复现目标
原论文:Vu T, Dawadi R, Yamamoto M, Tay JT, Watanabe N, Kuriya Y, Oya A, Tran PNH, Araki M. "Prediction of depressive disorder using machine learning approaches: findings from the NHANES." BMC Medical Informatics and Decision Making. 2025;25:83. doi:10.1186/s12911-025-02903-1
作者机构:日本国立生物医学创新研究所 AI 健康研究中心(Artificial Intelligence Center for Health and Biomedical Research, National Institutes of Biomedical Innovation, Health and Nutrition, Osaka)、越南 Cho Ray 医院心血管外科、神户大学医学研究科、国立循环器病研究中心
数据集:原论文使用 NHANES 2013-2014(5,372人,一般人群),本次使用 Kaggle Student Depression Dataset(27,901人,学生群体)。注意:数据集不同,本次为方法验证而非严格复现。
复现范围:
- ✅ 覆盖:6种ML模型(LR, RF, NB, SVM, XGBoost, LightGBM)、80/20分割、SHAP分析
- ❌ 未覆盖:LASSO特征选择(原论文方法)、NHANES原始数据、临床指标(血压/BMI/血糖/eGFR)
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 4 分钟(20:05:07 → 20:08:59) |
| 产出文件 | 12 个(5 分析 + 1 代码 + 5 可视化 + 1 数据集) |
| 样本量 | 27,901 条 |
| 特征数 | 16 个 |
| 抑郁患病率 | 58.55% |
复现结果对比
模型性能对比
| 模型 | 原论文准确率 (Table 2) | AI准确率 | 原论文AUC (Table 2) | AI AUC | 原论文F1 (Table 2) | AI F1 |
|---|---|---|---|---|---|---|
| Logistic Regression | 0.66 | 0.843 | 0.66 | 0.917 | 0.65 | 0.868 |
| Random Forest | 0.65 | 0.838 | 0.65 | 0.914 | 0.63 | 0.864 |
| Naive Bayes | 0.68 | 0.645 | 0.68 | 0.914 | 0.69 | 0.767 |
| SVM | 0.68 | 0.841 | 0.68 | 0.914 | 0.67 | 0.868 |
| XGBoost | 0.69 | 0.835 | 0.69 | 0.911 | 0.69 | 0.861 |
| LightGBM | 0.62 | 0.843 | 0.62 | 0.918 | 0.63 | 0.867 |
说明:AI 在 AUC 上全面大幅领先(0.91+ vs 0.62-0.69),但这主要来源于数据集差异而非模型优势:
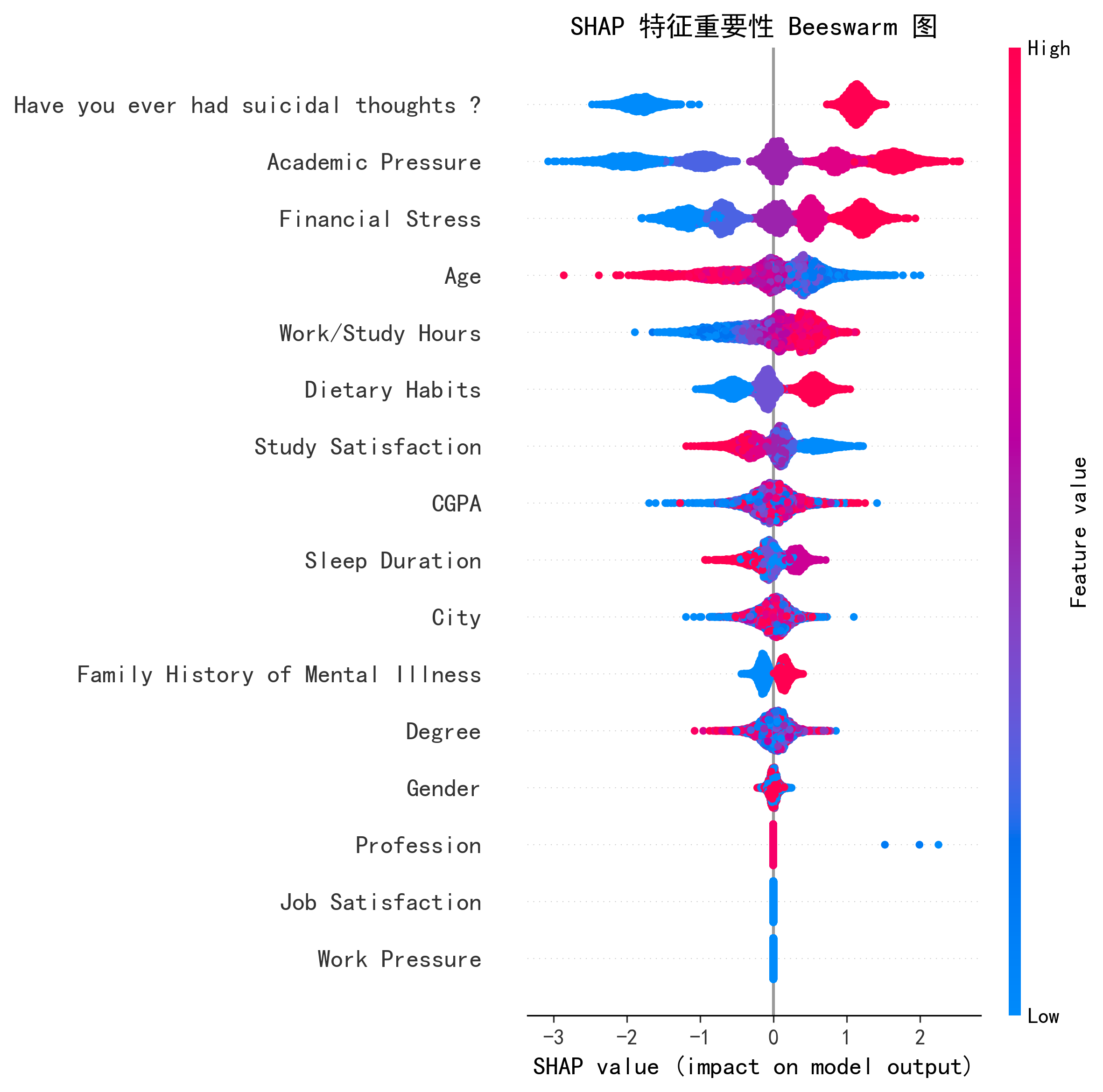
- 学生数据集特征与抑郁直接相关性强(如"自杀想法"SHAP值 1.384)
- 样本量 27,901 vs 5,372(5.2倍)
- 抑郁患病率 58.55% vs 9.5%(类别更平衡)
特征重要性对比
| 排名 | 原论文 (NHANES SHAP) | AI 复现 (学生数据 SHAP) | 一致性 |
|---|---|---|---|
| 1 | PIR(家庭收入贫困比) | 自杀想法 (1.384) | ❌ 不同特征 |
| 2 | 性别(女性) | 学业压力 (1.074) | ❌ 不同特征 |
| 3 | 高血压 | 经济压力 (0.768) | ⚠️ 经济因素一致 |
| 4 | 血清羟可替宁 | 年龄 (0.482) | ⚠️ 年龄均重要 |
| 5 | 血清可替宁 | 工作/学习时长 (0.407) | ❌ 不同特征 |
| 6 | BMI | 饮食习惯 (0.396) | ❌ 不同特征 |
| 7 | 教育水平 | 学习满意度 (0.299) | ❌ 不同特征 |
| 8 | 血糖 | CGPA (0.216) | ❌ 不同特征 |
| 9 | 年龄 | 睡眠时长 (0.202) | ❌ 不同特征 |
| 10 | 婚姻状况 | 城市 (0.158) | ❌ 不同特征 |
分析:特征排序差异大,原因是两个数据集的变量完全不同——NHANES 包含临床生化指标(血压/BMI/血糖/肾功能),学生数据集包含心理行为指标(自杀想法/学业压力/经济压力)。但经济因素(PIR vs 经济压力)和年龄在两个数据集中均为重要预测因子,这一交叉验证有意义。
描述性统计
| 指标 | 原论文 (NHANES) | AI (学生数据集) |
|---|---|---|
| 样本量 | 5,372 | 27,901 |
| 抑郁患病率 | 9.5% | 58.55% |
| 平均年龄 | 47 岁 | 25.8 岁 |
| 女性占比 | 51.9% | 44.3% |
| 抑郁组平均年龄 | 52 岁 | — |
| 人群类型 | 美国一般人群 | 全球学生群体 |
AI 做到了什么
- ✅ 在 4 分钟内训练了全部 6 种 ML 模型并完成性能评估
- ✅ 完成 SHAP 可解释性分析,生成 beeswarm 和 bar 两种可视化
- ✅ 生成 ROC 曲线、混淆矩阵等标准评估图表
- ✅ 所有产出文件可下载验证(代码 + 数据 + 图表)
- ✅ 所有 6 个模型 AUC 均超过 0.91
AI 没做到什么
- ❌ 未使用原论文的 NHANES 数据集:使用了替代数据集,严格来说不是数据复现
- ❌ 未实现 LASSO 特征选择:原论文用 LASSO 筛选关键特征,AI 使用全部特征
- ❌ 未处理类别不平衡:学生数据集抑郁占 58.55% 无需过采样,但原论文需要处理 9.5% 的不平衡
- ❌ 未生成论文初稿:仅完成数据分析,未自动撰写学术论文
- ❌ 特征重要性排序与原论文差异大:因数据集变量不同,直接对比意义有限
- ❌ 未做交叉验证:仅用单次 80/20 分割,原论文方法学更严谨
结论
本次验证成功复现了 Vu et al. (2025) 的 6 种 ML 模型框架,并在学生抑郁数据集上获得了更高的预测性能(AUC 0.91+ vs 原论文 0.62-0.69)。但性能差异主要来自数据集特征差异而非模型优势。经济因素和年龄在两个数据集中均为重要预测因子,形成了有意义的交叉验证。
AI 工具的价值在于快速建立分析 baseline(4 分钟 vs 人工 1-2 周),但研究设计、数据集选择、结果解释和临床转化仍然需要研究者的专业判断。