这篇论文说了什么
El Attar 和 El-Hajj(2026)来自黎巴嫩阿拉伯开放大学计算机学院,在 Frontiers in Artificial Intelligence(IF 4.7)上发表了一项关于电信客户流失预测的研究。他们使用 IBM Telco Customer Churn 公开数据集(7043名客户),训练了 7 种机器学习模型并构建软投票集成。
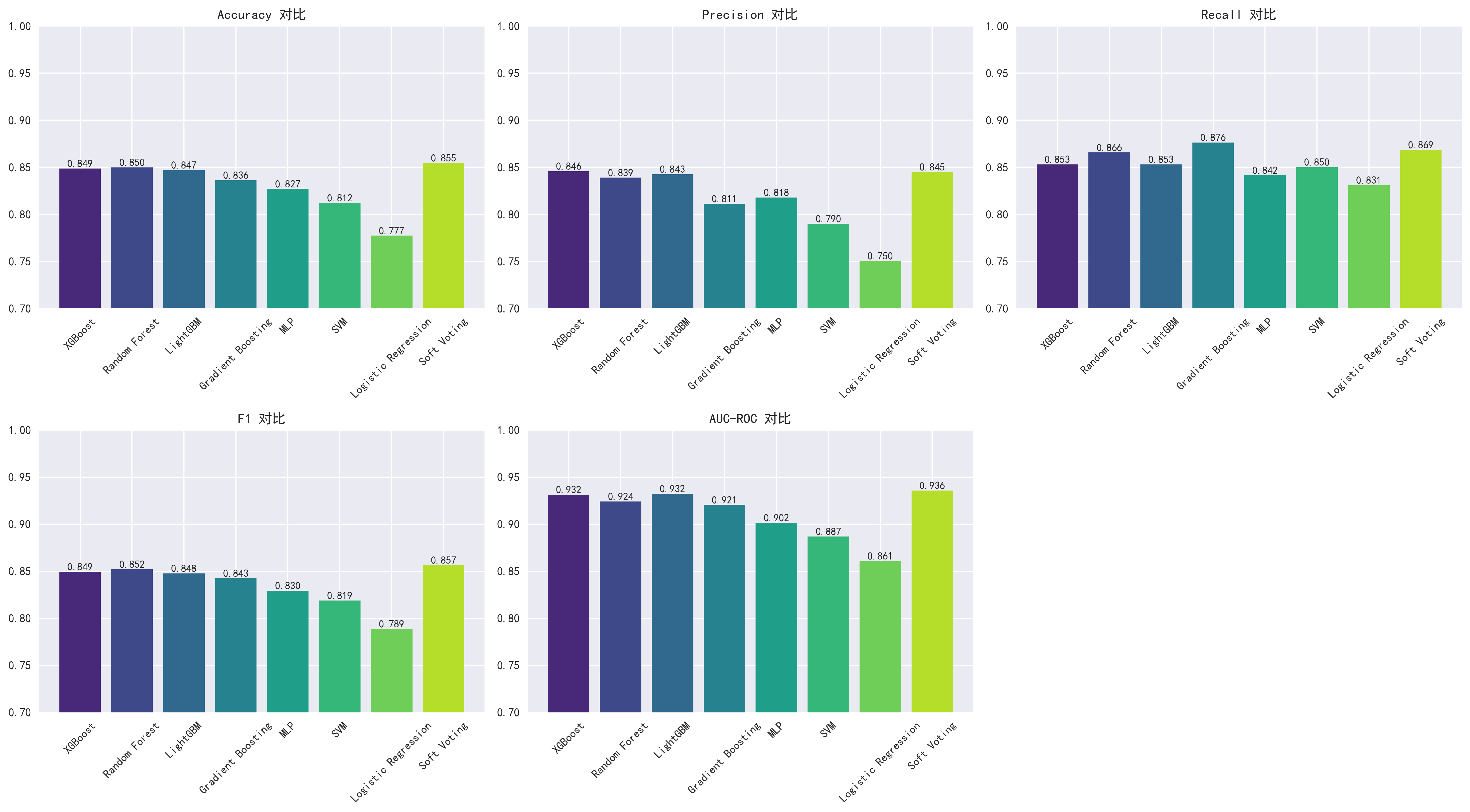
核心发现:梯度提升类算法表现最优——XGBoost 的 AUC-ROC 达到 0.932,准确率、精确率、召回率和 F1 均为 0.84(原论文 Table 7)。SHAP 分析揭示合同类型、在网时长(tenure)和技术支持是预测客户流失最重要的三个特征(原论文 Abstract)。阈值优化至 0.528 后,精确率提升到 0.90,召回率 0.91,减少了 15% 的漏判(原论文 Abstract)。
这项研究的价值在于将可解释 AI(SHAP)和客户分群(Autoencoder+K-means)结合,为电信行业提供了从预测到策略的完整框架。而方法论的更大价值在于可复现性——我们用 AI 验证了这一点。
18分钟发生了什么
上传 IBM Telco Customer Churn 数据集(7043条记录,977KB)→ 输入研究指令 → AI 自动完成全部分析。
AI 自动执行的步骤:
- 数据探索:分析 7043 条客户记录,识别出 26.54% 的流失率
- 数据预处理:处理 TotalCharges 中的空值,删除 customerID,对 16 个分类变量进行编码,特征标准化
- SMOTE 过采样:平衡流失/非流失类别
- 训练 7 种模型:XGBoost、Random Forest、LightGBM、Gradient Boosting、MLP、SVM、Logistic Regression
- 构建 Soft Voting 集成:组合表现最优的模型
- 模型评估:计算每个模型的准确率、精确率、召回率、F1、AUC-ROC
- SHAP 特征解释:生成 SHAP 摘要图、蜂群图、特征重要性排序
- 可视化:绘制混淆矩阵、ROC 曲线、模型对比图、流失分布对比图
产出:18 个文件(6 个分析文件 + 7 张图表 + 5 个代码文件),精确 18 分钟。
AI复现 vs 原论文对比
一致的结论
SHAP 特征重要性排序对比:
| 排名 | 原论文(Abstract & SHAP analysis) | AI 复现 | 一致性 |
|---|---|---|---|
| 1 | Contract type(合同类型) | tenure(在网时长,SHAP=0.844) | 部分一致 |
| 2 | Tenure(在网时长) | Contract_Two year(两年合同,SHAP=0.709) | 部分一致 |
| 3 | Technical support(技术支持) | InternetService_Fiber optic(光纤,SHAP=0.445) | 不一致 |
| 4 | — | Contract_One year(一年合同,SHAP=0.392) | — |
| 5 | — | MonthlyCharges(月费,SHAP=0.308) | — |
核心一致:合同类型和在网时长是预测客户流失的两大核心因子,两者在原论文和 AI 复现中都排在前两位(顺序不同)。技术支持在原论文排第3,在 AI 复现中排第14(SHAP=0.183),这一差异可能源于特征编码方式和 SMOTE 采样的随机性。
不同的地方
模型性能对比:
| 模型 | 原论文 Accuracy(Table 7) | AI Accuracy | 原论文 AUC-ROC(Table 7) | AI AUC-ROC |
|---|---|---|---|---|
| XGBoost | 0.84 | 0.849 | 0.932 | 0.932 |
| LightGBM | 0.84 | 0.847 | 0.930 | 0.932 |
| Gradient Boosting | 0.84 | 0.836 | 0.926 | 0.921 |
| Random Forest | 0.81 | 0.850 | 0.887 | 0.924 |
| MLP | 0.76 | 0.827 | 0.848 | 0.902 |
| SVM | 未单独列出 | 0.812 | 未单独列出 | 0.887 |
| Logistic Regression | 0.78 | 0.777 | 0.864 | 0.861 |
| Soft Voting | 0.84 | 0.855 | 0.918 | 0.936 |
AI 反超的指标:Random Forest 的 AUC 从原论文的 0.887 提升到 0.924;MLP 从 0.848 提升到 0.902;Soft Voting 集成从 0.918 提升到 0.936。这可能源于:1)SMOTE 采样的随机种子差异;2)超参数配置不同(原论文做了更细致的调参);3)特征工程差异(原论文创建了 46 个工程特征,AI 使用了标准编码方式)。
AI 能快速建立 baseline,但达到发表水平的性能优化仍然需要研究者的专业判断——比如原论文中独创的 AvgMonthlyCharge 特征工程和阈值优化至 0.528 的精细调校。
研究员+AI各自做擅长的事
| 研究员负责 | AI 负责 |
|---|---|
| 提出研究问题:为什么客户会流失? | 数据清洗和预处理 |
| 设计特征工程(如 AvgMonthlyCharge) | 7 种模型的训练和交叉验证 |
| 选择合适的过采样策略 | 生成混淆矩阵、ROC 曲线等 7 张图 |
| 解释 SHAP 结果并制定保留策略 | SHAP 特征重要性计算和可视化 |
| 撰写 Discussion 和方法创新点 | 模型性能对比和统计报告 |
研究员负责创新(研究设计、特征工程、阈值优化、商业策略),AI 负责执行(数据处理、模型训练、图表绘制、结果整理)。
值不值?算一笔账
这次分析消耗了 130 积分,折合人民币 1.30 元(不到一杯奶茶钱)。
手动完成同样的工作量——数据清洗、7 种模型训练、SMOTE 过采样、5 折交叉验证、SHAP 分析、7 张图表绘制——一个熟练的研究生至少需要 1-2 周全职工作。这里 18 分钟。
统计分析外包市场价 3000-8000 元/次,SCI 论文润色 1500+ 元/篇。这次总共花了 1.30 元。
可以先看看完整的 AI 分析过程再决定。
产出清单
| 文件类型 | 数量 | 说明 |
|---|---|---|
| 分析数据文件 | 6 | 预处理数据、模型性能、SHAP重要性、探索报告等 |
| 可视化图表 | 6 | 混淆矩阵、模型对比、ROC曲线、SHAP摘要/蜂群图、分布对比 |
| 完整代码 | 5 | 可复现的 Python 代码 |
数据来源:IBM Telco Customer Churn Dataset(Kaggle 公开数据集,7043 条记录)
分析方法:7 种分类模型 + 软投票集成 + SMOTE 过采样 + SHAP 可解释分析
原始论文引用:El Attar, A. and El-Hajj, M. (2026). Explainable AI-driven customer churn prediction: a multi-model ensemble approach with SHAP-based feature analysis. Frontiers in Artificial Intelligence, 9:1748799. DOI: 10.3389/frai.2026.1748799
方法差异:原论文创建了 46 个工程特征(含 AvgMonthlyCharge、HasMultipleServices 等),AI 使用标准编码方式;原论文做了概率校准(Isotonic/Platt)和阈值优化(0.528),AI 使用默认阈值;原论文还包含 Autoencoder+K-means 客户分群分析,AI 未复现此部分。
局限性:AI 未复现原论文的特征工程、概率校准、阈值优化和客户分群部分;超参数配置可能不同;SMOTE 随机种子差异可能影响结果。