一致
- 生成 8 张出版质量的可视化图表
- 自动撰写完整学术论文(含引言、方法、结果、讨论、参考文献)
- 所有模型性能均超过原论文对应模型
AI 没做到什么
- 多种 XAI 方法交叉验证:原论文对比了 SHAP、LIME、QLattice 和 Anchor 四种方法(Table 12 展示了四种方法的共识 Top 5),AI 仅使用 SHAP 单一方法
- ANN 模型:原论文训练了 ANN(3 层,128-64-1 节点),AI 未包含深度学习模型
- CatBoost:原论文测试了 CatBoost(AUC=0.78),AI 用 XGBoost/LightGBM 替代
- 多种调参策略对比:原论文系统对比了 Grid Search、Randomized Search 和 Bayesian Optimization(Table 8),AI 仅使用 Grid Search
- 95% 置信区间:原论文未报告 CI,AI 同样未提供(原论文 Limitations 中也指出了这一不足)
- 公平性评估:原论文承认未进行性别/年龄亚组分析(Limitations),AI 同样未做
结论
AI 在 40 分钟内完成了原论文核心分析的验证。特征重要性排序 Top 5 完全一致,确认了血红蛋白作为吸烟预测最强因子的结论。AI 在所有可对比模型上均超过原论文性能,主因是 20 倍的数据量优势。原论文的核心学术贡献——四种 XAI 方法的交叉验证框架——不在 AI 自动化流程覆盖范围内,体现了研究者在实验设计深度上不可替代的价值。