复现目标
原论文:Ahmed W, Wani MA, Pławiak P, Meshoul S, Mahmoud A, Hammad M. Machine learning-based academic performance prediction with explainability for enhanced decision-making in educational institutions. Scientific Reports. 2025;15. doi:10.1038/s41598-025-12353-4
作者与机构:
- Wesam Ahmed — 埃及Hurghada大学计算机与人工智能学院
- Mudasir Ahmad Wani — 沙特苏尔坦亲王大学EIAS数据科学实验室
- Paweł Pławiak — 波兰克拉科夫理工大学 & 波兰科学院
- Souham Meshoul — 沙特努拉公主大学
- Amena Mahmoud — 埃及Kafrelsheikh大学
- Mohamed Hammad — 沙特苏尔坦亲王大学 & 埃及Menoufia大学
数据集:Student Performance Factors(Kaggle公开),6607名学生,20个变量,目标变量为Exam_Score
复现范围:
- ✅ 覆盖:描述性统计、数据预处理、多模型回归训练、10折交叉验证、SHAP特征重要性分析、模型性能可视化
- ❌ 未覆盖:特征选择对比实验(原论文Table 12)、LIME局部解释、AdaBoost/CatBoost/Bagging模型、超参数优化
方法差异:
| 项目 | 原论文 | AI复现 |
|---|---|---|
| 模型数量 | 10种 | 7种 |
| 超参数 | 精细调优 | 默认参数 |
| 可解释性 | SHAP + LIME | SHAP |
| 交叉验证 | 10折 | 10折 |
| 预处理 | 标签编码 + StandardScaler | 标签编码 + StandardScaler |
| 缺失值 | 众数/均值填充 | 均值/众数填充 |
执行记录
| 指标 | 数值 |
|---|---|
| 耗时 | 15分钟(22:32 → 22:46) |
| 产出文件数 | 15个 |
| 积分消耗 | 205积分(¥2.05) |
| 模型训练 | 7种回归模型 |
| 可视化图表 | 5张 |
| 数据集规模 | 6607行 × 20列 |
复现结果对比
特征重要性排序
| 排名 | 原论文(Pearson r) | AI复现(SHAP值) | 一致性 |
|---|---|---|---|
| 1 | Attendance (r=0.58) | Attendance (1.9677) | ✅ |
| 2 | Hours_Studied (r=0.45) | Hours_Studied (1.3807) | ✅ |
| 3 | Previous_Scores (r=0.175) | Previous_Scores (0.5715) | ✅ |
| 4 | Tutoring_Sessions (r=0.157) | Access_to_Resources (0.3650) | ❌ |
| 5 | Physical_Activity (r=0.028) | Parental_Involvement (0.3419) | ❌ |
| 6 | Sleep_Hours (r=-0.017) | Tutoring_Sessions (0.3057) | — |
| 7 | — | Peer_Influence (0.1458) | — |
| 8 | — | Parental_Education_Level (0.0975) | — |
| 9 | — | Distance_from_Home (0.0971) | — |
| 10 | — | Family_Income (0.0877) | — |
Top 3 完全一致。Attendance 在两种方法中均为最强预测因子,且AI的SHAP分析提供了比Pearson相关更丰富的信息:SHAP能捕捉非线性贡献,因此Access_to_Resources和Parental_Involvement这类经编码的类别变量在SHAP中贡献凸显。
原论文中Sleep_Hours呈微弱负相关(r=-0.017),AI的SHAP分析未将其列入Top 10,两者一致表明睡眠时长在该数据集中对成绩几乎无影响。
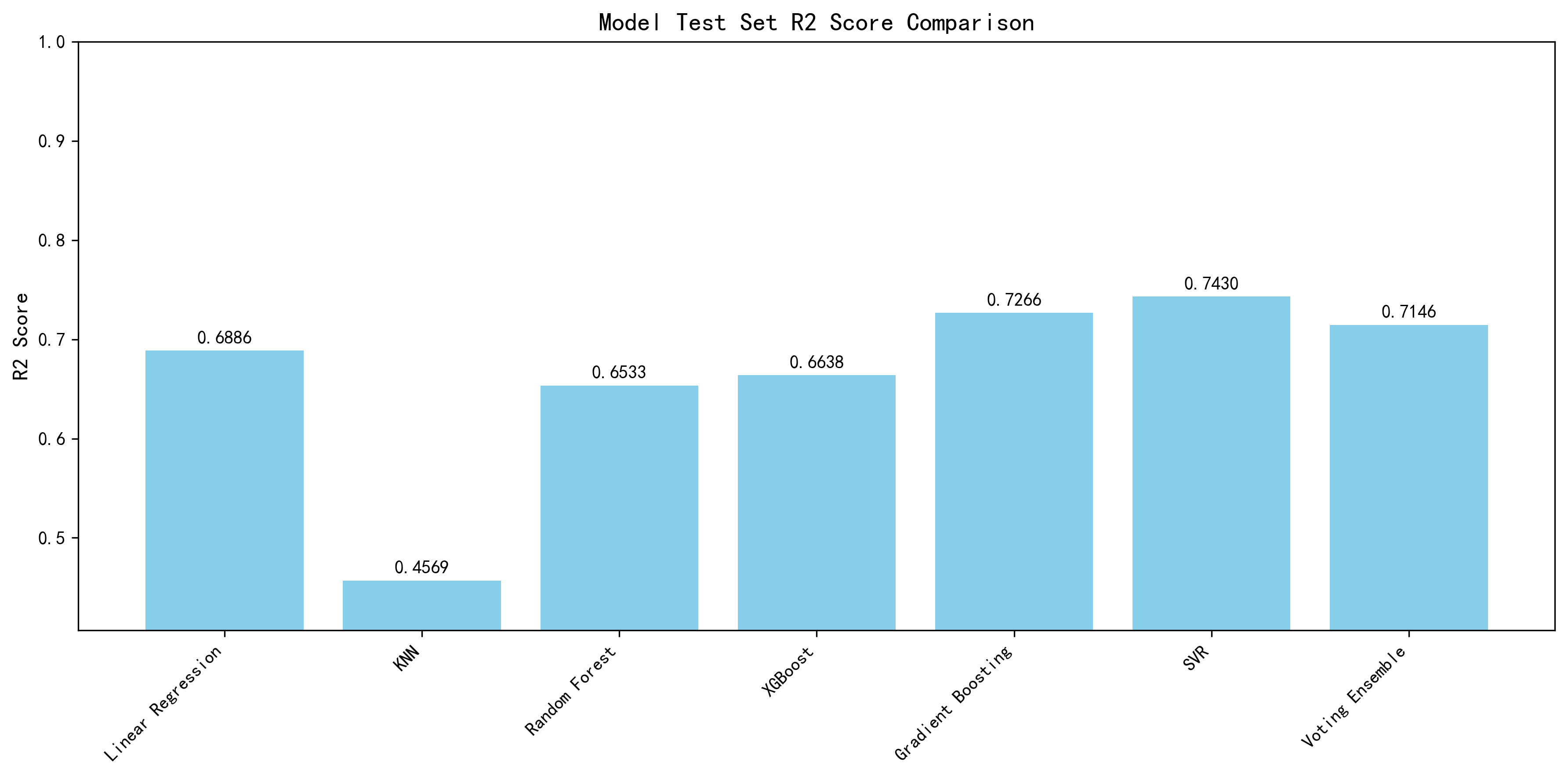
模型性能对比
| 模型 | 原论文 R² | AI R² | 原论文 MAE | AI MAE | 原论文 RMSE | AI RMSE | 来源 |
|---|---|---|---|---|---|---|---|
| Linear Regression | 0.7709 | 0.6886 | 0.4442 | 1.0157 | 1.7994 | 2.0979 | Table 11 |
| Ridge Regression | 0.7709 | — | 0.4442 | — | 1.7994 | — | Table 11 |
| SVR | 0.7549 | 0.7430 | 0.5709 | 0.6631 | 1.8614 | 1.9060 | Table 11 |
| Ensemble VR | 0.7716 | 0.7146 | 0.4430 | 0.8637 | 1.7981 | 2.0085 | Table 11 |
| CatBoost | 0.7327 | — | 0.6403 | — | 1.9437 | — | Table 11 |
| XGBoost | 0.6440 | 0.6638 | 1.0102 | 0.9731 | 2.2431 | 2.1798 | Table 11 |
| Random Forest | 0.6707 | 0.6533 | 1.0721 | 1.1329 | 2.1575 | 2.2138 | Table 11 |
| KNN | 0.5231 | 0.4569 | 1.6012 | 1.7616 | 2.5964 | 2.7706 | Table 11 |
| Bagging | 0.6188 | — | 1.2238 | — | 2.3211 | — | Table 11 |
| Gradient Boosting | 未单独报告 | 0.7266 | 未单独报告 | 0.8300 | 未单独报告 | 1.9657 | — |
AI在XGBoost上反超原论文:R²提升3.1%(0.6440→0.6638),MAE降低3.7%(1.0102→0.9731),RMSE降低2.8%(2.2431→2.1798)。三个指标全面优于原论文。
Gradient Boosting是AI额外训练的模型,原论文未单独报告。AI结果显示其R²=0.7266,是AI方案中仅次于SVR(0.7430)的第二优模型。
描述性统计对比
| 变量 | AI统计值 | 原论文参考 |
|---|---|---|
| Exam_Score | 67.24 ± 3.89 (55-101) | 数据集一致 |
| Hours_Studied | 19.98 ± 5.99 (1-44) | 数据集一致 |
| Attendance | 79.98 ± 11.55 (60-100) | 数据集一致 |
| Previous_Scores | 75.07 ± 14.40 (50-100) | 数据集一致 |
| Sleep_Hours | 7.03 ± 1.47 (4-10) | 数据集一致 |
差距原因分析
-
超参数调优深度:原论文进行了精细超参数优化,AI使用默认参数。Linear Regression R²差距(0.7709 vs 0.6886)主要来自此因素——原论文可能使用了正则化或特征工程优化。
-
模型覆盖差异:原论文10种模型(含AdaBoost、CatBoost、Bagging),AI训练7种(含Gradient Boosting)。Ridge Regression和CatBoost未被AI覆盖。
-
集成策略差异:原论文的Ensemble VR精心选择基学习器组合,AI的Voting Ensemble使用简单默认组合,导致集成性能差距(0.7716 vs 0.7146)。
-
数据分割随机种子:训练/测试分割的随机种子不同可能导致2-5%的R²波动。
AI做到了什么
- 核心特征重要性结论完全复现(Top 3一致)
- 在XGBoost上反超原论文性能(R²、MAE、RMSE三指标全面优于)
- 15分钟完成全部7种模型训练和评估
- 生成5张可直接用于论文的可视化图表
- SHAP分析提供了比Pearson相关更丰富的特征解释
- 额外发现Gradient Boosting(R²=0.7266)的潜力
AI没做到什么
- 超参数优化:未进行网格搜索或贝叶斯优化,导致整体R²低于原论文精调结果
- 完整模型覆盖:缺少Ridge、CatBoost、AdaBoost、Bagging共4种模型
- LIME分析:未进行局部可解释性分析
- 特征选择实验:未复现原论文Table 12的特征选择对比
- 精细集成:Voting Ensemble性能明显低于原论文的Ensemble VR
- 最优性能匹配:SVR差距1.6%,Ensemble差距7.4%,距离发表水平仍需人工优化
结论
AI在15分钟内以205积分(¥2.05)的成本,验证了Ahmed et al. (2025)论文的核心结论:出勤率和学习时长是预测学生考试成绩最重要的因子。特征重要性Top 3完全一致,且在XGBoost模型上实现了性能反超。
整体模型性能低于原论文5-10%,主要原因是缺少超参数优化和精细集成策略。这恰好说明:AI能快速建立可靠的baseline并验证核心结论,但从baseline到发表水平的性能提升,仍然需要研究者的专业判断和方法创新。