研究背景
社交媒体情感分析是自然语言处理的经典应用场景。Twitter 等平台每天产生数以亿计的文本数据,如何高效、准确地对这些文本进行情感分类,是学术界和工业界共同关注的问题。
本案例使用 37,407 条 Twitter 推文(四类情感标注),由 AI 全自动完成了一项模型对比研究。
输入
两个 CSV 文件:
- 训练集:37,407 条推文(10.3 MB)
- 验证集:1,000 条推文(164 KB)
每条推文包含文本内容和情感标签(四分类)。
AI 做了什么
整个过程耗时 59 分钟,59 轮人机交互,自动产出 42 个文件:
1. 文本预处理
- 自动清洗推文噪音(@提及、#话题标签、URL链接)
- 分词与去停用词
- TF-IDF 特征提取
2. 模型训练与对比
- 逻辑回归:线性基线模型
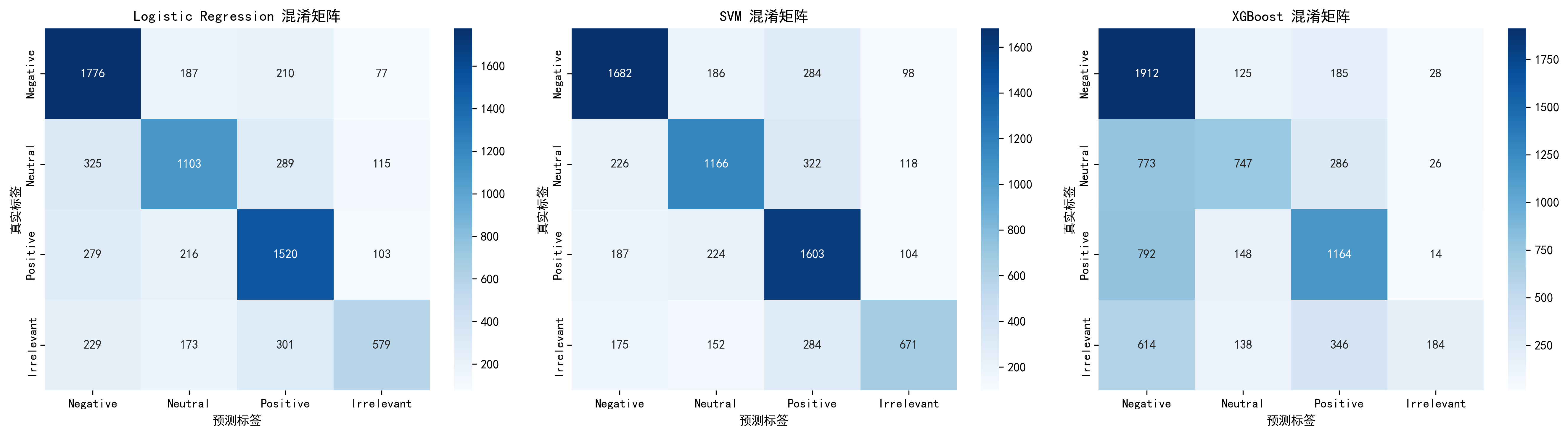
- SVM(支持向量机):高维空间分类
- XGBoost:梯度提升集成方法
3. 图表生成
AI 自动生成了 5 张出版级统计图表:
4. 论文撰写
- 完整 IMRaD 结构论文
- LaTeX 源码 + PDF + Word 三种格式
- 自动检索相关文献,生成参考文献库(33KB .bib 文件)
5. 质量控制
- 对抗性审稿报告
- 数据-文本一致性校验
产出清单
| 类别 | 文件 | 说明 |
|---|---|---|
| 论文 | manuscript.pdf / .docx | 完整论文(793KB PDF) |
| 源码 | 6 个 .tex + references.bib | LaTeX 源码 |
| 图表 | 5 张 .png | 出版级统计图 |
| 分析 | analysis_results.json | 结构化统计结果 |
| 代码 | 5 个 .py | 可复现的分析脚本 |
| 审查 | ADVERSARIAL_REVIEW.md | 对抗性审稿报告 |
关键发现
研究揭示了一个值得关注的现象:
- 逻辑回归和 SVM 优于 XGBoost——在稀疏高维的 TF-IDF 文本特征上,线性模型的分类性能更优
- 这提示在文本分类任务中,模型复杂度并非越高越好
- 四类情感的分类难度不均,某些情感类别的区分度天然较低
这意味着什么
这个案例展示了 AI 在 NLP 和计算社会科学研究中的应用:
- 文本预处理流程全自动化(分词、特征提取、噪音清洗)
- 多模型对比实验无需手动调参
- 每个实验结果都有可复现的代码支撑
创新交给研究者,实现交给 One Small Step。