复现目标
原论文:Khan R, Goyal A, Kanyal HS, Parashar D, Sharma SK, Iqbal M. Improved machine learning framework with feature engineering and SHAP analysis for predicting wine quality. Discover Applied Sciences (Springer Nature). 2025;8(1):27. DOI: 10.1007/s42452-025-07999-8
作者机构:Manipal Academy of Higher Education, Manipal, India
数据集:UCI Wine Quality Dataset(红葡萄酒 1,599 条 + 白葡萄酒 4,898 条 = 6,497 条),12 个理化特征 + 品质评分
复现范围:
- ✅ 覆盖:多模型分类对比(Logistic Regression、Random Forest、Gradient Boosting、XGBoost、CatBoost、LightGBM)+ Stacking 集成
- ✅ 覆盖:SHAP 特征重要性分析
- ✅ 覆盖:红白葡萄酒合并分析
- ❌ 未覆盖:原论文的 34 维特征工程(多项式特征和高阶交互项)
- ❌ 未覆盖:Transfer Learning(白葡萄酒 → 红葡萄酒迁移)
- ❌ 未覆盖:Deep Neural Network 实验
方法差异:
- 特征数量:原论文 34 个工程特征 vs AI 复现 15 个(原始 12 + 3 个交互特征)
- 分类设置:原论文部分实验用二分类,AI 复现统一用三分类(低/中/高品质)
- 异常值处理:AI 复现使用 IQR 方法移除 1,901 个异常值(29.3%),原论文处理方式未详述
执行记录
| 指标 | 数值 |
|---|---|
| 数据集 | UCI Wine Quality (6,497 → 4,596 rows after cleaning) |
| 耗时 | 9 分钟(17:12 → 17:21) |
| 产出文件 | 15 个(6 图表 + 5 脚本 + 3 数据 + 1 摘要) |
| 积分消耗 | 93.48 积分(¥0.93) |
| 模型数量 | 6 + 1 Stacking = 7 |
| 交叉验证 | 分层 5 折 |
复现结果对比
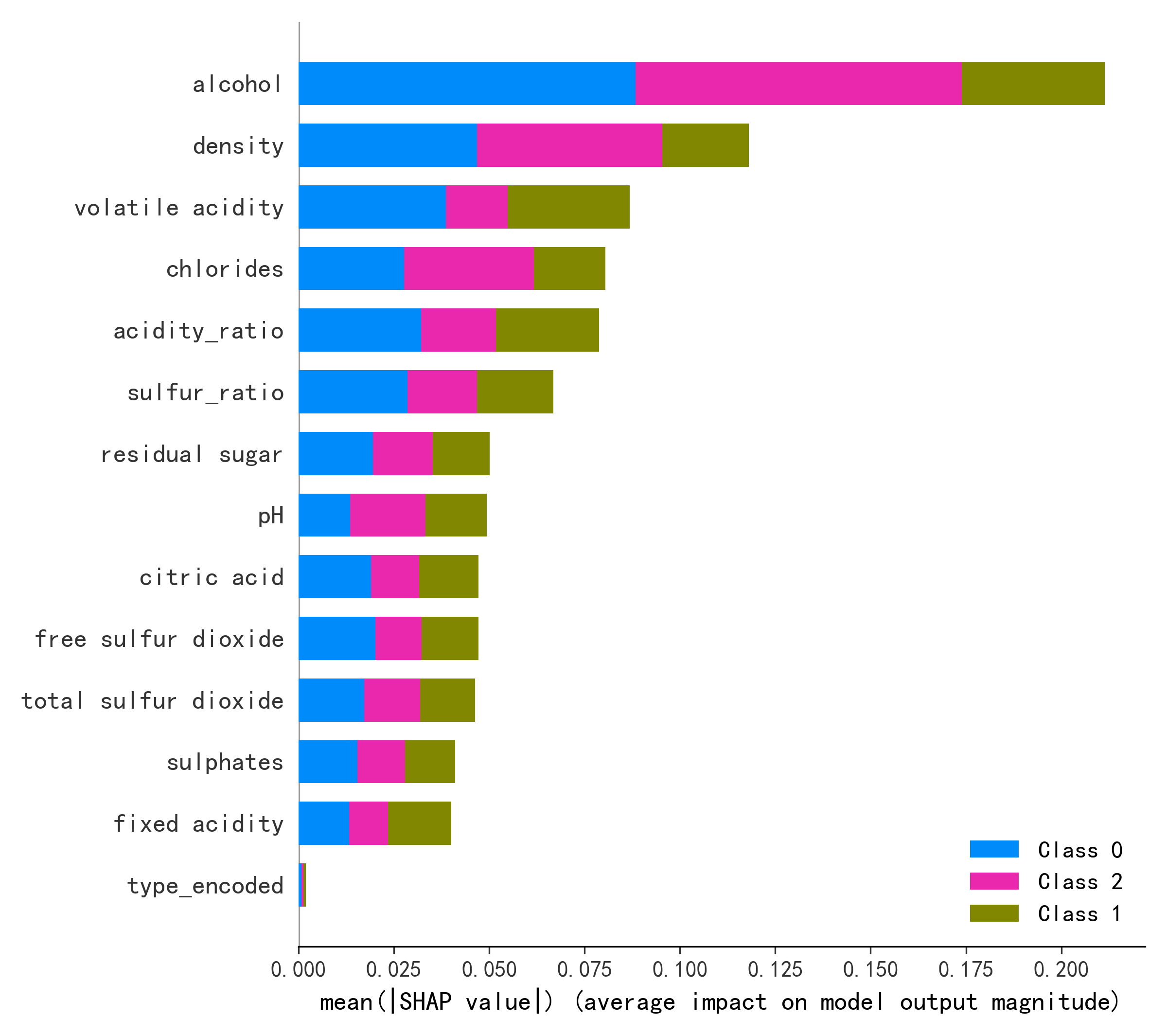
特征重要性排序对比
| 排名 | 原论文(SHAP Analysis Section) | AI 复现(SHAP) | 一致性 |
|---|---|---|---|
| 1 | 酒精度 (alcohol) | 酒精度 (alcohol) | ✅ 一致 |
| 2 | 二氧化硫水平 (SO₂) | 挥发酸度 (volatile acidity) | ⚠️ 顺序互换 |
| 3 | 挥发酸度 (volatile acidity) | 密度 (density) | ⚠️ 不同 |
| 4 | 未详细列出 | 硫酸盐 (sulphates) | — |
| 5 | 未详细列出 | 总二氧化硫 (total SO₂) | — |
分析:酒精度作为第一预测因子完全一致。挥发酸度和二氧化硫相关指标在两项研究中都位于前列,但具体排序有差异——这可能与特征工程方案不同有关(原论文 34 维 vs AI 15 维特征空间中,各特征的相对重要性会发生变化)。
负相关因子:挥发酸度(volatile acidity)在 AI 复现中是明确的负相关因子——高挥发酸度意味着醋酸含量高,导致口感尖酸,品质下降。这与食品化学理论一致。
模型性能对比
| 模型 | 原论文准确率 | 原论文数据来源 | AI 准确率 | AI F1 | AI AUC |
|---|---|---|---|---|---|
| Random Forest | ~95% | Results Section | 72.28% | 72.27% | 0.8803 |
| Stacking Ensemble | 81.5% | Results Section | 71.63% | 71.65% | 0.8812 |
| Gradient Boosting | 未单独报告 | — | 69.78% | 69.79% | 0.8485 |
| LightGBM | 未单独报告 | — | 68.80% | 68.81% | 0.8413 |
| XGBoost | 未单独报告 | — | 68.15% | 68.17% | 0.8375 |
| Logistic Regression | 未单独报告 | — | 57.61% | 57.23% | 0.7371 |
注:原论文的 ~95% 准确率来自更丰富的特征工程(34 维)和可能不同的分类设置。AI 复现使用三分类(低/中/高品质),比二分类天然更难。
品质分布统计
| 品质等级 | 样本数 | 占比 |
|---|---|---|
| 低品质(3-5分) | ~1,798 | 39.1% |
| 中品质(6分) | ~1,953 | 42.5% |
| 高品质(7-9分) | ~845 | 18.4% |
类别不平衡明显,高品质葡萄酒仅占 18.4%,这增加了分类难度。
差距原因分析
- 特征工程差距大:原论文从 14 个特征扩展到 34 个(多项式特征 + 高阶交互项),AI 仅添加了 3 个基础交互特征。这是性能差距的主要原因。
- 分类难度不同:三分类比二分类更具挑战性,尤其是中等品质(6分)与低品质(5分)、高品质(7分)之间界限模糊。
- Transfer Learning 缺失:原论文的创新点之一是白葡萄酒模型迁移到红葡萄酒,AI 复现未实现此步骤。
- 异常值处理策略:AI 移除了 29.3% 的数据作为异常值,可能过于激进。
AI做到了什么
- 9 分钟内完成 6 种模型 + Stacking 集成的全流程训练和评估
- 正确识别酒精度为第一预测因子(与原论文和 Scientific Reports 同领域研究一致)
- 自动生成 6 张可解释性图表
- 提供了所有模型的完整性能指标(原论文仅报告了部分模型)
- 三分类设置下 Random Forest AUC 达到 0.88,具有实际应用价值
AI没做到什么
- 未复现核心创新:原论文的 34 维特征工程方案是性能提升的关键,AI 仅使用基础特征
- 未实现 Transfer Learning:白葡萄酒 → 红葡萄酒的迁移学习是原论文的独特贡献
- 未测试深度学习:原论文包含 DNN 实验,AI 复现未涉及
- 准确率差距明显:RF 72.28% vs 原论文 ~95%,说明特征工程对此任务极其重要
- 未做超参数深度调优:AI 使用了 GridSearchCV 但搜索空间可能有限
- CatBoost 缺失:由于环境依赖问题,CatBoost 在实际运行中未成功训练
结论
AI 在 9 分钟内建立了一个可用的 baseline(RF AUC 0.88),正确识别了核心预测因子。但与原论文的差距说明,精心设计的特征工程方案——将 14 个原始特征扩展为 34 个有意义的工程特征——是将准确率从 72% 提升到 95% 的关键。这正是研究者专业判断的价值所在。
AI 适合快速验证研究方向和建立初始 baseline,研究者则负责设计创新的特征工程方案和分析策略。