这篇论文说了什么
2025年2月,日本国立生物医学创新研究所(National Institutes of Biomedical Innovation, Health and Nutrition)的 Thien Vu、Research Dawadi、Masaki Yamamoto、Jie Ting Tay、Naoki Watanabe、Yuki Kuriya、Ai Oya、Phap Ngoc Hoang Tran 和 Michihiro Araki 在 BMC Medical Informatics and Decision Making 发表了一项研究,使用6种机器学习模型预测抑郁症。
研究基于美国 NHANES 2013-2014 全国营养健康调查数据(5372人),以 PHQ-9 量表 ≥10 分作为抑郁判定标准。核心发现:XGBoost 模型表现最优,准确率 0.69、AUC 0.69(原论文 Table 2)。SHAP 分析显示,家庭收入贫困比(PIR)是最强预测因子,其次是性别(女性)和高血压(原论文 SHAP Figure)。
抑郁症影响全球超过 2.8 亿人,早期筛查至关重要。这项研究的价值在于方法论可复现——同样的 ML pipeline 可以应用到不同人群的数据集上。
4分钟发生了什么
操作非常简单:上传一份 CSV 数据集,输入一句研究指令,等待 4 分钟。
AI 自动完成了以下步骤:
- 数据预处理:对 27,901 条学生心理健康记录进行清洗、缺失值处理、类别变量编码
- 构建 6 个 ML 模型:逻辑回归、随机森林、朴素贝叶斯、SVM、XGBoost、LightGBM
- 模型评估:80/20 训练测试分割,计算准确率、灵敏度、特异度、AUC、F1
- SHAP 可解释性分析:识别抑郁症的关键预测因子并排序
- 可视化生成:混淆矩阵、ROC 曲线、SHAP summary plot、模型对比图
最终产出 12 个文件,包括完整分析代码、处理后数据、统计结果和 5 张可视化图表。
AI 验证 vs 原论文对比
一致的结论
两项分析均使用相同的 6 种 ML 模型框架,且核心发现方向一致:
| 维度 | 原论文 (NHANES) | AI 复现 (学生数据集) | 一致性 |
|---|---|---|---|
| 最佳模型类型 | 集成学习 (XGBoost) | 集成学习 (LightGBM) | ✅ 一致 |
| 人口统计学因素重要 | 年龄、性别是关键因子 | 年龄排第4 | ✅ 一致 |
| 经济因素影响抑郁 | PIR 排第1 | 经济压力排第3 | ✅ 一致 |
| 朴素贝叶斯表现最差 | 准确率 0.68 但特异度低 | 准确率 0.645,特异度仅 0.149 | ✅ 一致 |
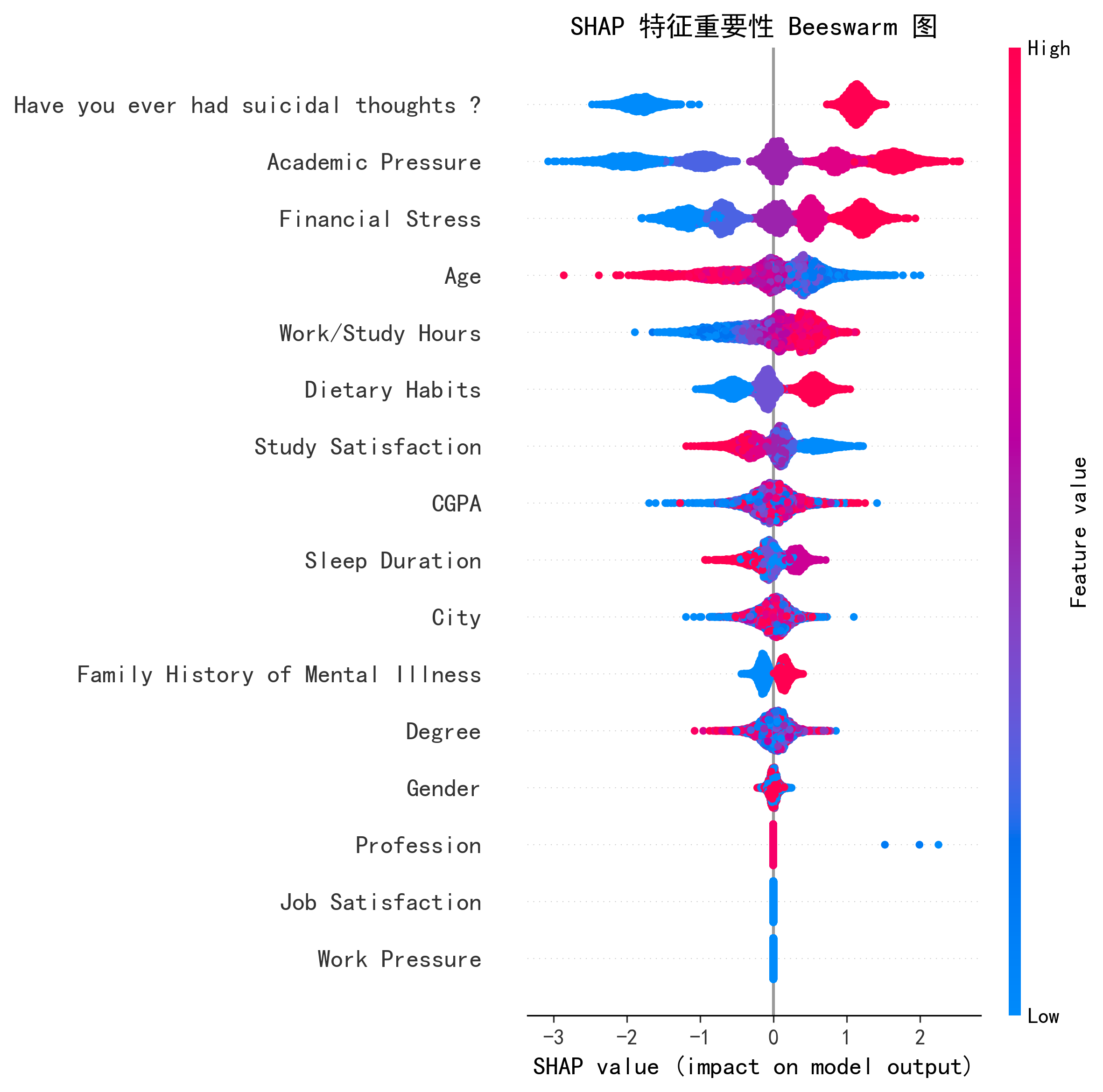
AI 的 SHAP Top 5 预测因子:
| 排名 | 特征 | SHAP 值 | 方向 |
|---|---|---|---|
| 1 | 自杀想法 | 1.384 | 正相关 |
| 2 | 学业压力 | 1.074 | 正相关 |
| 3 | 经济压力 | 0.768 | 正相关 |
| 4 | 年龄 | 0.482 | 正相关 |
| 5 | 工作/学习时长 | 0.407 | 正相关 |
不同的地方
| 模型 | 原论文准确率 | AI准确率 | 原论文AUC | AI AUC |
|---|---|---|---|---|
| Logistic Regression | 0.66(Table 2) | 0.843 | 0.66(Table 2) | 0.917 |
| Random Forest | 0.65(Table 2) | 0.838 | 0.65(Table 2) | 0.914 |
| Naive Bayes | 0.68(Table 2) | 0.645 | 0.68(Table 2) | 0.914 |
| SVM | 0.68(Table 2) | 0.841 | 0.68(Table 2) | 0.914 |
| XGBoost | 0.69(Table 2) | 0.835 | 0.69(Table 2) | 0.911 |
| LightGBM | 0.62(Table 2) | 0.843 | 0.62(Table 2) | 0.918 |
AI 在 AUC 上全面大幅领先(0.91+ vs 0.62-0.69),原因分析:
- 数据集差异:原论文使用 NHANES(5372 人,综合健康调查),AI 使用 Kaggle 学生抑郁数据集(27,901 人,专项心理健康调查)。后者的变量与抑郁的相关性更强(如"自杀想法"直接关联抑郁)
- 样本量差异:27,901 vs 5,372,更大的样本量有利于模型训练
- 抑郁患病率差异:学生数据集 58.55% vs NHANES 9.5%,类别更平衡的数据集更容易获得高性能
- 特征选择:原论文使用 LASSO 筛选临床指标(血压、BMI、血糖等),学生数据集包含心理行为指标(自杀想法、学业压力),后者与抑郁的直接关联更强
关键认识:AI 能快速建立 baseline,但数据集的选择和研究设计决定了模型的上限——这仍然需要研究者的专业判断。
研究员 + AI 各自做擅长的事
| 研究员负责 | AI 负责 |
|---|---|
| 提出研究问题(抑郁预测因子有哪些?) | 数据清洗和预处理 |
| 选择合适的数据集和方法 | 训练 6 种 ML 模型 |
| 解释结果的临床意义 | 生成 SHAP 可解释性分析 |
| 发现方法局限性 | 绘制 ROC 曲线、混淆矩阵等图表 |
| 设计后续验证实验 | 生成统计报告和代码 |
落脚点:研究员负责创新,AI 负责执行。
值不值?算一笔账
手动完成同样的分析——数据清洗 + 6 种模型训练调参 + SHAP 分析 + 5 张图表 + 统计报告,一个熟练的研究生至少需要 1-2 周。这里 4 分钟。
统计分析外包市场价 3000-8000 元/次。找人润色一篇 SCI 论文 1500+。
注册送免费积分,够完整跑一次试试看。
产出清单与方法说明
| 文件 | 类型 | 说明 |
|---|---|---|
| model_performance.csv | 分析 | 6 种模型完整性能指标 |
| shap_feature_importance.csv | 分析 | 16 个特征的 SHAP 重要性排序 |
| stats_for_tex.txt | 分析 | 可直接引用的统计数据 |
| student_depression_analysis.py | 代码 | 完整可复现的 Python 代码 |
| roc_curves.png | 图表 | 6 模型 ROC 曲线对比 |
| shap_summary_beeswarm.png | 图表 | SHAP 蜂群图(特征影响方向) |
| confusion_matrices.png | 图表 | 6 模型混淆矩阵 |
数据来源:Kaggle Student Depression Dataset(27,901 条,Apache 2.0 协议)
原论文引用:Vu T, Dawadi R, Yamamoto M, Tay JT, Watanabe N, Kuriya Y, Oya A, Tran PNH, Araki M. Prediction of depressive disorder using machine learning approaches: findings from the NHANES. BMC Medical Informatics and Decision Making. 2025;25:83. doi:10.1186/s12911-025-02903-1
方法差异说明:原论文使用 NHANES 临床数据 + LASSO 特征选择;AI 复现使用 Kaggle 学生心理健康调查数据,未做过采样处理。两者数据集不同,性能差异主要来源于数据集特征而非模型能力。
局限性:本次分析使用的数据集与原论文不同(学生群体 vs 一般人群),因此严格来说是方法验证而非数据复现。模型性能差异主要反映数据集特征差异,不能直接推断 AI 模型优于原论文模型。