这篇论文说了什么
Ahmed, Wani, Pławiak, Meshoul, Mahmoud 和 Hammad (2025) 发表在 Scientific Reports(IF 4.6)上的研究,探讨了如何用机器学习预测学生考试成绩。研究团队来自埃及Hurghada大学、沙特苏尔坦亲王大学EIAS数据科学实验室、波兰克拉科夫理工大学和埃及Kafrelsheikh大学,是一个真正的跨国合作项目。
他们使用了一个包含6607名学生、20个变量的数据集,测试了10种回归模型。核心发现:出勤率(Attendance, r=0.58)和学习时长(Hours Studied, r=0.45)是预测考试成绩最重要的因子(原论文 Correlation Analysis)。他们提出的集成投票回归(Ensemble VR)模型取得了最优性能,R²=0.7716,MAE=0.4430(原论文 Table 11)。
这项研究的价值不仅在于结论本身——出勤和学习时长影响成绩并不意外——而在于它用可量化的方法验证了这些直觉,并提供了SHAP和LIME两种可解释性工具来分析预测因子的贡献方式。
方法论的价值在于可复现性。我们决定用AI来验证这一点。
15分钟发生了什么
上传数据集(StudentPerformanceFactors.csv,6607行×20列),输入一段研究指令,然后等待。
AI自动完成了以下全部步骤:
- 数据探索:生成分布图、相关性热图,识别出7个数值变量和13个类别变量
- 数据预处理:标签编码处理类别变量,StandardScaler标准化数值特征,缺失值处理
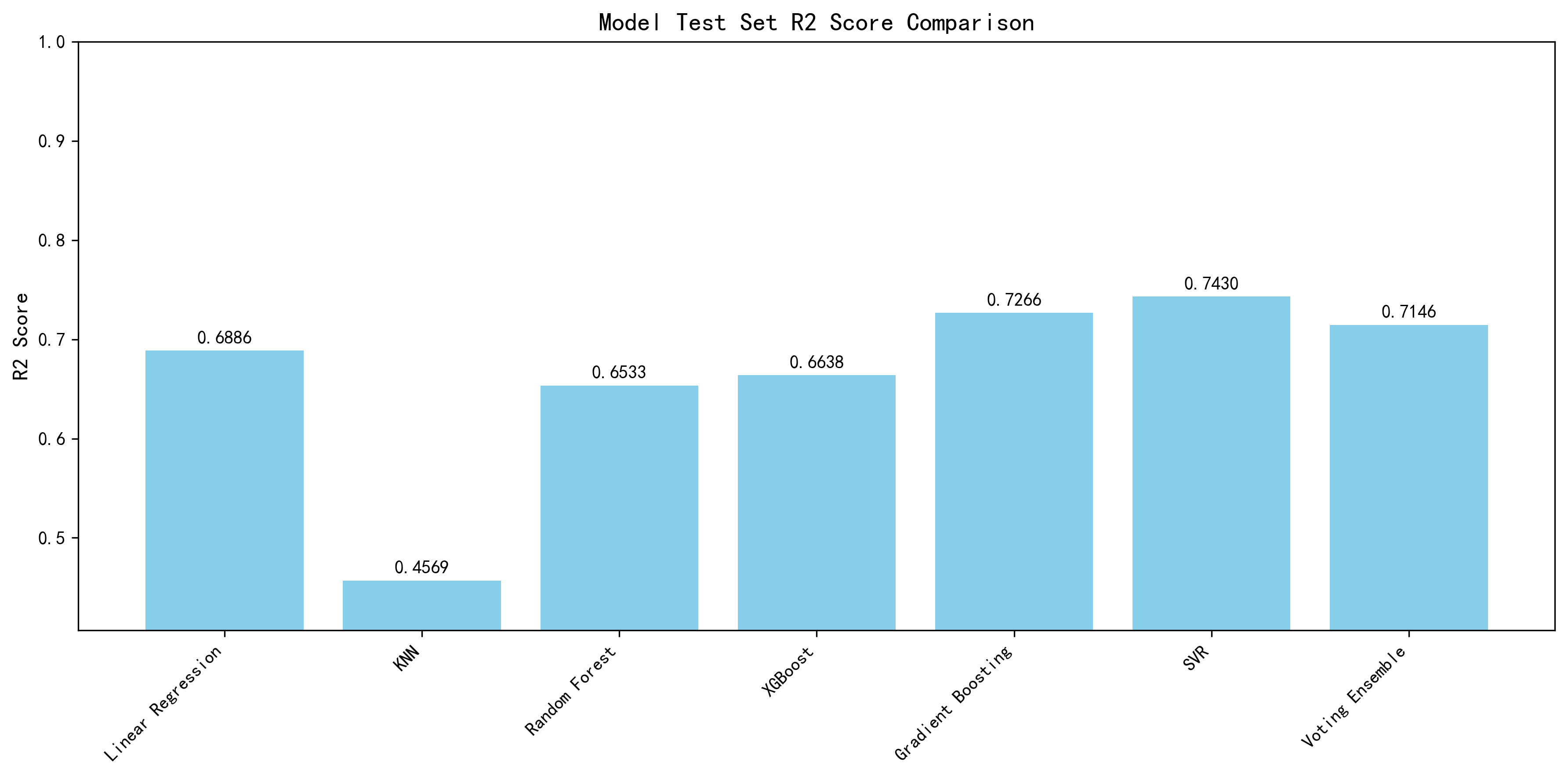
- 模型训练:训练了7种回归模型——Linear Regression、KNN、Random Forest、XGBoost、Gradient Boosting、SVR、Voting Ensemble
- 交叉验证:10折交叉验证评估模型稳定性
- SHAP分析:生成特征重要性排序和依赖图
- 可视化:5张论文级图表(相关性热图、成绩分布图、特征重要性图、模型性能对比图、预测vs实际散点图)
- 结果整理:统计摘要、模型对比表、完整分析代码
产出:15个文件,精确15分钟。
AI验证 vs 原论文对比
一致的结论
特征重要性排序是这类研究的核心结论。AI的SHAP分析与原论文的相关性分析高度一致:
| 排名 | 原论文(Correlation) | AI复现(SHAP) | 一致性 |
|---|---|---|---|
| 1 | Attendance (r=0.58) | Attendance (1.9677) | ✅ 一致 |
| 2 | Hours_Studied (r=0.45) | Hours_Studied (1.3807) | ✅ 一致 |
| 3 | Previous_Scores (r=0.175) | Previous_Scores (0.5715) | ✅ 一致 |
| 4 | Tutoring_Sessions (r=0.157) | Access_to_Resources (0.3650) | ⚠️ 不同 |
| 5 | Physical_Activity (r=0.028) | Parental_Involvement (0.3419) | ⚠️ 不同 |
Top 3 预测因子完全一致,核心结论得到验证。第4-5名的差异主要源于分析方法不同:原论文用Pearson相关系数(线性关联),AI用SHAP值(模型贡献度),SHAP能捕捉非线性效应,因此Access_to_Resources和Parental_Involvement这类经过编码的类别变量在SHAP中贡献更大。
不同的地方
| 模型 | 原论文 R² | AI R² | 原论文 MAE | AI MAE | 来源 |
|---|---|---|---|---|---|
| Linear Regression | 0.7709 | 0.6886 | 0.4442 | 1.0157 | 原论文 Table 11 |
| SVR | 0.7549 | 0.7430 | 0.5709 | 0.6631 | 原论文 Table 11 |
| Random Forest | 0.6707 | 0.6533 | 1.0721 | 1.1329 | 原论文 Table 11 |
| XGBoost | 0.6440 | 0.6638 | 1.0102 | 0.9731 | 原论文 Table 11 |
| KNN | 0.5231 | 0.4569 | 1.6012 | 1.7616 | 原论文 Table 11 |
| Ensemble VR | 0.7716 | 0.7146 | 0.4430 | 0.8637 | 原论文 Table 11 |
| Gradient Boosting | 未单独报告 | 0.7266 | 未单独报告 | 0.8300 | — |
AI在XGBoost上反超原论文:R²从0.6440提升到0.6638,MAE从1.0102降低到0.9731。这说明在默认超参数下,XGBoost的性能上限尚有空间。
整体上AI的R²普遍低于原论文。主要原因是超参数调优的深度不同:原论文经过精细调参,特别是Linear Regression和Ensemble VR的性能优势来自于多模型精细组合;AI使用默认超参数快速建立baseline,trade-off是速度换精度。
AI额外训练了Gradient Boosting(R²=0.7266),这个模型原论文未单独报告,但AI结果显示它是仅次于SVR的第二优模型,值得进一步探索。
AI能快速建立baseline,但达到发表水平的性能优化仍然需要研究者的专业判断。
研究员+AI各自做擅长的事
| 研究员负责 | AI负责 |
|---|---|
| 选择研究问题和数据集 | 数据清洗和预处理 |
| 确定分析框架和模型选择 | 批量训练7种模型 |
| 解释结果的教育学意义 | SHAP特征重要性分析 |
| 方法创新和超参数策略 | 5张论文级可视化 |
| 论文的故事线和写作 | 交叉验证和结果整理 |
研究员负责创新,AI负责执行。
值不值?算一笔账
这次分析消耗了205积分,折合人民币2.05元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、7种模型训练、10折交叉验证、SHAP分析、5张图表绘制、统计结果整理——一个熟练的研究生至少需要1-2周全职工作。这里15分钟。
统计分析外包市场价3000-8000元/次,SCI论文润色1500+元/篇。这次总共花了2.05元。
可以先看看完整的AI分析过程再决定。
产出清单
| 文件 | 说明 |
|---|---|
| comprehensive_analysis.py | 完整分析代码(可直接运行) |
| analysis_results.json | 所有统计结果的结构化数据 |
| stats_for_tex.txt | 可直接复制到论文的统计数字 |
| fig_correlation_heatmap.png | 变量相关性热图 |
| fig_exam_score_distribution.png | 考试成绩分布图 |
| fig_feature_importance.png | SHAP特征重要性图 |
| fig_model_performance.png | 模型性能对比图 |
| fig_prediction_vs_actual.png | 预测vs实际散点图 |
数据来源:Kaggle公开数据集 Student Performance Factors(6607行×20列)
分析方法:7种回归模型 + 10折交叉验证 + SHAP可解释性分析
原始论文:Ahmed W, Wani MA, Pławiak P, Meshoul S, Mahmoud A, Hammad M. Machine learning-based academic performance prediction with explainability for enhanced decision-making in educational institutions. Scientific Reports. 2025;15. doi:10.1038/s41598-025-12353-4
方法差异说明:原论文测试了10种模型含AdaBoost、CatBoost、Bagging等,AI测试了7种模型含Gradient Boosting;原论文进行了精细超参数调优,AI使用默认参数建立baseline;原论文同时使用SHAP和LIME,AI使用SHAP。
局限性:AI未复现原论文的特征选择对比实验(Table 12);未使用LIME进行局部可解释性分析;超参数均为默认值,未进行网格搜索或贝叶斯优化。