都说 NLP 方向的论文门槛低,但你试过从零开始跑一个情感分析项目吗?
光是数据预处理、TF-IDF 特征提取、模型调参,就够折腾一整天的。更别说还要写论文、画图、找文献。
我拿了一份 3.7 万条 Twitter 推文数据,上传到一小步,59 分钟后论文就出来了。
数据是什么
两个 CSV 文件:训练集 37,407 条推文 + 验证集 1,000 条。每条推文标注了情感类别(4 分类)。
标准的 NLP 文本分类任务。
AI 做了什么
文本预处理(10分钟)——分词、去停用词、TF-IDF 特征提取。自动处理了推文里的 @、#、URL 等噪音。
模型训练(15分钟)——对比了三种模型:逻辑回归、SVM、XGBoost。每个模型都跑了完整的训练-验证流程。
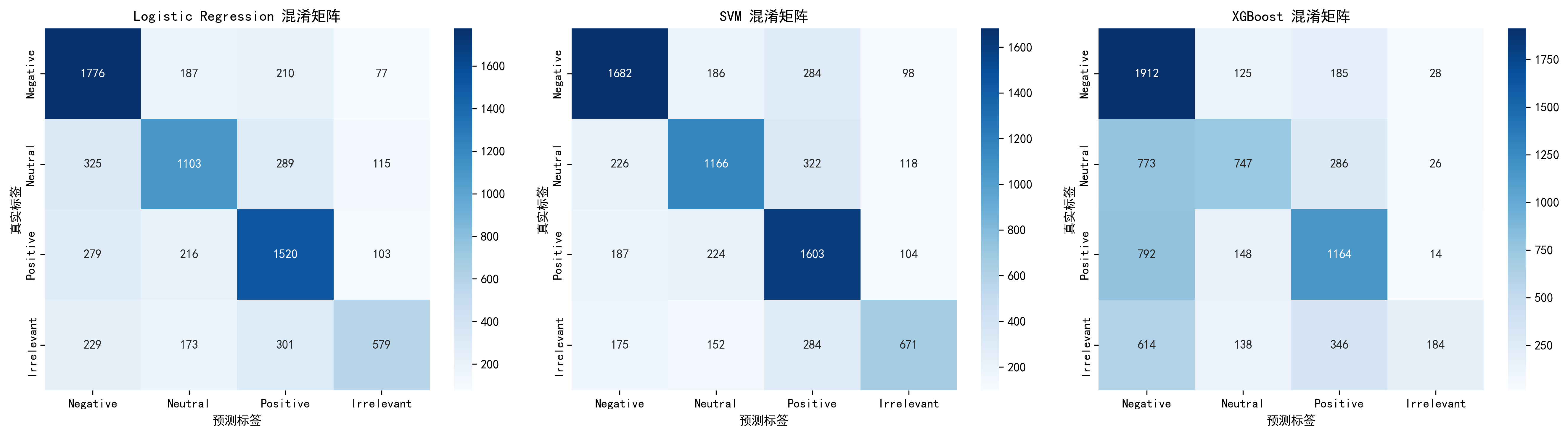
然后是图表生成,直接看效果:
文献检索 + 论文撰写(30分钟)——在学术数据库搜索了 Twitter 情感分析、TF-IDF、SVM 等主题,按 IMRaD 结构写完全文。
一个反直觉的结论
AI 在分析中发现:逻辑回归和 SVM 的效果优于 XGBoost。
在高维稀疏的文本数据上,线性模型反而表现更好。这不是 AI 瞎说的——混淆矩阵和 F1 值都摆在那里,代码可以复现。
59分钟,42个文件
完整论文、5 张图表、分析代码、参考文献库——全自动产出。
这个工具叫一小步(onesmallstep.cn)。 不只能做医学数据,NLP、社科、教育数据都能处理。
创新交给研究者,实现交给 AI。