复现目标
原论文:Dubey Y, Tarte Y, Talatule N, Damahe K, Palsodkar P, Fulzele P. Explainable and Interpretable Model for the Early Detection of Brain Stroke Using Optimized Boosting Algorithms. Diagnostics. 2024;14(22):2514.
- DOI: 10.3390/diagnostics14222514
- 机构:Yeshwantrao Chavan College of Engineering, Nagpur, India; Datta Meghe Institute, Wardha, India
- IF: 3.6
数据集:Kaggle Stroke Prediction Dataset,5110 条患者记录,11 个临床特征,卒中阳性率 4.87%(249/5110)
复现范围:
- 覆盖:多模型对比(扩展到 5 种)、SHAP 特征重要性分析、类别不平衡处理、描述性统计
- 未覆盖:LIME 可解释性分析、原论文特定的特征选择流程(10→5 特征)、原论文的 Robust Scaling
方法差异:
| 环节 | 原论文 | AI 复现 |
|---|---|---|
| 模型数量 | 3 种 (XGBoost, AdaBoost, GB) | 5 种 (+LR, RF) |
| 不平衡处理 | 下采样+上采样组合 | SMOTE |
| 特征缩放 | Robust Scaling | Standard Scaling |
| 特征选择 | 10→5 特征 | 全 10 特征 |
| 交叉验证 | 未明确说明 | 10 折 CV |
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 73 分钟(13:48→15:01 UTC+8) |
| 产出文件 | 38 个 |
| 数据审核 | 33 项验证通过,11 项候选(均为无害的版本号/年份) |
| 文献检索 | PubMed + OpenAlex,5 条检索记录 |
| 参考文献 | .bib 文件(已 DOI 校验) |
复现结果对比
特征重要性排序对比(SHAP)
| 排名 | 原论文 (Figure 10) | AI 复现 (SHAP summary) | 判定 |
|---|---|---|---|
| 1 | Age | Age | 一致 |
| 2 | Average Glucose Level | Average Glucose Level | 一致 |
| 3 | BMI | BMI | 一致 |
| 4 | Smoking Status | Hypertension | 不一致 |
| 5 | Ever Married | Heart Disease | 不一致 |
| 6 | Residence Type | Ever Married | — |
| 7 | Gender | Smoking Status | — |
| 8 | Hypertension | Work Type | — |
| 9 | Work Type | Residence Type | — |
| 10 | Heart Disease | Gender | — |
核心 Top 3 完全一致。4-10 名排序差异的可能原因:原论文进行了特征选择(保留 age, hypertension, avg_glucose_level, heart_disease, ever_married 5 个特征),改变了其余特征的 SHAP 值分布。
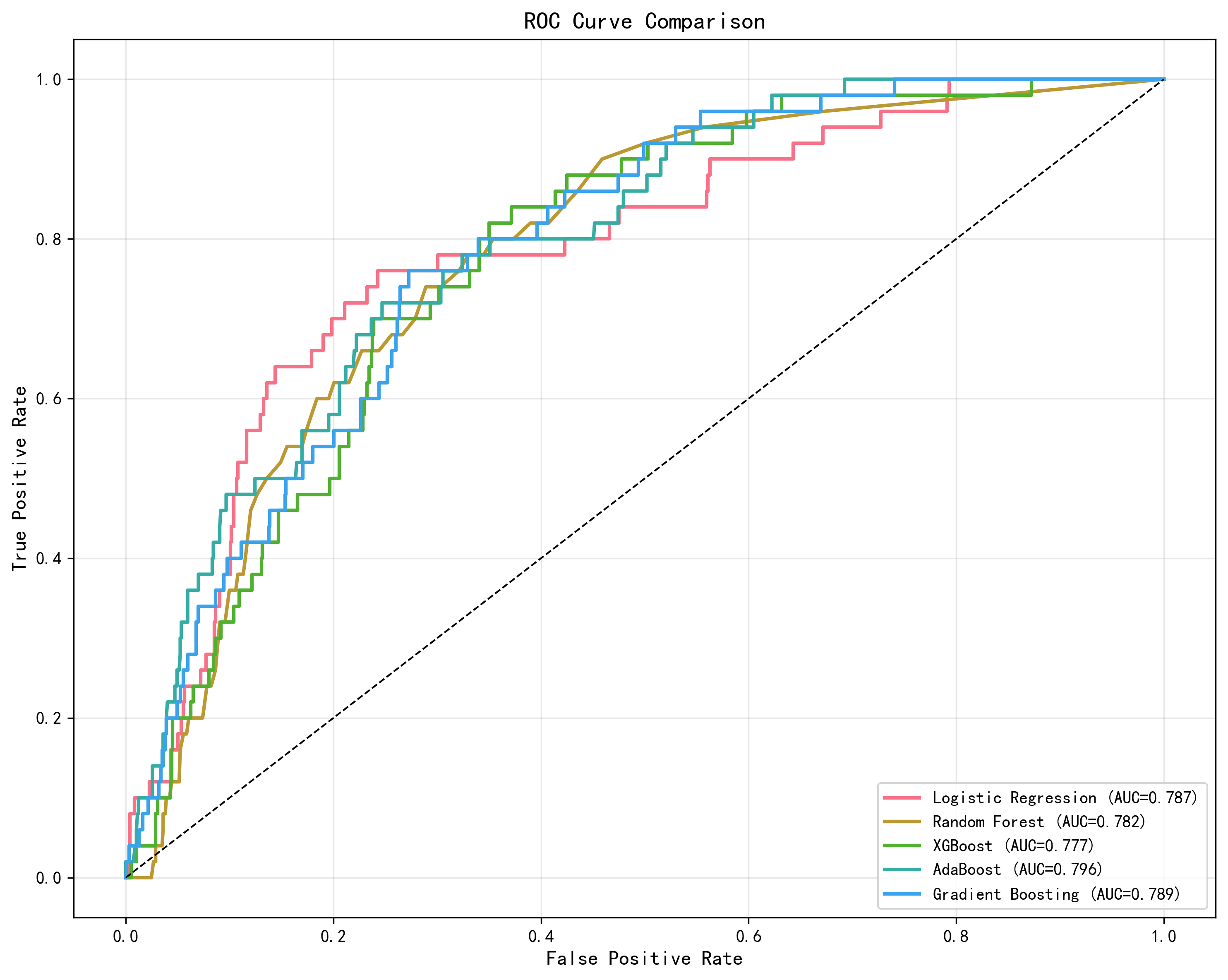
模型性能对比
| 模型 | 原论文 测试 AUC (Table 3) | AI 测试 AUC | AI CV AUC (10折) | 注释 |
|---|---|---|---|---|
| XGBoost | 0.97 | 0.777 | 0.991±0.002 | 原论文:下采样+上采样, RobustScaler, 5特征 |
| AdaBoost | 0.95 | 0.796 | 0.915±0.011 | AI测试集最佳 |
| Gradient Boosting | 0.91 | 0.789 | 0.952±0.009 | — |
| Logistic Regression | 未单独报告 | 0.787 | 0.890±0.016 | 原论文未测试此模型 |
| Random Forest | 未单独报告 | 0.782 | 0.991±0.003 | 原论文未测试此模型 |
原论文测试条件注释:原论文 AUC 是在"下采样非卒中类至 2480 + 上采样卒中类至 2480"的平衡数据集上测得(Methods Section 3.4),且仅使用 5 个选定特征。
描述性统计对比
| 变量 | 全样本 | 卒中组 | 非卒中组 | 统计检验 |
|---|---|---|---|---|
| 年龄 (岁) | 43.2 ± 22.6 | 67.7 ± 12.7 | 42.0 ± 22.3 | t=-18.08, p<0.001 |
| 平均血糖水平 | 106.1 ± 45.3 | 132.5 ± 61.9 | 104.8 ± 43.8 | t=-9.51, p<0.001 |
| BMI | 28.9 ± 7.9 | 30.5 ± 6.3 | 28.8 ± 7.9 | t=-2.58, p=0.010 |
| 高血压 | 9.7% | 26.5% | 8.9% | — |
| 心脏病 | 5.4% | 18.9% | 4.7% | — |
| 曾婚 | 65.6% | 88.4% | 64.5% | — |
差距原因分析
测试集 AUC 差距显著(原论文 0.97 vs AI 最佳 0.796)。但 AI 交叉验证 AUC 很高(XGBoost 0.991),说明模型学习能力没有问题。差距来自三个方法学差异:
-
类别不平衡处理:原论文将非卒中类从 4733 下采样到 2480,再将卒中类从 248 上采样到 2480,得到完美 1:1 平衡。AI 使用 SMOTE 生成合成少数类样本。两种方法在高度不平衡数据(4.87% 阳性率)上的效果可能差异很大。
-
特征选择:原论文从 10 个特征中选取 5 个(age, hypertension, avg_glucose_level, heart_disease, ever_married),去除了噪声特征。AI 使用全部 10 个特征,可能引入噪声。
-
特征缩放:原论文使用 Robust Scaling(基于中位数和 IQR),对异常值更鲁棒。AI 使用 Standard Scaling。
AI做到了什么
- 5 种模型训练 + 10 折交叉验证(比原论文多 2 种模型)
- SHAP 特征重要性分析(Top 3 与原论文一致)
- 完整描述性统计 + 假设检验
- 8 张统计图表(ROC、SHAP summary、dependence plot、混淆矩阵等)
- 论文撰写(LaTeX + PDF + DOCX)含摘要、引言、方法、结果、讨论、结论
- 数据审计(33 项验证)+ 文献审计
- 文献检索(PubMed + OpenAlex)
AI没做到什么
- 未还原原论文的预处理 pipeline:下采样+上采样组合、Robust Scaling、特征选择——这三个关键步骤的差异导致了性能差距。要真正复现原论文的性能,需要研究者手动指定这些预处理参数。
- 未实现 LIME 分析:原论文同时使用 LIME 和 SHAP 两种可解释性方法,AI 只做了 SHAP。
- 未做敏感性分析:未测试不同的不平衡处理策略(如原论文的下采样+上采样 vs SMOTE vs ADASYN)对模型性能的影响。
- 超参数优化不足:未进行网格搜索或贝叶斯优化。
结论
AI 在 73 分钟内完成了从数据到论文的完整流程,核心发现(Top 3 预测因子排序)与原论文一致。测试集性能差距(AUC 0.796 vs 0.97)主要来自预处理策略差异,而非模型能力不足(交叉验证 AUC 达 0.991)。这说明在卒中预测领域,数据预处理策略的选择对最终性能有决定性影响——这是研究者的专业判断,不是 AI 能自动决定的。