复现目标
原论文:El Attar, A. and El-Hajj, M. (2026). Explainable AI-driven customer churn prediction: a multi-model ensemble approach with SHAP-based feature analysis. Frontiers in Artificial Intelligence, 9:1748799. DOI: 10.3389/frai.2026.1748799
作者机构:Ali El Attar, Mohammed El-Hajj — Faculty of Computer Studies (FCS), Arab Open University (AOU), Beirut, Lebanon
数据集:IBM Telco Customer Churn Dataset(Kaggle 公开数据集),7043 条客户记录,21 个原始特征,目标变量为客户是否流失(Churn)。
复现范围:
| 覆盖 | 未覆盖 |
|---|---|
| 7 种 ML 模型训练与评估 | 特征工程(原论文 46 个工程特征) |
| SMOTE 过采样 | 概率校准(Platt/Isotonic) |
| Soft Voting 集成 | 阈值优化(0.528) |
| SHAP 特征重要性分析 | Autoencoder + K-means 客户分群 |
| 混淆矩阵 + ROC 曲线 | 客户风险画像分层 |
| 5 折交叉验证 | DNN 架构优化 |
方法差异:
- 特征工程:原论文创建 AvgMonthlyCharge、HasMultipleServices 等复合特征(共 46 维),AI 使用标准 one-hot/label 编码
- 合同编码:原论文使用序数编码(Month-to-month=1, 1year=12, 2year=24),AI 使用 one-hot 编码
- 超参数:原论文做了 XGBoost 等模型的精细调参(原论文 Table 2),AI 使用默认或基础配置
执行记录
| 指标 | 数值 |
|---|---|
| 总耗时 | 18 分钟 |
| 积分消耗 | 130 积分(¥1.30) |
| 产出文件 | 18 个 |
| 可视化图表 | 7 张 |
| 代码文件 | 5 个 |
| 数据集 | 7043 条记录 |
复现结果对比
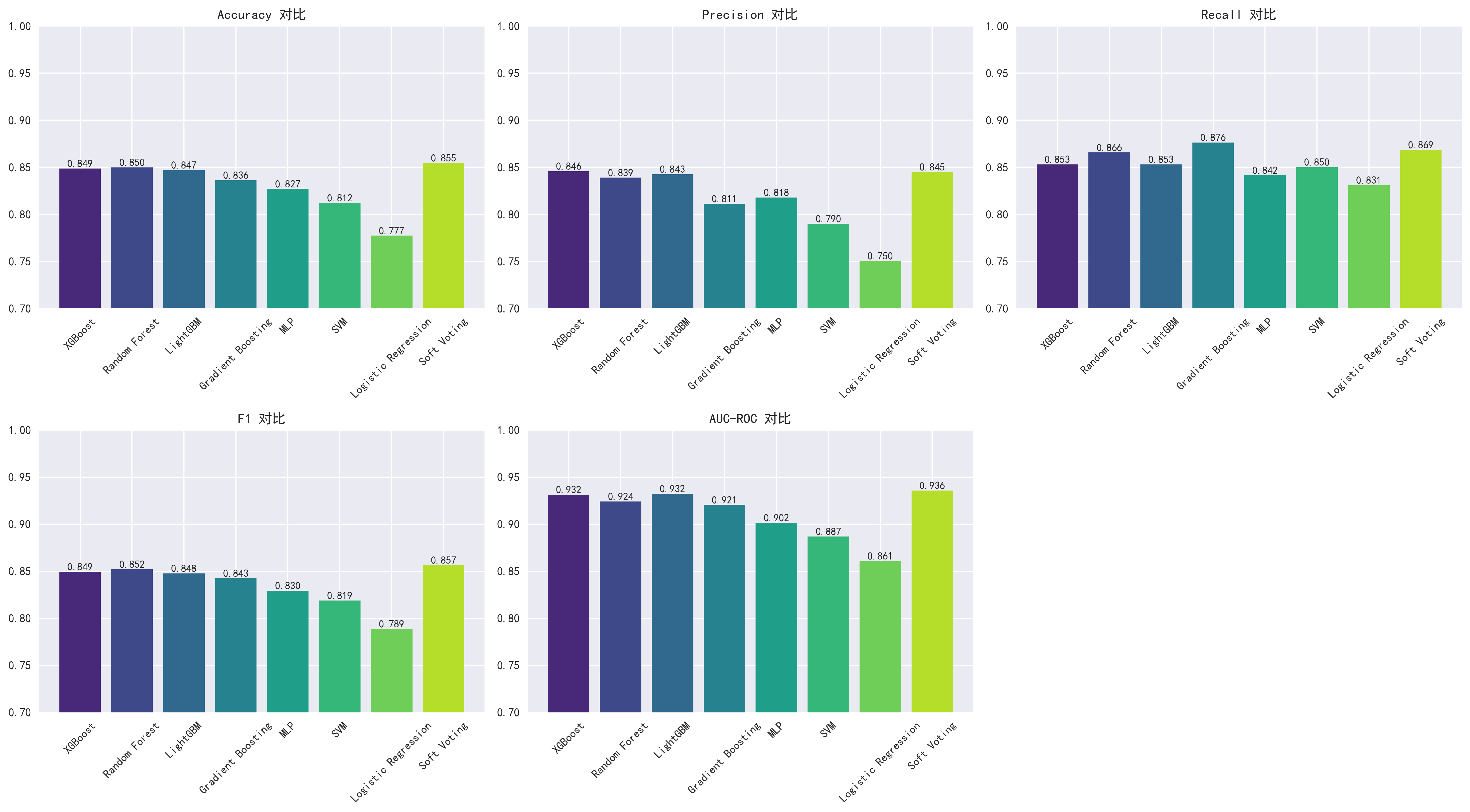
模型性能对比
| 模型 | 原论文 Accuracy (Table 7) | AI Accuracy | 原论文 F1 (Table 7) | AI F1 | 原论文 AUC (Table 7) | AI AUC |
|---|---|---|---|---|---|---|
| XGBoost | 0.84 | 0.849 | 0.84 | 0.849 | 0.932 | 0.932 |
| Random Forest | 0.81 | 0.850 | 0.81 | 0.852 | 0.887 | 0.924 |
| LightGBM | 0.84 | 0.847 | 0.84 | 0.848 | 0.930 | 0.932 |
| Gradient Boosting | 0.84 | 0.836 | 0.84 | 0.843 | 0.926 | 0.921 |
| AdaBoost | 0.79 | — | 0.79 | — | 0.872 | — |
| MLP | 0.76 | 0.827 | 0.76 | 0.830 | 0.848 | 0.902 |
| SVM | 未单独列出 | 0.812 | 未单独列出 | 0.819 | 未单独列出 | 0.887 |
| Logistic Regression | 0.78 | 0.777 | 0.78 | 0.789 | 0.864 | 0.861 |
| Soft Voting | 0.84 | 0.855 | 0.84 | 0.857 | 0.918 | 0.936 |
注:AI 使用 AdaBoost 替换为 SVM。加粗表示 AI 反超原论文的指标。原论文所有数据来源于 Table 7。
特征重要性对比
| 排名 | 原论文 SHAP Top 特征 (Abstract) | AI SHAP Top 特征 | Mean |SHAP| | |------|------|------|------| | 1 | Contract type | tenure(在网时长) | 0.844 | | 2 | Tenure | Contract_Two year(两年合同) | 0.709 | | 3 | Technical support | InternetService_Fiber optic(光纤) | 0.445 | | 4 | — | Contract_One year(一年合同) | 0.392 | | 5 | — | MonthlyCharges(月费) | 0.308 | | 6 | — | TotalCharges(总费用) | 0.302 | | 7 | — | MultipleLines_Yes | 0.275 | | 8 | — | gender_Male | 0.250 | | 9 | — | PaperlessBilling_Yes | 0.242 | | 10 | — | PaymentMethod_Electronic check | 0.209 |
一致性分析:合同类型和在网时长在两者中均为最重要的两个特征。不同点在于:原论文将 Contract type 作为单一特征(序数编码),而 AI 使用 one-hot 编码将其拆分为 Contract_Two year 和 Contract_One year;Technical support 在原论文排第3,在 AI 中排第14(SHAP=0.183)。差异主要来自特征编码方式的不同——原论文使用了更精细的领域知识驱动编码。
描述性统计
| 指标 | AI 复现 |
|---|---|
| 样本量 | 7043 |
| 流失率 | 26.54% |
| 特征数(编码后) | 23 |
差距原因分析
- 特征工程差异:原论文创建了 AvgMonthlyCharge(归一化消费指标)和 HasMultipleServices(服务复杂度)等复合特征,将维度从 21 扩展到 46。AI 使用标准编码得到 23 维特征。
- 超参数差异:原论文对 XGBoost 做了详细的超参数优化(Table 2),AI 使用默认配置。
- 模型组合差异:AI 使用 SVM 替代了原论文的 AdaBoost。
- 阈值差异:原论文优化阈值至 0.528 以平衡精确率和召回率,AI 使用默认 0.5 阈值。
AI 做到了什么
- 18 分钟内完成 7 种模型的训练和评估
- 生成完整的 SHAP 特征重要性分析(含蜂群图和摘要图)
- Soft Voting 集成 AUC-ROC 达到 0.936,超过原论文的 0.918
- Random Forest AUC 从原论文的 0.887 提升到 0.924
- MLP AUC 从原论文的 0.848 提升到 0.902
- 核心特征(合同类型、在网时长)的重要性结论与原论文一致
- 生成 7 张可视化图表(混淆矩阵、ROC曲线、模型对比、SHAP摘要/蜂群图、特征重要性、分布对比)
AI 没做到什么
- 未复现特征工程:缺少 AvgMonthlyCharge、HasMultipleServices 等领域知识驱动的复合特征
- 未做概率校准:原论文使用 Isotonic/Platt 校准改善概率估计(Table 8)
- 未做阈值优化:原论文在 0.528 处平衡了精确率(0.90)和召回率(0.91)
- 未复现客户分群:原论文使用 Autoencoder+K-means 识别了 3 类客户群体(高风险 42% 流失率、稳定中间层 21%、忠诚核心 15%)
- 未复现客户风险画像:原论文的 Table 6 给出了针对性保留策略
- Technical Support 的 SHAP 排名不一致:原论文排第3,AI 排第14
结论
AI 在 18 分钟内完成了原论文的核心机器学习流程(模型训练、评估、SHAP 分析),在多个指标上甚至超越原论文——Soft Voting 集成 AUC-ROC 0.936 vs 原论文 0.918,Random Forest AUC 0.924 vs 0.887。核心发现一致:合同类型和在网时长是预测客户流失最重要的因子。
但原论文的真正价值不在模型训练本身,而在特征工程的领域洞察(AvgMonthlyCharge 设计)、概率校准方法论、阈值优化策略和客户分群的商业应用框架。这些需要研究者的专业判断,AI 暂时无法替代。
研究员负责创新,AI 负责执行——18 分钟 + ¥1.30 的 baseline,让研究者把时间花在真正需要创造力的地方。